 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Recursive Least Squares for Training Deep Neural Networks
Sep 07, 2021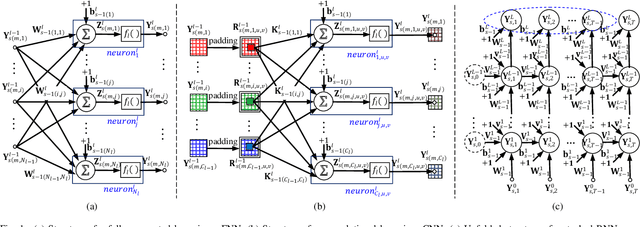
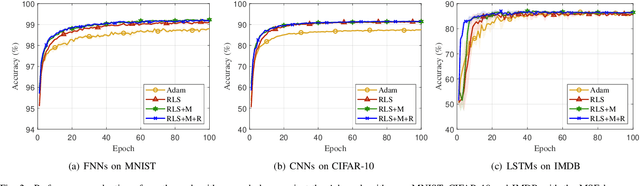
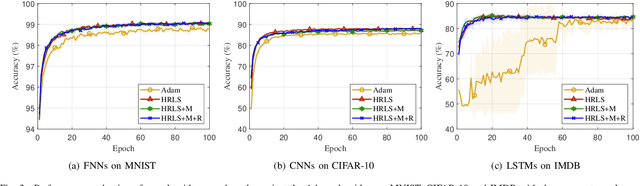
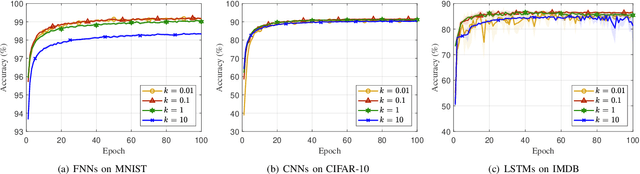
Recursive least squares (RLS) algorithms were once widely used for training small-scale neural networks, due to their fast convergence. However, previous RLS algorithms are unsuitable for training deep neural networks (DNNs), since they have high computational complexity and too many preconditions. In this paper, to overcome these drawbacks, we propose three novel RLS optimization algorithms for training feedforward neural networks, convolutional neural networks and recurrent neural networks (including long short-term memory networks), by using the error backpropagation and our average-approximation RLS method, together with the equivalent gradients of the linear least squares loss function with respect to the linear outputs of hidden layers. Compared with previous RLS optimization algorithms, our algorithms are simple and elegant. They can be viewed as an improved stochastic gradient descent (SGD) algorithm, which uses the inverse autocorrelation matrix of each layer as the adaptive learning rate. Their time and space complexities are only several times those of SGD. They only require the loss function to be the mean squared error and the activation function of the output layer to be invertible. In fact, our algorithms can be also used in combination with other first-order optimization algorithms without requiring these two preconditions. In addition, we present two improved methods for our algorithms. Finally, we demonstrate their effectiveness compared to the Adam algorithm on MNIST, CIFAR-10 and IMDB datasets, and investigate the influences of their hyperparameters experimentally.