 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDK12-Bench: A Comprehensive Evaluation of Multimodal Large Language Models on Multidisciplinary Exams
Aug 09, 2025Multimodal large language models (MLLMs), which integrate language and visual cues for problem-solving, are crucial for advancing artificial general intelligence (AGI). However, current benchmarks for measuring the intelligence of MLLMs suffer from limited scale, narrow coverage, and unstructured knowledge, offering only static and undifferentiated evaluations. To bridge this gap, we introduce MDK12-Bench, a large-scale multidisciplinary benchmark built from real-world K-12 exams spanning six disciplines with 141K instances and 6,225 knowledge points organized in a six-layer taxonomy. Covering five question formats with difficulty and year annotations, it enables comprehensive evaluation to capture the extent to which MLLMs perform over four dimensions: 1) difficulty levels, 2) temporal (cross-year) shifts, 3) contextual shifts, and 4) knowledge-driven reasoning. We propose a novel dynamic evaluation framework that introduces unfamiliar visual, textual, and question form shifts to challenge model generalization while improving benchmark objectivity and longevity by mitigating data contamination. We further evaluate knowledge-point reference-augmented generation (KP-RAG) to examine the role of knowledge in problem-solving. Key findings reveal limitations in current MLLMs in multiple aspects and provide guidance for enhancing model robustness, interpretability, and AI-assisted education.
Human-Aligned Bench: Fine-Grained Assessment of Reasoning Ability in MLLMs vs. Humans
May 16, 2025The goal of achieving Artificial General Intelligence (AGI) is to imitate humans and surpass them. Models such as OpenAI's o1, o3, and DeepSeek's R1 have demonstrated that large language models (LLMs) with human-like reasoning capabilities exhibit exceptional performance and are being gradually integrated into multimodal large language models (MLLMs). However, whether these models possess capabilities comparable to humans in handling reasoning tasks remains unclear at present. In this paper, we propose Human-Aligned Bench, a benchmark for fine-grained alignment of multimodal reasoning with human performance. Specifically, we collected 9,794 multimodal questions that solely rely on contextual reasoning, including bilingual (Chinese and English) multimodal questions and pure text-based questions, encompassing four question types: visual reasoning, definition judgment, analogical reasoning, and logical judgment. More importantly, each question is accompanied by human success rates and options that humans are prone to choosing incorrectly. Extensive experiments on the Human-Aligned Bench reveal notable differences between the performance of current MLLMs in multimodal reasoning and human performance. The findings on our benchmark provide insights into the development of the next-generation models.
AI Idea Bench 2025: AI Research Idea Generation Benchmark
Apr 19, 2025Large-scale Language Models (LLMs) have revolutionized human-AI interaction and achieved significant success in the generation of novel ideas. However, current assessments of idea generation overlook crucial factors such as knowledge leakage in LLMs, the absence of open-ended benchmarks with grounded truth, and the limited scope of feasibility analysis constrained by prompt design. These limitations hinder the potential of uncovering groundbreaking research ideas. In this paper, we present AI Idea Bench 2025, a framework designed to quantitatively evaluate and compare the ideas generated by LLMs within the domain of AI research from diverse perspectives. The framework comprises a comprehensive dataset of 3,495 AI papers and their associated inspired works, along with a robust evaluation methodology. This evaluation system gauges idea quality in two dimensions: alignment with the ground-truth content of the original papers and judgment based on general reference material. AI Idea Bench 2025's benchmarking system stands to be an invaluable resource for assessing and comparing idea-generation techniques, thereby facilitating the automation of scientific discovery.
