 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Autoregressive Image Generation through Coarse-to-Fine Token Prediction
Mar 20, 2025Autoregressive models have shown remarkable success in image generation by adapting sequential prediction techniques from language modeling. However, applying these approaches to images requires discretizing continuous pixel data through vector quantization methods like VQ-VAE. To alleviate the quantization errors that existed in VQ-VAE, recent works tend to use larger codebooks. However, this will accordingly expand vocabulary size, complicating the autoregressive modeling task. This paper aims to find a way to enjoy the benefits of large codebooks without making autoregressive modeling more difficult. Through empirical investigation, we discover that tokens with similar codeword representations produce similar effects on the final generated image, revealing significant redundancy in large codebooks. Based on this insight, we propose to predict tokens from coarse to fine (CTF), realized by assigning the same coarse label for similar tokens. Our framework consists of two stages: (1) an autoregressive model that sequentially predicts coarse labels for each token in the sequence, and (2) an auxiliary model that simultaneously predicts fine-grained labels for all tokens conditioned on their coarse labels. Experiments on ImageNet demonstrate our method's superior performance, achieving an average improvement of 59 points in Inception Score compared to baselines. Notably, despite adding an inference step, our approach achieves faster sampling speeds.
GATE OpenING: A Comprehensive Benchmark for Judging Open-ended Interleaved Image-Text Generation
Dec 01, 2024Multimodal Large Language Models (MLLMs) have made significant strides in visual understanding and generation tasks. However, generating interleaved image-text content remains a challenge, which requires integrated multimodal understanding and generation abilities. While the progress in unified models offers new solutions, existing benchmarks are insufficient for evaluating these methods due to data size and diversity limitations. To bridge this gap, we introduce GATE OpenING (OpenING), a comprehensive benchmark comprising 5,400 high-quality human-annotated instances across 56 real-world tasks. OpenING covers diverse daily scenarios such as travel guide, design, and brainstorming, offering a robust platform for challenging interleaved generation methods. In addition, we present IntJudge, a judge model for evaluating open-ended multimodal generation methods. Trained with a novel data pipeline, our IntJudge achieves an agreement rate of 82. 42% with human judgments, outperforming GPT-based evaluators by 11.34%. Extensive experiments on OpenING reveal that current interleaved generation methods still have substantial room for improvement. Key findings on interleaved image-text generation are further presented to guide the development of next-generation models. The OpenING is open-sourced at https://opening-benchmark.github.io.
Prioritize Alignment in Dataset Distillation
Aug 06, 2024
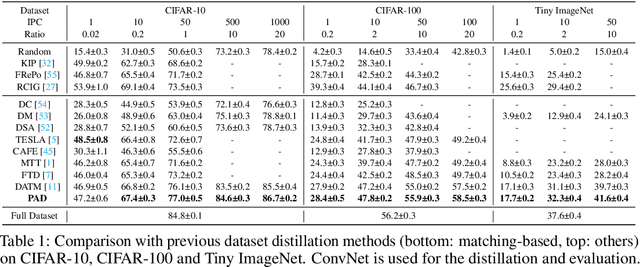
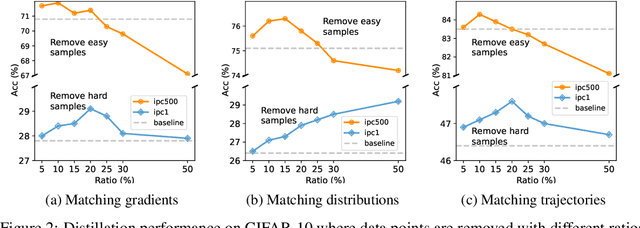
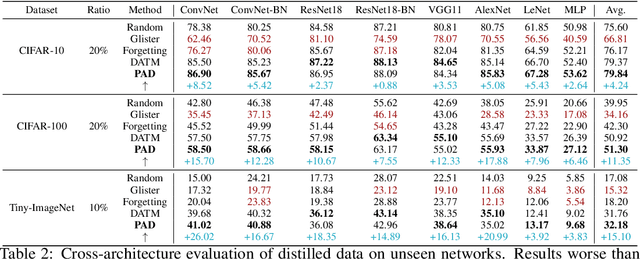
Dataset Distillation aims to compress a large dataset into a significantly more compact, synthetic one without compromising the performance of the trained models. To achieve this, existing methods use the agent model to extract information from the target dataset and embed it into the distilled dataset. Consequently, the quality of extracted and embedded information determines the quality of the distilled dataset. In this work, we find that existing methods introduce misaligned information in both information extraction and embedding stages. To alleviate this, we propose Prioritize Alignment in Dataset Distillation (PAD), which aligns information from the following two perspectives. 1) We prune the target dataset according to the compressing ratio to filter the information that can be extracted by the agent model. 2) We use only deep layers of the agent model to perform the distillation to avoid excessively introducing low-level information. This simple strategy effectively filters out misaligned information and brings non-trivial improvement for mainstream matching-based distillation algorithms. Furthermore, built on trajectory matching, \textbf{PAD} achieves remarkable improvements on various benchmarks, achieving state-of-the-art performance.
