 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntentVLA: Short-Horizon Intent Modeling for Aliased Robot Manipulation
May 14, 2026Robot imitation data are often multimodal: similar visual-language observations may be followed by different action chunks because human demonstrators act with different short-horizon intents, task phases, or recent context. Existing frame-conditioned VLA policies infer each chunk from the current observation and instruction alone, so under partial observability they may resample different intents across adjacent replanning steps, leading to inter-chunk conflict and unstable execution. We introduce IntentVLA, a history-conditioned VLA framework that encodes recent visual observations into a compact short-horizon intent representation and uses it to condition chunk generation. We further introduce AliasBench, a 12-task ambiguity-aware benchmark on RoboTwin2 with matched training data and evaluation environments that isolate short-horizon observation aliasing. Across AliasBench, SimplerEnv, LIBERO, and RoboCasa, IntentVLA improves rollout stability and outperforms strong VLA baselines
DynaSolidGeo: A Dynamic Benchmark for Genuine Spatial Mathematical Reasoning of VLMs in Solid Geometry
Oct 25, 2025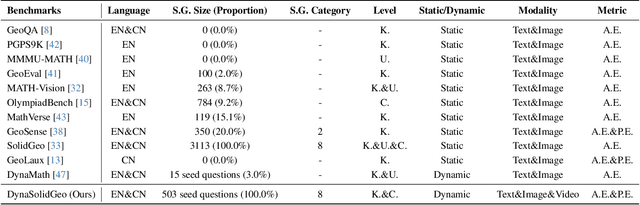
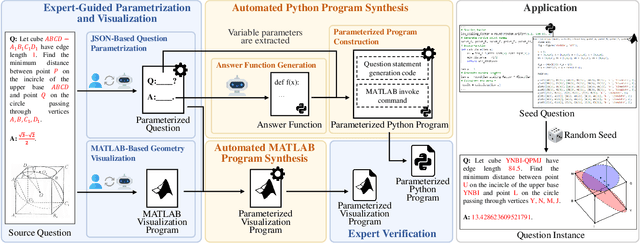
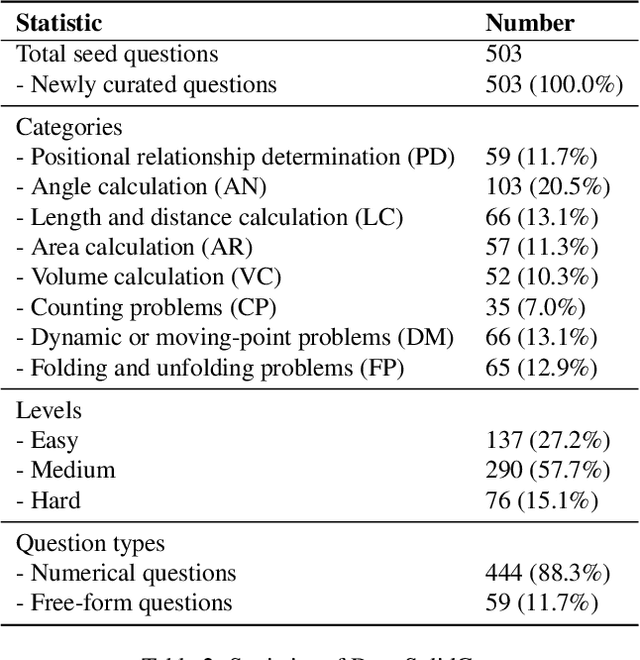
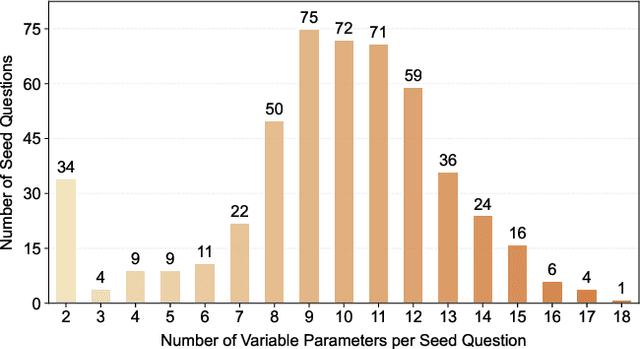
Solid geometry problem solving demands spatial mathematical reasoning that integrates spatial intelligence and symbolic reasoning. However, most existing multimodal mathematical reasoning benchmarks focus primarily on 2D plane geometry, rely on static datasets prone to data contamination and memorization, and evaluate models solely by final answers, overlooking the reasoning process. To address these limitations, we introduce DynaSolidGeo, the first dynamic benchmark for evaluating genuine spatial reasoning in Vision-Language Models (VLMs). Constructed through a semi-automatic annotation pipeline, DynaSolidGeo contains 503 expert-curated seed questions that can, in principle, dynamically generate an unbounded number of diverse multimodal text-visual instances. Beyond answer accuracy, we incorporate process evaluation based on expert-annotated reasoning chains to measure logical validity and causal coherence. Experiments across representative open-source and closed-source VLMs reveal large performance gaps, severe degradation in dynamic settings, and poor performance on tasks requiring high-level spatial intelligence, such as mental rotation and visualization. The code and dataset are available at \href{https://zgca-ai4edu.github.io/DynaSolidGeo/}{DynaSolidGeo}.
