 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan World Simulators Reason? Gen-ViRe: A Generative Visual Reasoning Benchmark
Nov 17, 2025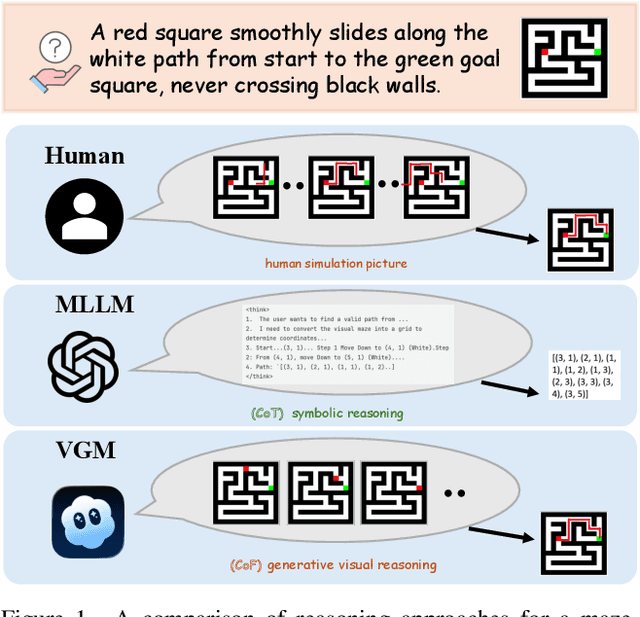
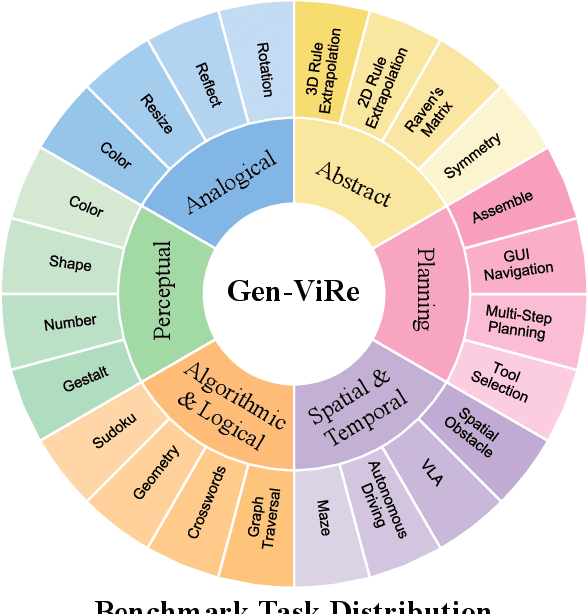
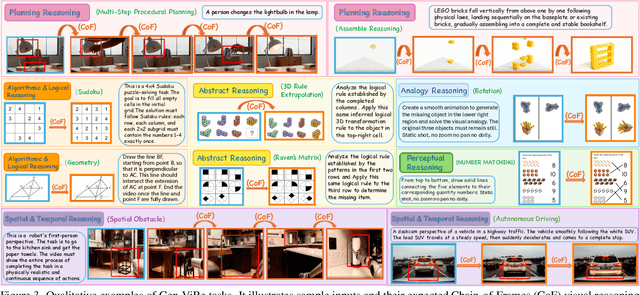
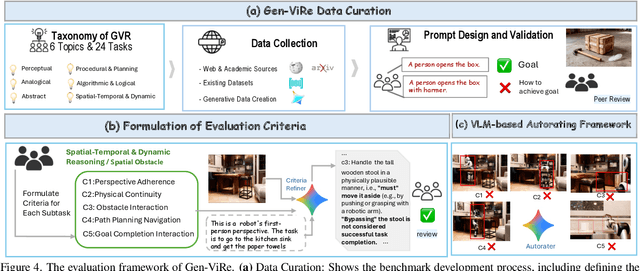
While Chain-of-Thought (CoT) prompting enables sophisticated symbolic reasoning in LLMs, it remains confined to discrete text and cannot simulate the continuous, physics-governed dynamics of the real world. Recent video generation models have emerged as potential world simulators through Chain-of-Frames (CoF) reasoning -- materializing thought as frame-by-frame visual sequences, with each frame representing a physically-grounded reasoning step. Despite compelling demonstrations, a challenge persists: existing benchmarks, focusing on fidelity or alignment, do not assess CoF reasoning and thus cannot measure core cognitive abilities in multi-step planning, algorithmic logic, or abstract pattern extrapolation. This evaluation void prevents systematic understanding of model capabilities and principled guidance for improvement. We introduce Gen-ViRe (Generative Visual Reasoning Benchmark), a framework grounded in cognitive science and real-world AI applications, which decomposes CoF reasoning into six cognitive dimensions -- from perceptual logic to abstract planning -- and 24 subtasks. Through multi-source data curation, minimal prompting protocols, and hybrid VLM-assisted evaluation with detailed criteria, Gen-ViRe delivers the first quantitative assessment of video models as reasoners. Our experiments on SOTA systems reveal substantial discrepancies between impressive visual quality and actual reasoning depth, establishing baselines and diagnostic tools to advance genuine world simulators.