Rethinking Human Evaluation Protocol for Text-to-Video Models: Enhancing Reliability,Reproducibility, and Practicality
Jun 13, 2024
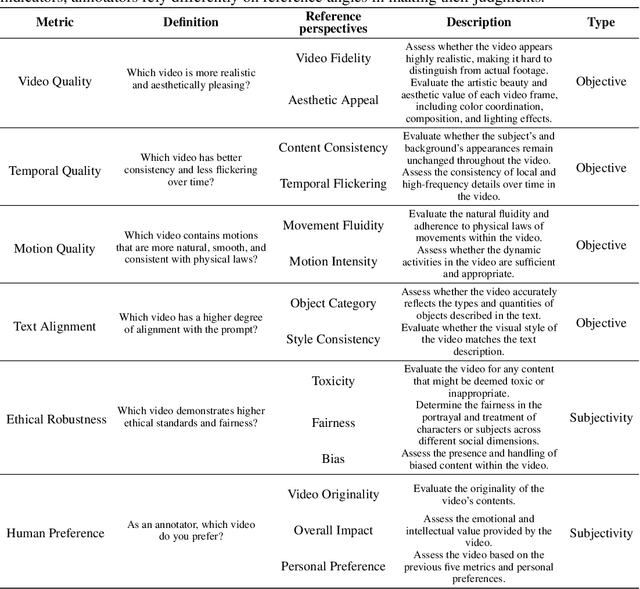
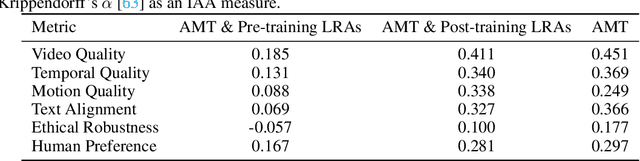
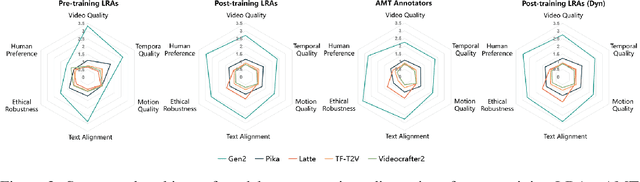
Recent text-to-video (T2V) technology advancements, as demonstrated by models such as Gen2, Pika, and Sora, have significantly broadened its applicability and popularity. Despite these strides, evaluating these models poses substantial challenges. Primarily, due to the limitations inherent in automatic metrics, manual evaluation is often considered a superior method for assessing T2V generation. However, existing manual evaluation protocols face reproducibility, reliability, and practicality issues. To address these challenges, this paper introduces the Text-to-Video Human Evaluation (T2VHE) protocol, a comprehensive and standardized protocol for T2V models. The T2VHE protocol includes well-defined metrics, thorough annotator training, and an effective dynamic evaluation module. Experimental results demonstrate that this protocol not only ensures high-quality annotations but can also reduce evaluation costs by nearly 50%. We will open-source the entire setup of the T2VHE protocol, including the complete protocol workflow, the dynamic evaluation component details, and the annotation interface code. This will help communities establish more sophisticated human assessment protocols.
