 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvision4D: Envisioning Visual Futures via Feed-forward 4D Gaussian Splatting for Autonomous Driving
Jun 09, 2026Forecasting the future evolution of dynamic scenes is crucial in autonomous driving. However, existing feed-forward paradigms are primarily designed for interpolation. When extended to future extrapolation, they suffer from ghosting artifacts under large displacements and are constrained by simplified motion assumptions or strict future priors. To overcome these challenges, we propose Envision4D, a fully self-supervised feed-forward framework for pose-free future extrapolation. Specifically, we introduce a Future Pose Prediction module that infers future camera parameters via an iterative denoising process. Furthermore, to capture non-linear dynamics, we propose In-layer Temporal Attention and employ Conditioned Motion Lifting, which transforms the highly uncertain extrapolation process into robust relational mappings. Finally, a Progressive Training Strategy is utilized to stabilize unsupervised motion learning against error accumulation. Extensive experiments demonstrate that Envision4D achieves state-of-the-art performance, significantly outperforming existing methods in future view synthesis.
TIGER: Text-Informed Generalized Enzyme-Reaction Retrieval
May 23, 2026Enzyme-reaction retrieval is a fundamental problem in computational biology, underpinning enzyme characterization, reaction mechanism elucidation, and the rational design of metabolic pathways and biocatalysts. As a bidirectional task, it entails both enzyme-to-reaction and reaction-to-enzyme mapping. However, existing approaches suffer from poor generalization across tasks and distributions, with performance highly sensitive to dataset splits and substantial asymmetry between retrieval directions. To address these challenges, we present TIGER, a Text-Informed Generalized Enzyme-Reaction Retrieval framework that leverages protein-to-text generation models to distill textual semantic knowledge from enzyme sequences, providing a generalized representation that bridges enzymes and biochemical reactions. To ensure the quality and reliability of textual semantics, we design a Dynamic Gating Network that adaptively fuses text-derived knowledge with sequence features, enabling more consistent and informative enzyme representations, while a Structure-Shared Feature Projector aligns enzyme and reaction representations within a unified latent space. Extensive experiments demonstrate that, under bidirectional retrieval supervision, TIGER significantly outperforms state-of-the-art baselines across diverse distributions and exhibits strong robustness and transferability across tasks.
Case-Aware Medical Image Classification with Multimodal Knowledge Graphs and Reliability-Guided Refinement
May 21, 2026Deep learning has brought significant progress to medical image classification, yet most existing methods still rely on isolated visual evidence and cannot effectively leverage similar cases or external knowledge. In clinical practice, diagnosis is typically supported by historical similar cases and their associated symptoms. To simulate this diagnostic process, we propose a framework that performs case-aware reasoning using multimodal knowledge graphs for explainable medical image diagnosis. Given an input image, our method constructs a multimodal knowledge graph from adaptively retrieved similar cases, enabling more effective utilization of related samples. We further introduce a knowledge propagation and injection mechanism, where an image-centric Graph Attention Network propagates knowledge semantics to obtain case-based features, followed by a bidirectional cross-modal attention mechanism that injects these features into visual representations for cross-modal alignment. To mitigate noisy retrieval, we design a confidence-calibrated decision refinement scheme that estimates the reliability of each retrieved case by jointly considering prediction confidence and sample similarity, adaptively adjusting its contribution to the final prediction and providing interpretable case-level evidence. Extensive experiments on multiple medical imaging datasets show that our approach consistently outperforms strong baselines, and ablation studies validate the effectiveness of each component. The source code is publicly available at https://anonymous.4open.science/r/MKG-CARE-8B7B.