MDK12-Bench: A Comprehensive Evaluation of Multimodal Large Language Models on Multidisciplinary Exams
Aug 09, 2025Multimodal large language models (MLLMs), which integrate language and visual cues for problem-solving, are crucial for advancing artificial general intelligence (AGI). However, current benchmarks for measuring the intelligence of MLLMs suffer from limited scale, narrow coverage, and unstructured knowledge, offering only static and undifferentiated evaluations. To bridge this gap, we introduce MDK12-Bench, a large-scale multidisciplinary benchmark built from real-world K-12 exams spanning six disciplines with 141K instances and 6,225 knowledge points organized in a six-layer taxonomy. Covering five question formats with difficulty and year annotations, it enables comprehensive evaluation to capture the extent to which MLLMs perform over four dimensions: 1) difficulty levels, 2) temporal (cross-year) shifts, 3) contextual shifts, and 4) knowledge-driven reasoning. We propose a novel dynamic evaluation framework that introduces unfamiliar visual, textual, and question form shifts to challenge model generalization while improving benchmark objectivity and longevity by mitigating data contamination. We further evaluate knowledge-point reference-augmented generation (KP-RAG) to examine the role of knowledge in problem-solving. Key findings reveal limitations in current MLLMs in multiple aspects and provide guidance for enhancing model robustness, interpretability, and AI-assisted education.
Sekai: A Video Dataset towards World Exploration
Jun 18, 2025Video generation techniques have made remarkable progress, promising to be the foundation of interactive world exploration. However, existing video generation datasets are not well-suited for world exploration training as they suffer from some limitations: limited locations, short duration, static scenes, and a lack of annotations about exploration and the world. In this paper, we introduce Sekai (meaning ``world'' in Japanese), a high-quality first-person view worldwide video dataset with rich annotations for world exploration. It consists of over 5,000 hours of walking or drone view (FPV and UVA) videos from over 100 countries and regions across 750 cities. We develop an efficient and effective toolbox to collect, pre-process and annotate videos with location, scene, weather, crowd density, captions, and camera trajectories. Experiments demonstrate the quality of the dataset. And, we use a subset to train an interactive video world exploration model, named YUME (meaning ``dream'' in Japanese). We believe Sekai will benefit the area of video generation and world exploration, and motivate valuable applications.
Human-Aligned Bench: Fine-Grained Assessment of Reasoning Ability in MLLMs vs. Humans
May 16, 2025The goal of achieving Artificial General Intelligence (AGI) is to imitate humans and surpass them. Models such as OpenAI's o1, o3, and DeepSeek's R1 have demonstrated that large language models (LLMs) with human-like reasoning capabilities exhibit exceptional performance and are being gradually integrated into multimodal large language models (MLLMs). However, whether these models possess capabilities comparable to humans in handling reasoning tasks remains unclear at present. In this paper, we propose Human-Aligned Bench, a benchmark for fine-grained alignment of multimodal reasoning with human performance. Specifically, we collected 9,794 multimodal questions that solely rely on contextual reasoning, including bilingual (Chinese and English) multimodal questions and pure text-based questions, encompassing four question types: visual reasoning, definition judgment, analogical reasoning, and logical judgment. More importantly, each question is accompanied by human success rates and options that humans are prone to choosing incorrectly. Extensive experiments on the Human-Aligned Bench reveal notable differences between the performance of current MLLMs in multimodal reasoning and human performance. The findings on our benchmark provide insights into the development of the next-generation models.