MulSMo: Multimodal Stylized Motion Generation by Bidirectional Control Flow
Dec 13, 2024Generating motion sequences conforming to a target style while adhering to the given content prompts requires accommodating both the content and style. In existing methods, the information usually only flows from style to content, which may cause conflict between the style and content, harming the integration. Differently, in this work we build a bidirectional control flow between the style and the content, also adjusting the style towards the content, in which case the style-content collision is alleviated and the dynamics of the style is better preserved in the integration. Moreover, we extend the stylized motion generation from one modality, i.e. the style motion, to multiple modalities including texts and images through contrastive learning, leading to flexible style control on the motion generation. Extensive experiments demonstrate that our method significantly outperforms previous methods across different datasets, while also enabling multimodal signals control. The code of our method will be made publicly available.
Diving into Underwater: Segment Anything Model Guided Underwater Salient Instance Segmentation and A Large-scale Dataset
Jun 10, 2024With the breakthrough of large models, Segment Anything Model (SAM) and its extensions have been attempted to apply in diverse tasks of computer vision. Underwater salient instance segmentation is a foundational and vital step for various underwater vision tasks, which often suffer from low segmentation accuracy due to the complex underwater circumstances and the adaptive ability of models. Moreover, the lack of large-scale datasets with pixel-level salient instance annotations has impeded the development of machine learning techniques in this field. To address these issues, we construct the first large-scale underwater salient instance segmentation dataset (USIS10K), which contains 10,632 underwater images with pixel-level annotations in 7 categories from various underwater scenes. Then, we propose an Underwater Salient Instance Segmentation architecture based on Segment Anything Model (USIS-SAM) specifically for the underwater domain. We devise an Underwater Adaptive Visual Transformer (UA-ViT) encoder to incorporate underwater domain visual prompts into the segmentation network. We further design an out-of-the-box underwater Salient Feature Prompter Generator (SFPG) to automatically generate salient prompters instead of explicitly providing foreground points or boxes as prompts in SAM. Comprehensive experimental results show that our USIS-SAM method can achieve superior performance on USIS10K datasets compared to the state-of-the-art methods. Datasets and codes are released on https://github.com/LiamLian0727/USIS10K.
Revisiting Recursive Least Squares for Training Deep Neural Networks
Sep 07, 2021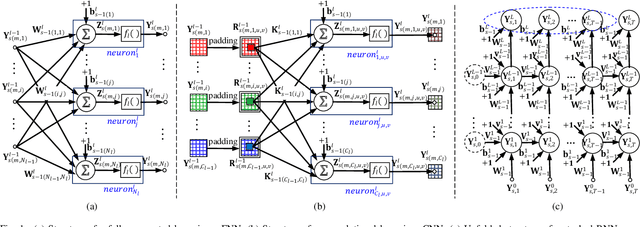
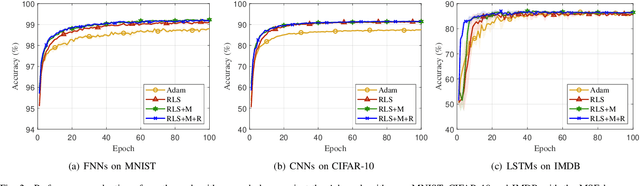
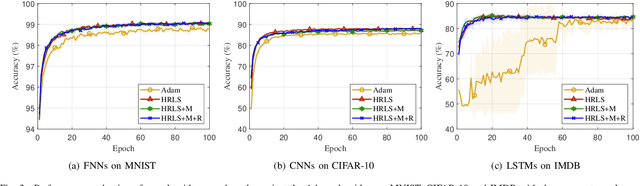
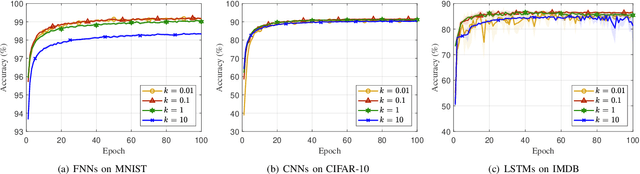
Recursive least squares (RLS) algorithms were once widely used for training small-scale neural networks, due to their fast convergence. However, previous RLS algorithms are unsuitable for training deep neural networks (DNNs), since they have high computational complexity and too many preconditions. In this paper, to overcome these drawbacks, we propose three novel RLS optimization algorithms for training feedforward neural networks, convolutional neural networks and recurrent neural networks (including long short-term memory networks), by using the error backpropagation and our average-approximation RLS method, together with the equivalent gradients of the linear least squares loss function with respect to the linear outputs of hidden layers. Compared with previous RLS optimization algorithms, our algorithms are simple and elegant. They can be viewed as an improved stochastic gradient descent (SGD) algorithm, which uses the inverse autocorrelation matrix of each layer as the adaptive learning rate. Their time and space complexities are only several times those of SGD. They only require the loss function to be the mean squared error and the activation function of the output layer to be invertible. In fact, our algorithms can be also used in combination with other first-order optimization algorithms without requiring these two preconditions. In addition, we present two improved methods for our algorithms. Finally, we demonstrate their effectiveness compared to the Adam algorithm on MNIST, CIFAR-10 and IMDB datasets, and investigate the influences of their hyperparameters experimentally.