 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent-Induced Spatial-Spectral Aggregation Network for Change Detection in Remote Sensing Images
Jun 09, 2026The integration of spatial and spectral information is beneficial to the improvement of change detection performance. However, existing methods cannot efficiently suppress the influences of spatial and spectral differences in unchanged areas. To address these issues, in this paper we propose a content-guided spatial-spectral integration network (CSI-Net) for the fusion of global spatial details and spectral difference information. Specifically, the proposed CSI-Net is composed of a spatial reasoning (SR) module, a spectral difference (SD) module, and a content-guided integration (CGI) module. In the SR module, the spatial information is learned by cascaded graph convolution blocks for global modeling. The SD module is responsible for the extraction of spectral features, by calculating the means and variances of features to reduce the impact of spectral differences in unchanged regions. In addition, in order to integrate the spatial-spectral features efficiently, we design a CGI module to further take advantage of their complementary information. In this module, high-level content information is introduced as a guide for a proper interaction. Due to the efficient spatial-spectral fusion, the proposed CSI-Net can learn the changed features better while achieving a suppression of spectral differences. Experimental results on LEVIR-CD, WHU-CD, and CLCD datasets demonstrate that the proposed CSI-Net produces better performance compared to state-of-the-art methods, and is applicable to different scenarios
Building Change Detection in Earthquake: A Multi-Scale Interaction Network and A Change Detection Dataset
Jun 09, 2026As one of the most destructive natural disasters, earthquakes have struck many countries around the world in recent years, causing serious economic losses. Change detection (CD) can be applied to post-earthquake damage assessment as it can infer destroyed change regions from multi-temporal remote sensing images. Furthermore, the CD with short imaging interval will better satisfy the needs of the emergency rescues after earthquakes. However, the capability of current methods built on deep neural networks is limited because the dataset with short imaging interval is absent. To meet post-disaster immediate relief, we create a CD dataset, Turkey earthquake CD dataset (TUE-CD), for the evaluation of building damage in the short term after an earthquake. Because of the short acquisition interval of the post-event images, the imaging angle is different for different temporal images, which leads to some side-looking problems. To deal with these challenges, we present a multi-scale feature interaction network (MSI-Net) for efficient interaction between bi-temporal features, as well as mitigating the effect of side-looking problems. Specifically, the proposed MSI-Net consists of joint cross-attention (JCA) modules, multi-scale offset calibration (MOC) modules, and feature integration (FeI) modules. The JCA module unifies channel cross-attention and spatial joint attention for sufficient feature interaction. The MOC module further estimates the offsets to align the bi-temporal image with the multi-scale features. Finally, calibrated features and multi-scale features are fused by FeI modules for the prediction of changed areas. Experiments on the WHU-CD, CLCD, and the constructed TUE-CD dataset indicate that the proposed MSI-Net provides better results than considered state-of-the-art CD methods.
FMRFusion: Frequency-Aware Multi-View Representation Learning for Heterogeneous Image Fusion
Jun 06, 2026Infrared and visible image fusion aims to generate a composite image that retains significant target information and preserves detailed textures, integrating two heterogeneous modalities. Previous image fusion methods typically adopt a single-module stacking approach to extract features from the two modalities. However, these approaches may result in incomplete learning of their distinct characteristics, thereby limiting the fusion effectiveness and constrain ing robustness in real-world heterogeneous data scenarios. To address these challenges, we propose FMRFusion, a frequency-aware multi-view representation learning network for Heterogeneous Image Fusion. A Multi-Scale Struc tural Perception Module is introduced to effectively capture discriminative structures, extracting fine-grained local structures and essential contextual information. A bilinear frequency decomposition mechanism is employed to sepa rate features into high-frequency and low-frequency components, enabling joint modeling of local details and global representations across different frequency domains. Moreover, a Cross-View Complementary Interaction is incorpo rated to explicitly model and fuse the complementary characteristics between reflected light information and radiative intensity responses, facilitating effective cross-view interaction. We further improve the Performance of the fused results by flow matching, which progressively refines the fused features by learning the transformation from coarse data to high-quality representations. Extensive experiments conducted on multiple benchmark datasets demonstrate that FMRFusion achieves superior and consistent performance across a range of fusion tasks, especially in nighttime scenarios
From Pixels to Predicates Structuring urban perception with scene graphs
Dec 22, 2025Perception research is increasingly modelled using streetscapes, yet many approaches still rely on pixel features or object co-occurrence statistics, overlooking the explicit relations that shape human perception. This study proposes a three stage pipeline that transforms street view imagery (SVI) into structured representations for predicting six perceptual indicators. In the first stage, each image is parsed using an open-set Panoptic Scene Graph model (OpenPSG) to extract object predicate object triplets. In the second stage, compact scene-level embeddings are learned through a heterogeneous graph autoencoder (GraphMAE). In the third stage, a neural network predicts perception scores from these embeddings. We evaluate the proposed approach against image-only baselines in terms of accuracy, precision, and cross-city generalization. Results indicate that (i) our approach improves perception prediction accuracy by an average of 26% over baseline models, and (ii) maintains strong generalization performance in cross-city prediction tasks. Additionally, the structured representation clarifies which relational patterns contribute to lower perception scores in urban scenes, such as graffiti on wall and car parked on sidewalk. Overall, this study demonstrates that graph-based structure provides expressive, generalizable, and interpretable signals for modelling urban perception, advancing human-centric and context-aware urban analytics.