AI Idea Bench 2025: AI Research Idea Generation Benchmark
Apr 19, 2025Large-scale Language Models (LLMs) have revolutionized human-AI interaction and achieved significant success in the generation of novel ideas. However, current assessments of idea generation overlook crucial factors such as knowledge leakage in LLMs, the absence of open-ended benchmarks with grounded truth, and the limited scope of feasibility analysis constrained by prompt design. These limitations hinder the potential of uncovering groundbreaking research ideas. In this paper, we present AI Idea Bench 2025, a framework designed to quantitatively evaluate and compare the ideas generated by LLMs within the domain of AI research from diverse perspectives. The framework comprises a comprehensive dataset of 3,495 AI papers and their associated inspired works, along with a robust evaluation methodology. This evaluation system gauges idea quality in two dimensions: alignment with the ground-truth content of the original papers and judgment based on general reference material. AI Idea Bench 2025's benchmarking system stands to be an invaluable resource for assessing and comparing idea-generation techniques, thereby facilitating the automation of scientific discovery.
MDK12-Bench: A Multi-Discipline Benchmark for Evaluating Reasoning in Multimodal Large Language Models
Apr 08, 2025Multimodal reasoning, which integrates language and visual cues into problem solving and decision making, is a fundamental aspect of human intelligence and a crucial step toward artificial general intelligence. However, the evaluation of multimodal reasoning capabilities in Multimodal Large Language Models (MLLMs) remains inadequate. Most existing reasoning benchmarks are constrained by limited data size, narrow domain coverage, and unstructured knowledge distribution. To close these gaps, we introduce MDK12-Bench, a multi-disciplinary benchmark assessing the reasoning capabilities of MLLMs via real-world K-12 examinations. Spanning six disciplines (math, physics, chemistry, biology, geography, and information science), our benchmark comprises 140K reasoning instances across diverse difficulty levels from primary school to 12th grade. It features 6,827 instance-level knowledge point annotations based on a well-organized knowledge structure, detailed answer explanations, difficulty labels and cross-year partitions, providing a robust platform for comprehensive evaluation. Additionally, we present a novel dynamic evaluation framework to mitigate data contamination issues by bootstrapping question forms, question types, and image styles during evaluation. Extensive experiment on MDK12-Bench reveals the significant limitation of current MLLMs in multimodal reasoning. The findings on our benchmark provide insights into the development of the next-generation models. Our data and codes are available at https://github.com/LanceZPF/MDK12.
PEBench: A Fictitious Dataset to Benchmark Machine Unlearning for Multimodal Large Language Models
Mar 16, 2025



In recent years, Multimodal Large Language Models (MLLMs) have demonstrated remarkable advancements in tasks such as visual question answering, visual understanding, and reasoning. However, this impressive progress relies on vast amounts of data collected from the internet, raising significant concerns about privacy and security. To address these issues, machine unlearning (MU) has emerged as a promising solution, enabling the removal of specific knowledge from an already trained model without requiring retraining from scratch. Although MU for MLLMs has gained attention, current evaluations of its efficacy remain incomplete, and the underlying problem is often poorly defined, which hinders the development of strategies for creating more secure and trustworthy systems. To bridge this gap, we introduce a benchmark, named PEBench, which includes a dataset of personal entities and corresponding general event scenes, designed to comprehensively assess the performance of MU for MLLMs. Through PEBench, we aim to provide a standardized and robust framework to advance research in secure and privacy-preserving multimodal models. We benchmarked 6 MU methods, revealing their strengths and limitations, and shedding light on key challenges and opportunities for MU in MLLMs.