Navigating Complexity: Toward Lossless Graph Condensation via Expanding Window Matching
Feb 07, 2024Graph condensation aims to reduce the size of a large-scale graph dataset by synthesizing a compact counterpart without sacrificing the performance of Graph Neural Networks (GNNs) trained on it, which has shed light on reducing the computational cost for training GNNs. Nevertheless, existing methods often fall short of accurately replicating the original graph for certain datasets, thereby failing to achieve the objective of lossless condensation. To understand this phenomenon, we investigate the potential reasons and reveal that the previous state-of-the-art trajectory matching method provides biased and restricted supervision signals from the original graph when optimizing the condensed one. This significantly limits both the scale and efficacy of the condensed graph. In this paper, we make the first attempt toward \textit{lossless graph condensation} by bridging the previously neglected supervision signals. Specifically, we employ a curriculum learning strategy to train expert trajectories with more diverse supervision signals from the original graph, and then effectively transfer the information into the condensed graph with expanding window matching. Moreover, we design a loss function to further extract knowledge from the expert trajectories. Theoretical analysis justifies the design of our method and extensive experiments verify its superiority across different datasets. Code is released at https://github.com/NUS-HPC-AI-Lab/GEOM.
Towards Lossless Dataset Distillation via Difficulty-Aligned Trajectory Matching
Oct 09, 2023



The ultimate goal of Dataset Distillation is to synthesize a small synthetic dataset such that a model trained on this synthetic set will perform equally well as a model trained on the full, real dataset. Until now, no method of Dataset Distillation has reached this completely lossless goal, in part due to the fact that previous methods only remain effective when the total number of synthetic samples is extremely small. Since only so much information can be contained in such a small number of samples, it seems that to achieve truly loss dataset distillation, we must develop a distillation method that remains effective as the size of the synthetic dataset grows. In this work, we present such an algorithm and elucidate why existing methods fail to generate larger, high-quality synthetic sets. Current state-of-the-art methods rely on trajectory-matching, or optimizing the synthetic data to induce similar long-term training dynamics as the real data. We empirically find that the training stage of the trajectories we choose to match (i.e., early or late) greatly affects the effectiveness of the distilled dataset. Specifically, early trajectories (where the teacher network learns easy patterns) work well for a low-cardinality synthetic set since there are fewer examples wherein to distribute the necessary information. Conversely, late trajectories (where the teacher network learns hard patterns) provide better signals for larger synthetic sets since there are now enough samples to represent the necessary complex patterns. Based on our findings, we propose to align the difficulty of the generated patterns with the size of the synthetic dataset. In doing so, we successfully scale trajectory matching-based methods to larger synthetic datasets, achieving lossless dataset distillation for the very first time. Code and distilled datasets are available at https://gzyaftermath.github.io/DATM.
Class Attention Transfer Based Knowledge Distillation
Apr 25, 2023Previous knowledge distillation methods have shown their impressive performance on model compression tasks, however, it is hard to explain how the knowledge they transferred helps to improve the performance of the student network. In this work, we focus on proposing a knowledge distillation method that has both high interpretability and competitive performance. We first revisit the structure of mainstream CNN models and reveal that possessing the capacity of identifying class discriminative regions of input is critical for CNN to perform classification. Furthermore, we demonstrate that this capacity can be obtained and enhanced by transferring class activation maps. Based on our findings, we propose class attention transfer based knowledge distillation (CAT-KD). Different from previous KD methods, we explore and present several properties of the knowledge transferred by our method, which not only improve the interpretability of CAT-KD but also contribute to a better understanding of CNN. While having high interpretability, CAT-KD achieves state-of-the-art performance on multiple benchmarks. Code is available at: https://github.com/GzyAftermath/CAT-KD.
