 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTMD-Bench: A Multi-Level Evaluation Paradigm for Music-Dance Co-Generation
May 03, 2026Unified audio-visual generation is rapidly gaining industrial and creative relevance, enabling applications in virtual production and interactive media. However, when moving from general audio-video synthesis to music-dance co-generation, the task becomes substantially harder: musical rhythm, phrasing, and accents must drive choreographic motion at fine temporal resolution, and such rhythmic coupling is not captured by unimodal metrics or generic audiovisual consistency scores used in current evaluation practice. We introduce TMD-Bench, a benchmark for text-driven music-dance co-generation that assesses systems across unimodal generation quality, instruction adherence, and cross-modal rhythmic alignment. The benchmark integrates computable physical metrics with perceptual multimodal judgments, and is supported by a curated rhythm-aligned music-dance dataset and a fine-grained Music Captioner for structured music semantics. TMD-Bench further reveals that (i) modern commercial audio-visual models, such as Veo 3 and Sora 2, produce high-quality music and video, while rhythmic coupling remains less consistently optimized and leaves room for improvement, and (ii) our unified baseline RhyJAM trained on rhythm-aligned data achieves competitive beat-level synchronization while maintaining competitive unimodal fidelity. This presents prospects for building next-generation music-dance models that explicitly optimize rhythmic and kinetic coherence.
ClawMark: A Living-World Benchmark for Multi-Turn, Multi-Day, Multimodal Coworker Agents
Apr 26, 2026Language-model agents are increasingly used as persistent coworkers that assist users across multiple working days. During such workflows, the surrounding environment may change independently of the agent: new emails arrive, calendar entries shift, knowledge-base records are updated, and evidence appears across images, scanned PDFs, audio, video, and spreadsheets. Existing benchmarks do not adequately evaluate this setting because they typically run within a single static episode and remain largely text-centric. We introduce \bench{}, a benchmark for coworker agents built around multi-turn multi-day tasks, a stateful sandboxed service environment whose state evolves between turns, and rule-based verification. The current release contains 100 tasks across 13 professional scenarios, executed against five stateful sandboxed services (filesystem, email, calendar, knowledge base, spreadsheet) and scored by 1537 deterministic Python checkers over post-execution service state; no LLM-as-judge is invoked during scoring. We benchmark seven frontier agent systems. The strongest model reaches 75.8 weighted score, but the best strict Task Success is only 20.0\%, indicating that partial progress is common while complete end-to-end workflow completion remains rare. Turn-level analysis shows that performance drops after the first exogenous environment update, highlighting adaptation to changing state as a key open challenge. We release the benchmark, evaluation harness, and construction pipeline to support reproducible coworker-agent evaluation.
Not All Frames Are Equal: Complexity-Aware Masked Motion Generation via Motion Spectral Descriptors
Mar 31, 2026Masked generative models have become a strong paradigm for text-to-motion synthesis, but they still treat motion frames too uniformly during masking, attention, and decoding. This is a poor match for motion, where local dynamic complexity varies sharply over time. We show that current masked motion generators degrade disproportionately on dynamically complex motions, and that frame-wise generation error is strongly correlated with motion dynamics. Motivated by this mismatch, we introduce the Motion Spectral Descriptor (MSD), a simple and parameter-free measure of local dynamic complexity computed from the short-time spectrum of motion velocity. Unlike learned difficulty predictors, MSD is deterministic, interpretable, and derived directly from the motion signal itself. We use MSD to make masked motion generation complexity-aware. In particular, MSD guides content-focused masking during training, provides a spectral similarity prior for self-attention, and can additionally modulate token-level sampling during iterative decoding. Built on top of masked motion generators, our method, DynMask, improves motion generation most clearly on dynamically complex motions while also yielding stronger overall FID on HumanML3D and KIT-ML. These results suggest that respecting local motion complexity is a useful design principle for masked motion generation. Project page: https://xiangyue-zhang.github.io/DynMask
SentGraph: Hierarchical Sentence Graph for Multi-hop Retrieval-Augmented Question Answering
Jan 06, 2026Traditional Retrieval-Augmented Generation (RAG) effectively supports single-hop question answering with large language models but faces significant limitations in multi-hop question answering tasks, which require combining evidence from multiple documents. Existing chunk-based retrieval often provides irrelevant and logically incoherent context, leading to incomplete evidence chains and incorrect reasoning during answer generation. To address these challenges, we propose SentGraph, a sentence-level graph-based RAG framework that explicitly models fine-grained logical relationships between sentences for multi-hop question answering. Specifically, we construct a hierarchical sentence graph offline by first adapting Rhetorical Structure Theory to distinguish nucleus and satellite sentences, and then organizing them into topic-level subgraphs with cross-document entity bridges. During online retrieval, SentGraph performs graph-guided evidence selection and path expansion to retrieve fine-grained sentence-level evidence. Extensive experiments on four multi-hop question answering benchmarks demonstrate the effectiveness of SentGraph, validating the importance of explicitly modeling sentence-level logical dependencies for multi-hop reasoning.