CrossLinear: Plug-and-Play Cross-Correlation Embedding for Time Series Forecasting with Exogenous Variables
May 29, 2025Time series forecasting with exogenous variables is a critical emerging paradigm that presents unique challenges in modeling dependencies between variables. Traditional models often struggle to differentiate between endogenous and exogenous variables, leading to inefficiencies and overfitting. In this paper, we introduce CrossLinear, a novel Linear-based forecasting model that addresses these challenges by incorporating a plug-and-play cross-correlation embedding module. This lightweight module captures the dependencies between variables with minimal computational cost and seamlessly integrates into existing neural networks. Specifically, it captures time-invariant and direct variable dependencies while disregarding time-varying or indirect dependencies, thereby mitigating the risk of overfitting in dependency modeling and contributing to consistent performance improvements. Furthermore, CrossLinear employs patch-wise processing and a global linear head to effectively capture both short-term and long-term temporal dependencies, further improving its forecasting precision. Extensive experiments on 12 real-world datasets demonstrate that CrossLinear achieves superior performance in both short-term and long-term forecasting tasks. The ablation study underscores the effectiveness of the cross-correlation embedding module. Additionally, the generalizability of this module makes it a valuable plug-in for various forecasting tasks across different domains. Codes are available at https://github.com/mumiao2000/CrossLinear.
Integration of nested cross-validation, automated hyperparameter optimization, high-performance computing to reduce and quantify the variance of test performance estimation of deep learning models
Mar 11, 2025The variability and biases in the real-world performance benchmarking of deep learning models for medical imaging compromise their trustworthiness for real-world deployment. The common approach of holding out a single fixed test set fails to quantify the variance in the estimation of test performance metrics. This study introduces NACHOS (Nested and Automated Cross-validation and Hyperparameter Optimization using Supercomputing) to reduce and quantify the variance of test performance metrics of deep learning models. NACHOS integrates Nested Cross-Validation (NCV) and Automated Hyperparameter Optimization (AHPO) within a parallelized high-performance computing (HPC) framework. NACHOS was demonstrated on a chest X-ray repository and an Optical Coherence Tomography (OCT) dataset under multiple data partitioning schemes. Beyond performance estimation, DACHOS (Deployment with Automated Cross-validation and Hyperparameter Optimization using Supercomputing) is introduced to leverage AHPO and cross-validation to build the final model on the full dataset, improving expected deployment performance. The findings underscore the importance of NCV in quantifying and reducing estimation variance, AHPO in optimizing hyperparameters consistently across test folds, and HPC in ensuring computational feasibility. By integrating these methodologies, NACHOS and DACHOS provide a scalable, reproducible, and trustworthy framework for DL model evaluation and deployment in medical imaging.
Learning Task-relevant Sequence Representations via Intrinsic Dynamics Characteristics in Reinforcement Learning
May 30, 2024Learning task-relevant state representations is crucial to solving the problem of scene generalization in visual deep reinforcement learning. Prior work typically establishes a self-supervised auxiliary learner, introducing elements (e.g., rewards and actions) to extract task-relevant state information from observations through behavioral similarity metrics. However, the methods often ignore the inherent relationships between the elements (e.g., dynamics relationships) that are essential for learning accurate representations, and they are also limited to single-step metrics, which impedes the discrimination of short-term similar task/behavior information in long-term dynamics transitions. To solve the issues, we propose an intrinsic dynamic characteristics-driven sequence representation learning method (DSR) over a common DRL frame. Concretely, inspired by the fact of state transition in the underlying system, it constrains the optimization of the encoder via modeling the dynamics equations related to the state transition, which prompts the latent encoding information to satisfy the state transition process and thereby distinguishes state space and noise space. Further, to refine the ability of encoding similar tasks based on dynamics constraints, DSR also sequentially models inherent dynamics equation relationships from the perspective of sequence elements' frequency domain and multi-step prediction. Finally, experimental results show that DSR has achieved a significant performance boost in the Distracting DMControl Benchmark, with an average of 78.9% over the backbone baseline. Further results indicate that it also achieves the best performance in real-world autonomous driving tasks in the CARLA simulator. Moreover, the qualitative analysis results of t-SNE visualization validate that our method possesses superior representation ability on visual tasks.
