 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Learning and Planning in Partially Observable Domains without Prior Knowledge
Jun 11, 2019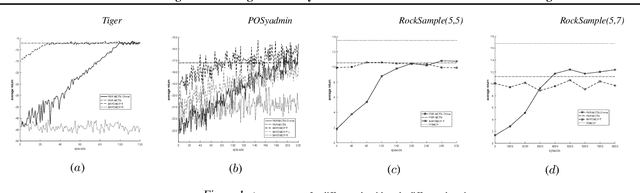
How an agent can act optimally in stochastic, partially observable domains is a challenge problem, the standard approach to address this issue is to learn the domain model firstly and then based on the learned model to find the (near) optimal policy. However, offline learning the model often needs to store the entire training data and cannot utilize the data generated in the planning phase. Furthermore, current research usually assumes the learned model is accurate or presupposes knowledge of the nature of the unobservable part of the world. In this paper, for systems with discrete settings, with the benefits of Predictive State Representations~(PSRs), a model-based planning approach is proposed where the learning and planning phases can both be executed online and no prior knowledge of the underlying system is required. Experimental results show compared to the state-of-the-art approaches, our algorithm achieved a high level of performance with no prior knowledge provided, along with theoretical advantages of PSRs. Source code is available at https://github.com/DMU-XMU/PSR-MCTS-Online.
Combining Offline Models and Online Monte-Carlo Tree Search for Planning from Scratch
Apr 05, 2019

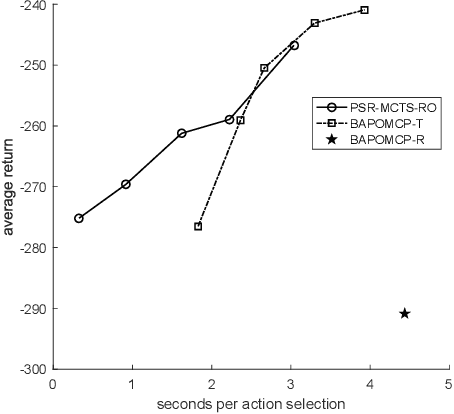
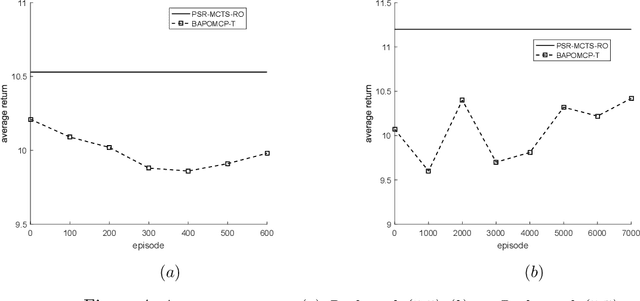
Planning in stochastic and partially observable environments is a central issue in artificial intelligence. One commonly used technique for solving such a problem is by constructing an accurate model firstly. Although some recent approaches have been proposed for learning optimal behaviour under model uncertainty, prior knowledge about the environment is still needed to guarantee the performance of the proposed algorithms. With the benefits of the Predictive State Representations~(PSRs) approach for state representation and model prediction, in this paper, we introduce an approach for planning from scratch, where an offline PSR model is firstly learned and then combined with online Monte-Carlo tree search for planning with model uncertainty. By comparing with the state-of-the-art approach of planning with model uncertainty, we demonstrated the effectiveness of the proposed approaches along with the proof of their convergence. The effectiveness and scalability of our proposed approach are also tested on the RockSample problem, which are infeasible for the state-of-the-art BA-POMDP based approaches.