Act2Goal: From World Model To General Goal-conditioned Policy
Dec 29, 2025Specifying robotic manipulation tasks in a manner that is both expressive and precise remains a central challenge. While visual goals provide a compact and unambiguous task specification, existing goal-conditioned policies often struggle with long-horizon manipulation due to their reliance on single-step action prediction without explicit modeling of task progress. We propose Act2Goal, a general goal-conditioned manipulation policy that integrates a goal-conditioned visual world model with multi-scale temporal control. Given a current observation and a target visual goal, the world model generates a plausible sequence of intermediate visual states that captures long-horizon structure. To translate this visual plan into robust execution, we introduce Multi-Scale Temporal Hashing (MSTH), which decomposes the imagined trajectory into dense proximal frames for fine-grained closed-loop control and sparse distal frames that anchor global task consistency. The policy couples these representations with motor control through end-to-end cross-attention, enabling coherent long-horizon behavior while remaining reactive to local disturbances. Act2Goal achieves strong zero-shot generalization to novel objects, spatial layouts, and environments. We further enable reward-free online adaptation through hindsight goal relabeling with LoRA-based finetuning, allowing rapid autonomous improvement without external supervision. Real-robot experiments demonstrate that Act2Goal improves success rates from 30% to 90% on challenging out-of-distribution tasks within minutes of autonomous interaction, validating that goal-conditioned world models with multi-scale temporal control provide structured guidance necessary for robust long-horizon manipulation. Project page: https://act2goal.github.io/
Uni-Neur2Img: Unified Neural Signal-Guided Image Generation, Editing, and Stylization via Diffusion Transformers
Dec 21, 2025Generating or editing images directly from Neural signals has immense potential at the intersection of neuroscience, vision, and Brain-computer interaction. In this paper, We present Uni-Neur2Img, a unified framework for neural signal-driven image generation and editing. The framework introduces a parameter-efficient LoRA-based neural signal injection module that independently processes each conditioning signal as a pluggable component, facilitating flexible multi-modal conditioning without altering base model parameters. Additionally, we employ a causal attention mechanism accommodate the long-sequence modeling demands of conditional generation tasks. Existing neural-driven generation research predominantly focuses on textual modalities as conditions or intermediate representations, resulting in limited exploration of visual modalities as direct conditioning signals. To bridge this research gap, we introduce the EEG-Style dataset. We conduct comprehensive evaluations across public benchmarks and self-collected neural signal datasets: (1) EEG-driven image generation on the public CVPR40 dataset; (2) neural signal-guided image editing on the public Loongx dataset for semantic-aware local modifications; and (3) EEG-driven style transfer on our self-collected EEG-Style dataset. Extensive experimental results demonstrate significant improvements in generation fidelity, editing consistency, and style transfer quality while maintaining low computational overhead and strong scalability to additional modalities. Thus, Uni-Neur2Img offers a unified, efficient, and extensible solution for bridging neural signals and visual content generation.
RAPID^3: Tri-Level Reinforced Acceleration Policies for Diffusion Transformer
Sep 26, 2025Diffusion Transformers (DiTs) excel at visual generation yet remain hampered by slow sampling. Existing training-free accelerators - step reduction, feature caching, and sparse attention - enhance inference speed but typically rely on a uniform heuristic or a manually designed adaptive strategy for all images, leaving quality on the table. Alternatively, dynamic neural networks offer per-image adaptive acceleration, but their high fine-tuning costs limit broader applicability. To address these limitations, we introduce RAPID3: Tri-Level Reinforced Acceleration Policies for Diffusion Transformers, a framework that delivers image-wise acceleration with zero updates to the base generator. Specifically, three lightweight policy heads - Step-Skip, Cache-Reuse, and Sparse-Attention - observe the current denoising state and independently decide their corresponding speed-up at each timestep. All policy parameters are trained online via Group Relative Policy Optimization (GRPO) while the generator remains frozen. Meanwhile, an adversarially learned discriminator augments the reward signal, discouraging reward hacking by boosting returns only when generated samples stay close to the original model's distribution. Across state-of-the-art DiT backbones, including Stable Diffusion 3 and FLUX, RAPID3 achieves nearly 3x faster sampling with competitive generation quality.