Episodic Reinforcement Learning with Expanded State-reward Space
Jan 19, 2024Empowered by deep neural networks, deep reinforcement learning (DRL) has demonstrated tremendous empirical successes in various domains, including games, health care, and autonomous driving. Despite these advancements, DRL is still identified as data-inefficient as effective policies demand vast numbers of environmental samples. Recently, episodic control (EC)-based model-free DRL methods enable sample efficiency by recalling past experiences from episodic memory. However, existing EC-based methods suffer from the limitation of potential misalignment between the state and reward spaces for neglecting the utilization of (past) retrieval states with extensive information, which probably causes inaccurate value estimation and degraded policy performance. To tackle this issue, we introduce an efficient EC-based DRL framework with expanded state-reward space, where the expanded states used as the input and the expanded rewards used in the training both contain historical and current information. To be specific, we reuse the historical states retrieved by EC as part of the input states and integrate the retrieved MC-returns into the immediate reward in each interactive transition. As a result, our method is able to simultaneously achieve the full utilization of retrieval information and the better evaluation of state values by a Temporal Difference (TD) loss. Empirical results on challenging Box2d and Mujoco tasks demonstrate the superiority of our method over a recent sibling method and common baselines. Further, we also verify our method's effectiveness in alleviating Q-value overestimation by additional experiments of Q-value comparison.
Sequential Action-Induced Invariant Representation for Reinforcement Learning
Sep 22, 2023How to accurately learn task-relevant state representations from high-dimensional observations with visual distractions is a realistic and challenging problem in visual reinforcement learning. Recently, unsupervised representation learning methods based on bisimulation metrics, contrast, prediction, and reconstruction have shown the ability for task-relevant information extraction. However, due to the lack of appropriate mechanisms for the extraction of task information in the prediction, contrast, and reconstruction-related approaches and the limitations of bisimulation-related methods in domains with sparse rewards, it is still difficult for these methods to be effectively extended to environments with distractions. To alleviate these problems, in the paper, the action sequences, which contain task-intensive signals, are incorporated into representation learning. Specifically, we propose a Sequential Action--induced invariant Representation (SAR) method, in which the encoder is optimized by an auxiliary learner to only preserve the components that follow the control signals of sequential actions, so the agent can be induced to learn the robust representation against distractions. We conduct extensive experiments on the DeepMind Control suite tasks with distractions while achieving the best performance over strong baselines. We also demonstrate the effectiveness of our method at disregarding task-irrelevant information by deploying SAR to real-world CARLA-based autonomous driving with natural distractions. Finally, we provide the analysis results of generalization drawn from the generalization decay and t-SNE visualization. Code and demo videos are available at https://github.com/DMU-XMU/SAR.git.
Online Learning and Planning in Partially Observable Domains without Prior Knowledge
Jun 11, 2019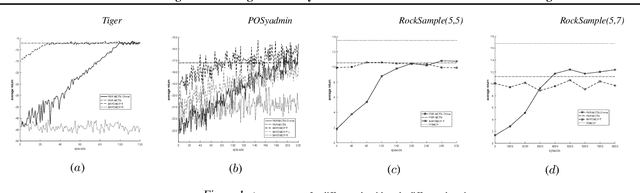
How an agent can act optimally in stochastic, partially observable domains is a challenge problem, the standard approach to address this issue is to learn the domain model firstly and then based on the learned model to find the (near) optimal policy. However, offline learning the model often needs to store the entire training data and cannot utilize the data generated in the planning phase. Furthermore, current research usually assumes the learned model is accurate or presupposes knowledge of the nature of the unobservable part of the world. In this paper, for systems with discrete settings, with the benefits of Predictive State Representations~(PSRs), a model-based planning approach is proposed where the learning and planning phases can both be executed online and no prior knowledge of the underlying system is required. Experimental results show compared to the state-of-the-art approaches, our algorithm achieved a high level of performance with no prior knowledge provided, along with theoretical advantages of PSRs. Source code is available at https://github.com/DMU-XMU/PSR-MCTS-Online.