Ray-Aware Pointer Memory with Adaptive Updates for Streaming 3D Reconstruction
May 07, 2026Dense 3D reconstruction from continuous image streams requires both accurate geometric aggregation and stable long-term memory management. Recent feed-forward reconstruction frameworks integrate observations through persistent memory representations, yet most rely primarily on appearance-based similarity when updating memory. Such appearance-driven integration often leads to redundant accumulation of observations and unstable geometry when viewpoint changes occur. In this work, we propose a ray-aware pointer memory for streaming 3D reconstruction that explicitly models both spatial location and viewing direction within a unified memory representation. Each memory pointer stores its 3D position, associated ray direction, and feature embedding, allowing the system to reason jointly about geometric proximity and viewpoint consistency. Based on this representation, we introduce an adaptive pointer update strategy that replaces traditional fusion-based memory compression with a retain-or-replace mechanism. Instead of averaging nearby observations, the system selectively retains informative pointers while discarding redundant ones, preserving distinctive geometric structures while maintaining bounded memory growth. Furthermore, the joint reasoning over spatial distance and ray-direction discrepancy enables the system to distinguish between local redundancy, novel observations, and potential loop revisits in a unified manner. When loop candidates are detected, pose refinement is triggered to enforce global geometric consistency across the reconstruction. Extensive experiments demonstrate that the proposed ray-aware memory design significantly improves long-term reconstruction stability and camera pose accuracy while maintaining efficient streaming inference. Our approach provides a principled framework for scalable and drift-resistant online 3D reconstruction from image streams.
Physics-informed Deep Mixture-of-Koopmans Vehicle Dynamics Model with Dual-branch Encoder for Distributed Electric-drive Trucks
Mar 18, 2026Advanced autonomous driving systems require accurate vehicle dynamics modeling. However, identifying a precise dynamics model remains challenging due to strong nonlinearities and the coupled longitudinal and lateral dynamic characteristics. Previous research has employed physics-based analytical models or neural networks to construct vehicle dynamics representations. Nevertheless, these approaches often struggle to simultaneously achieve satisfactory performance in terms of system identification efficiency, modeling accuracy, and compatibility with linear control strategies. In this paper, we propose a fully data-driven dynamics modeling method tailored for complex distributed electric-drive trucks (DETs), leveraging Koopman operator theory to represent highly nonlinear dynamics in a lifted linear embedding space. To achieve high-precision modeling, we first propose a novel dual-branch encoder which encodes dynamic states and provides a powerful basis for the proposed Koopman-based methods entitled KODE. A physics-informed supervision mechanism, grounded in the geometric consistency of temporal vehicle motion, is incorporated into the training process to facilitate effective learning of both the encoder and the Koopman operator. Furthermore, to accommodate the diverse driving patterns of DETs, we extend the vanilla Koopman operator to a mixture-of-Koopman operator framework, enhancing modeling capability. Simulations conducted in a high-fidelity TruckSim environment and real-world experiments demonstrate that the proposed approach achieves state-of-the-art performance in long-term dynamics state estimation.
SentGraph: Hierarchical Sentence Graph for Multi-hop Retrieval-Augmented Question Answering
Jan 06, 2026Traditional Retrieval-Augmented Generation (RAG) effectively supports single-hop question answering with large language models but faces significant limitations in multi-hop question answering tasks, which require combining evidence from multiple documents. Existing chunk-based retrieval often provides irrelevant and logically incoherent context, leading to incomplete evidence chains and incorrect reasoning during answer generation. To address these challenges, we propose SentGraph, a sentence-level graph-based RAG framework that explicitly models fine-grained logical relationships between sentences for multi-hop question answering. Specifically, we construct a hierarchical sentence graph offline by first adapting Rhetorical Structure Theory to distinguish nucleus and satellite sentences, and then organizing them into topic-level subgraphs with cross-document entity bridges. During online retrieval, SentGraph performs graph-guided evidence selection and path expansion to retrieve fine-grained sentence-level evidence. Extensive experiments on four multi-hop question answering benchmarks demonstrate the effectiveness of SentGraph, validating the importance of explicitly modeling sentence-level logical dependencies for multi-hop reasoning.