MDK12-Bench: A Comprehensive Evaluation of Multimodal Large Language Models on Multidisciplinary Exams
Aug 09, 2025Multimodal large language models (MLLMs), which integrate language and visual cues for problem-solving, are crucial for advancing artificial general intelligence (AGI). However, current benchmarks for measuring the intelligence of MLLMs suffer from limited scale, narrow coverage, and unstructured knowledge, offering only static and undifferentiated evaluations. To bridge this gap, we introduce MDK12-Bench, a large-scale multidisciplinary benchmark built from real-world K-12 exams spanning six disciplines with 141K instances and 6,225 knowledge points organized in a six-layer taxonomy. Covering five question formats with difficulty and year annotations, it enables comprehensive evaluation to capture the extent to which MLLMs perform over four dimensions: 1) difficulty levels, 2) temporal (cross-year) shifts, 3) contextual shifts, and 4) knowledge-driven reasoning. We propose a novel dynamic evaluation framework that introduces unfamiliar visual, textual, and question form shifts to challenge model generalization while improving benchmark objectivity and longevity by mitigating data contamination. We further evaluate knowledge-point reference-augmented generation (KP-RAG) to examine the role of knowledge in problem-solving. Key findings reveal limitations in current MLLMs in multiple aspects and provide guidance for enhancing model robustness, interpretability, and AI-assisted education.
Genie Envisioner: A Unified World Foundation Platform for Robotic Manipulation
Aug 07, 2025
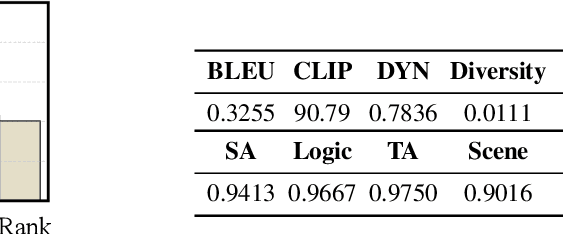

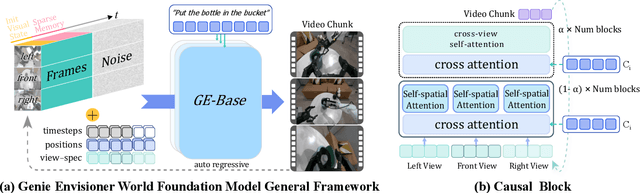
We introduce Genie Envisioner (GE), a unified world foundation platform for robotic manipulation that integrates policy learning, evaluation, and simulation within a single video-generative framework. At its core, GE-Base is a large-scale, instruction-conditioned video diffusion model that captures the spatial, temporal, and semantic dynamics of real-world robotic interactions in a structured latent space. Built upon this foundation, GE-Act maps latent representations to executable action trajectories through a lightweight, flow-matching decoder, enabling precise and generalizable policy inference across diverse embodiments with minimal supervision. To support scalable evaluation and training, GE-Sim serves as an action-conditioned neural simulator, producing high-fidelity rollouts for closed-loop policy development. The platform is further equipped with EWMBench, a standardized benchmark suite measuring visual fidelity, physical consistency, and instruction-action alignment. Together, these components establish Genie Envisioner as a scalable and practical foundation for instruction-driven, general-purpose embodied intelligence. All code, models, and benchmarks will be released publicly.
CrossLinear: Plug-and-Play Cross-Correlation Embedding for Time Series Forecasting with Exogenous Variables
May 29, 2025Time series forecasting with exogenous variables is a critical emerging paradigm that presents unique challenges in modeling dependencies between variables. Traditional models often struggle to differentiate between endogenous and exogenous variables, leading to inefficiencies and overfitting. In this paper, we introduce CrossLinear, a novel Linear-based forecasting model that addresses these challenges by incorporating a plug-and-play cross-correlation embedding module. This lightweight module captures the dependencies between variables with minimal computational cost and seamlessly integrates into existing neural networks. Specifically, it captures time-invariant and direct variable dependencies while disregarding time-varying or indirect dependencies, thereby mitigating the risk of overfitting in dependency modeling and contributing to consistent performance improvements. Furthermore, CrossLinear employs patch-wise processing and a global linear head to effectively capture both short-term and long-term temporal dependencies, further improving its forecasting precision. Extensive experiments on 12 real-world datasets demonstrate that CrossLinear achieves superior performance in both short-term and long-term forecasting tasks. The ablation study underscores the effectiveness of the cross-correlation embedding module. Additionally, the generalizability of this module makes it a valuable plug-in for various forecasting tasks across different domains. Codes are available at https://github.com/mumiao2000/CrossLinear.