MPBench: A Comprehensive Multimodal Reasoning Benchmark for Process Errors Identification
Mar 16, 2025



Reasoning is an essential capacity for large language models (LLMs) to address complex tasks, where the identification of process errors is vital for improving this ability. Recently, process-level reward models (PRMs) were proposed to provide step-wise rewards that facilitate reinforcement learning and data production during training and guide LLMs toward correct steps during inference, thereby improving reasoning accuracy. However, existing benchmarks of PRMs are text-based and focus on error detection, neglecting other scenarios like reasoning search. To address this gap, we introduce MPBench, a comprehensive, multi-task, multimodal benchmark designed to systematically assess the effectiveness of PRMs in diverse scenarios. MPBench employs three evaluation paradigms, each targeting a specific role of PRMs in the reasoning process: (1) Step Correctness, which assesses the correctness of each intermediate reasoning step; (2) Answer Aggregation, which aggregates multiple solutions and selects the best one; and (3) Reasoning Process Search, which guides the search for optimal reasoning steps during inference. Through these paradigms, MPBench makes comprehensive evaluations and provides insights into the development of multimodal PRMs.
ProJudge: A Multi-Modal Multi-Discipline Benchmark and Instruction-Tuning Dataset for MLLM-based Process Judges
Mar 09, 2025As multi-modal large language models (MLLMs) frequently exhibit errors when solving scientific problems, evaluating the validity of their reasoning processes is critical for ensuring reliability and uncovering fine-grained model weaknesses. Since human evaluation is laborious and costly, prompting MLLMs as automated process judges has become a common practice. However, the reliability of these model-based judges remains uncertain. To address this, we introduce ProJudgeBench, the first comprehensive benchmark specifically designed for evaluating abilities of MLLM-based process judges. ProJudgeBench comprises 2,400 test cases and 50,118 step-level labels, spanning four scientific disciplines with diverse difficulty levels and multi-modal content. In ProJudgeBench, each step is meticulously annotated by human experts for correctness, error type, and explanation, enabling a systematic evaluation of judges' capabilities to detect, classify and diagnose errors. Evaluation on ProJudgeBench reveals a significant performance gap between open-source and proprietary models. To bridge this gap, we further propose ProJudge-173k, a large-scale instruction-tuning dataset, and a Dynamic Dual-Phase fine-tuning strategy that encourages models to explicitly reason through problem-solving before assessing solutions. Both contributions significantly enhance the process evaluation capabilities of open-source models. All the resources will be released to foster future research of reliable multi-modal process evaluation.
Bridge then Begin Anew: Generating Target-relevant Intermediate Model for Source-free Visual Emotion Adaptation
Dec 18, 2024



Visual emotion recognition (VER), which aims at understanding humans' emotional reactions toward different visual stimuli, has attracted increasing attention. Given the subjective and ambiguous characteristics of emotion, annotating a reliable large-scale dataset is hard. For reducing reliance on data labeling, domain adaptation offers an alternative solution by adapting models trained on labeled source data to unlabeled target data. Conventional domain adaptation methods require access to source data. However, due to privacy concerns, source emotional data may be inaccessible. To address this issue, we propose an unexplored task: source-free domain adaptation (SFDA) for VER, which does not have access to source data during the adaptation process. To achieve this, we propose a novel framework termed Bridge then Begin Anew (BBA), which consists of two steps: domain-bridged model generation (DMG) and target-related model adaptation (TMA). First, the DMG bridges cross-domain gaps by generating an intermediate model, avoiding direct alignment between two VER datasets with significant differences. Then, the TMA begins training the target model anew to fit the target structure, avoiding the influence of source-specific knowledge. Extensive experiments are conducted on six SFDA settings for VER. The results demonstrate the effectiveness of BBA, which achieves remarkable performance gains compared with state-of-the-art SFDA methods and outperforms representative unsupervised domain adaptation approaches.