MDK12-Bench: A Multi-Discipline Benchmark for Evaluating Reasoning in Multimodal Large Language Models
Apr 08, 2025Multimodal reasoning, which integrates language and visual cues into problem solving and decision making, is a fundamental aspect of human intelligence and a crucial step toward artificial general intelligence. However, the evaluation of multimodal reasoning capabilities in Multimodal Large Language Models (MLLMs) remains inadequate. Most existing reasoning benchmarks are constrained by limited data size, narrow domain coverage, and unstructured knowledge distribution. To close these gaps, we introduce MDK12-Bench, a multi-disciplinary benchmark assessing the reasoning capabilities of MLLMs via real-world K-12 examinations. Spanning six disciplines (math, physics, chemistry, biology, geography, and information science), our benchmark comprises 140K reasoning instances across diverse difficulty levels from primary school to 12th grade. It features 6,827 instance-level knowledge point annotations based on a well-organized knowledge structure, detailed answer explanations, difficulty labels and cross-year partitions, providing a robust platform for comprehensive evaluation. Additionally, we present a novel dynamic evaluation framework to mitigate data contamination issues by bootstrapping question forms, question types, and image styles during evaluation. Extensive experiment on MDK12-Bench reveals the significant limitation of current MLLMs in multimodal reasoning. The findings on our benchmark provide insights into the development of the next-generation models. Our data and codes are available at https://github.com/LanceZPF/MDK12.
Devil is in Details: Locality-Aware 3D Abdominal CT Volume Generation for Self-Supervised Organ Segmentation
Sep 30, 2024In the realm of medical image analysis, self-supervised learning (SSL) techniques have emerged to alleviate labeling demands, while still facing the challenge of training data scarcity owing to escalating resource requirements and privacy constraints. Numerous efforts employ generative models to generate high-fidelity, unlabeled 3D volumes across diverse modalities and anatomical regions. However, the intricate and indistinguishable anatomical structures within the abdomen pose a unique challenge to abdominal CT volume generation compared to other anatomical regions. To address the overlooked challenge, we introduce the Locality-Aware Diffusion (Lad), a novel method tailored for exquisite 3D abdominal CT volume generation. We design a locality loss to refine crucial anatomical regions and devise a condition extractor to integrate abdominal priori into generation, thereby enabling the generation of large quantities of high-quality abdominal CT volumes essential for SSL tasks without the need for additional data such as labels or radiology reports. Volumes generated through our method demonstrate remarkable fidelity in reproducing abdominal structures, achieving a decrease in FID score from 0.0034 to 0.0002 on AbdomenCT-1K dataset, closely mirroring authentic data and surpassing current methods. Extensive experiments demonstrate the effectiveness of our method in self-supervised organ segmentation tasks, resulting in an improvement in mean Dice scores on two abdominal datasets effectively. These results underscore the potential of synthetic data to advance self-supervised learning in medical image analysis.
360VFI: A Dataset and Benchmark for Omnidirectional Video Frame Interpolation
Jul 19, 2024



With the development of VR-related techniques, viewers can enjoy a realistic and immersive experience through a head-mounted display, while omnidirectional video with a low frame rate can lead to user dizziness. However, the prevailing plane frame interpolation methodologies are unsuitable for Omnidirectional Video Interpolation, chiefly due to the lack of models tailored to such videos with strong distortion, compounded by the scarcity of valuable datasets for Omnidirectional Video Frame Interpolation. In this paper, we introduce the benchmark dataset, 360VFI, for Omnidirectional Video Frame Interpolation. We present a practical implementation that introduces a distortion prior from omnidirectional video into the network to modulate distortions. We especially propose a pyramid distortion-sensitive feature extractor that uses the unique characteristics of equirectangular projection (ERP) format as prior information. Moreover, we devise a decoder that uses an affine transformation to facilitate the synthesis of intermediate frames further. 360VFI is the first dataset and benchmark that explores the challenge of Omnidirectional Video Frame Interpolation. Through our benchmark analysis, we presented four different distortion conditions scenes in the proposed 360VFI dataset to evaluate the challenge triggered by distortion during interpolation. Besides, experimental results demonstrate that Omnidirectional Video Interpolation can be effectively improved by modeling for omnidirectional distortion.