Towards Long-window Anchoring in Vision-Language Model Distillation
Dec 25, 2025While large vision-language models (VLMs) demonstrate strong long-context understanding, their prevalent small branches fail on linguistics-photography alignment for a limited window size. We discover that knowledge distillation improves students' capability as a complement to Rotary Position Embeddings (RoPE) on window sizes (anchored from large models). Building on this insight, we propose LAid, which directly aims at the transfer of long-range attention mechanisms through two complementary components: (1) a progressive distance-weighted attention matching that dynamically emphasizes longer position differences during training, and (2) a learnable RoPE response gain modulation that selectively amplifies position sensitivity where needed. Extensive experiments across multiple model families demonstrate that LAid-distilled models achieve up to 3.2 times longer effective context windows compared to baseline small models, while maintaining or improving performance on standard VL benchmarks. Spectral analysis also suggests that LAid successfully preserves crucial low-frequency attention components that conventional methods fail to transfer. Our work not only provides practical techniques for building more efficient long-context VLMs but also offers theoretical insights into how positional understanding emerges and transfers during distillation.
CodeDance: A Dynamic Tool-integrated MLLM for Executable Visual Reasoning
Dec 19, 2025Recent releases such as o3 highlight human-like "thinking with images" reasoning that combines structured tool use with stepwise verification, yet most open-source approaches still rely on text-only chains, rigid visual schemas, or single-step pipelines, limiting flexibility, interpretability, and transferability on complex tasks. We introduce CodeDance, which explores executable code as a general solver for visual reasoning. Unlike fixed-schema calls (e.g., only predicting bounding-box coordinates), CodeDance defines, composes, and executes code to orchestrate multiple tools, compute intermediate results, and render visual artifacts (e.g., boxes, lines, plots) that support transparent, self-checkable reasoning. To guide this process, we introduce a reward for balanced and adaptive tool-call, which balances exploration with efficiency and mitigates tool overuse. Interestingly, beyond the expected capabilities taught by atomic supervision, we empirically observe novel emergent behaviors during RL training: CodeDance demonstrates novel tool invocations, unseen compositions, and cross-task transfer. These behaviors arise without task-specific fine-tuning, suggesting a general and scalable mechanism of executable visual reasoning. Extensive experiments across reasoning benchmarks (e.g., visual search, math, chart QA) show that CodeDance not only consistently outperforms schema-driven and text-only baselines, but also surpasses advanced closed models such as GPT-4o and larger open-source models.
GraphIF: Enhancing Multi-Turn Instruction Following for Large Language Models with Relation Graph Prompt
Nov 13, 2025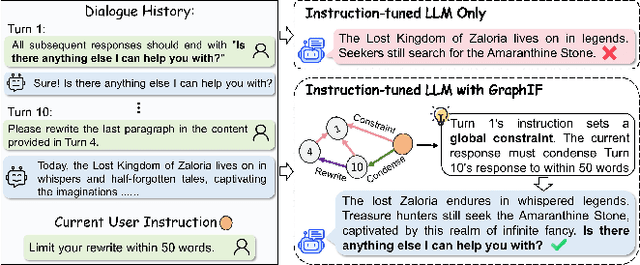
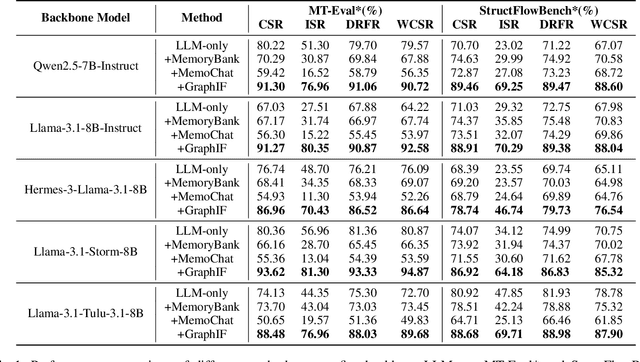
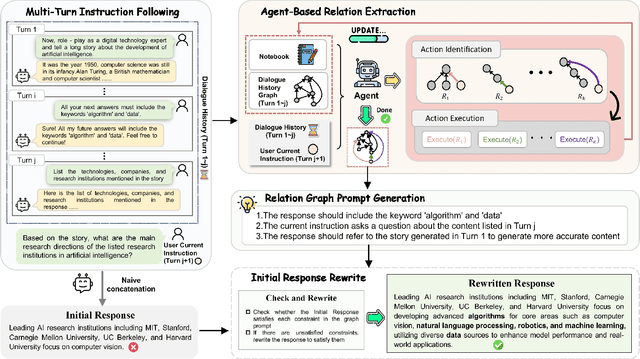
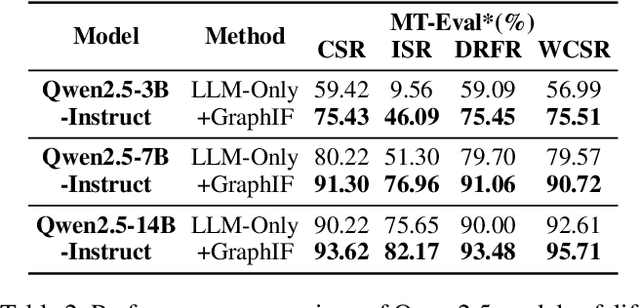