Degrade is Upgrade: Learning Degradation for Low-light Image Enhancement
Mar 22, 2021
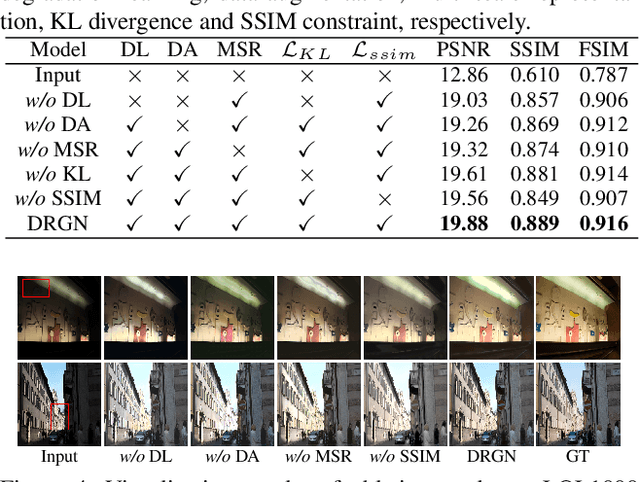
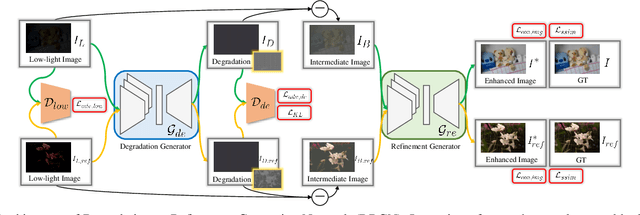
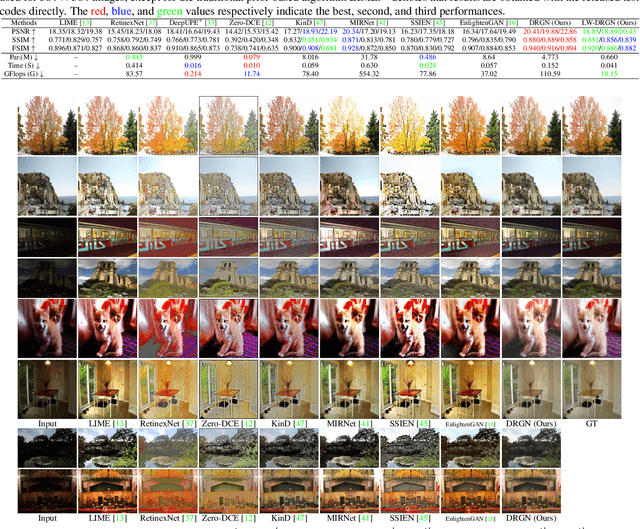
Low-light image enhancement aims to improve an image's visibility while keeping its visual naturalness. Different from existing methods, which tend to accomplish the enhancement task directly, we investigate the intrinsic degradation and relight the low-light image while refining the details and color in two steps. Inspired by the color image formulation (diffuse illumination color plus environment illumination color), we first estimate the degradation from low-light inputs to simulate the distortion of environment illumination color, and then refine the content to recover the loss of diffuse illumination color. To this end, we propose a novel Degradation-to-Refinement Generation Network (DRGN). Its distinctive features can be summarized as 1) A novel two-step generation network for degradation learning and content refinement. It is not only superior to one-step methods, but also is capable of synthesizing sufficient paired samples to benefit the model training; 2) A multi-resolution fusion network to represent the target information (degradation or contents) in a multi-scale cooperative manner, which is more effective to address the complex unmixing problems. Extensive experiments on both the enhancement task and the joint detection task have verified the effectiveness and efficiency of our proposed method, surpassing the SOTA by 0.95dB in PSNR on LOL1000 dataset and 3.18\% in mAP on ExDark dataset. Our code is available at \url{https://github.com/kuijiang0802/DRGN}