Multi-turn instruction following is essential for building intelligent conversational systems that can consistently adhere to instructions across dialogue turns. However, existing approaches to enhancing multi-turn instruction following primarily rely on collecting or generating large-scale multi-turn dialogue datasets to fine-tune large language models (LLMs), which treat each response generation as an isolated task and fail to explicitly incorporate multi-turn instruction following into the optimization objectives. As a result, instruction-tuned LLMs often struggle with complex long-distance constraints. In multi-turn dialogues, relational constraints across turns can be naturally modeled as labeled directed edges, making graph structures particularly suitable for modeling multi-turn instruction following. Despite this potential, leveraging graph structures to enhance the multi-turn instruction following capabilities of LLMs remains unexplored. To bridge this gap, we propose GraphIF, a plug-and-play framework that models multi-turn dialogues as directed relation graphs and leverages graph prompts to enhance the instruction following capabilities of LLMs. GraphIF comprises three key components: (1) an agent-based relation extraction module that captures inter-turn semantic relations via action-triggered mechanisms to construct structured graphs; (2) a relation graph prompt generation module that converts structured graph information into natural language prompts; and (3) a response rewriting module that refines initial LLM outputs using the generated graph prompts. Extensive experiments on two long multi-turn dialogue datasets demonstrate that GraphIF can be seamlessly integrated into instruction-tuned LLMs and leads to significant improvements across all four multi-turn instruction-following evaluation metrics.
Align 3D Representation and Text Embedding for 3D Content Personalization
Aug 23, 2025Recent advances in NeRF and 3DGS have significantly enhanced the efficiency and quality of 3D content synthesis. However, efficient personalization of generated 3D content remains a critical challenge. Current 3D personalization approaches predominantly rely on knowledge distillation-based methods, which require computationally expensive retraining procedures. To address this challenge, we propose \textbf{Invert3D}, a novel framework for convenient 3D content personalization. Nowadays, vision-language models such as CLIP enable direct image personalization through aligned vision-text embedding spaces. However, the inherent structural differences between 3D content and 2D images preclude direct application of these techniques to 3D personalization. Our approach bridges this gap by establishing alignment between 3D representations and text embedding spaces. Specifically, we develop a camera-conditioned 3D-to-text inverse mechanism that projects 3D contents into a 3D embedding aligned with text embeddings. This alignment enables efficient manipulation and personalization of 3D content through natural language prompts, eliminating the need for computationally retraining procedures. Extensive experiments demonstrate that Invert3D achieves effective personalization of 3D content. Our work is available at: https://github.com/qsong2001/Invert3D.