Guaranteed Contraction Control in the Presence of Imperfectly Learned Dynamics
Dec 15, 2021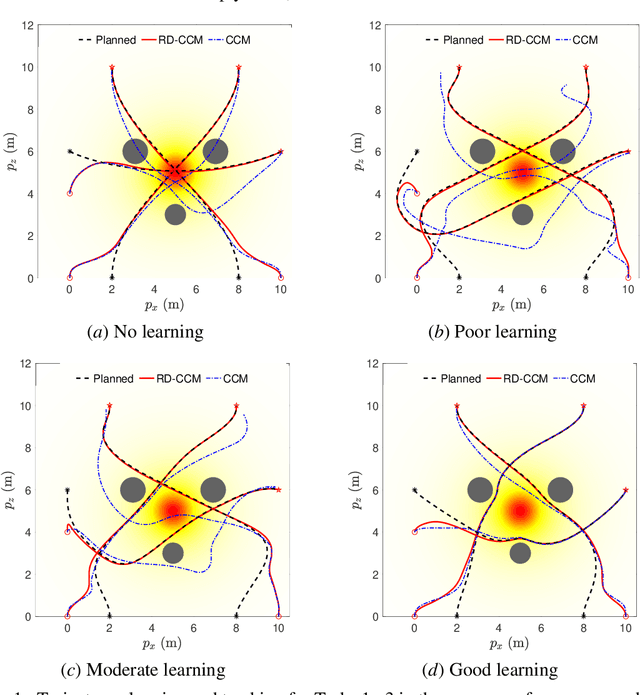
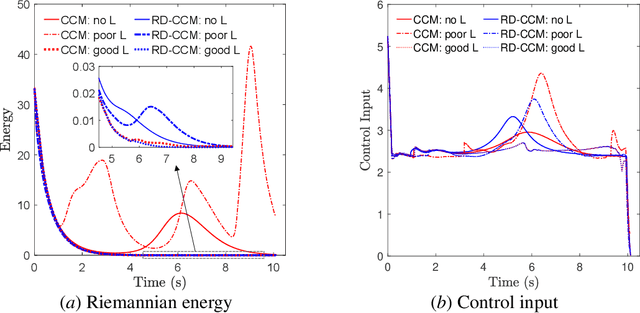
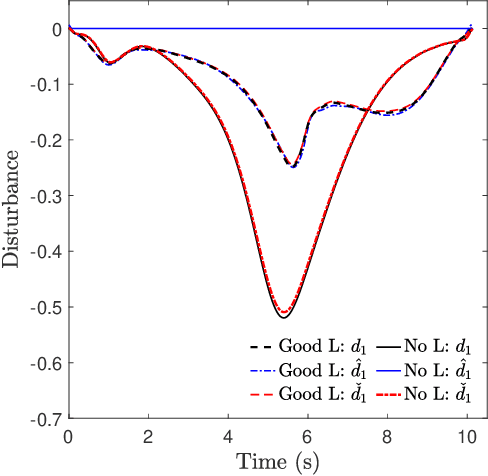
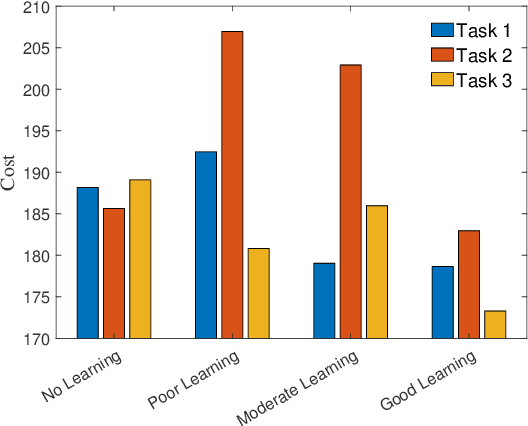
This paper presents an approach for trajectory-centric learning control based on contraction metrics and disturbance estimation for nonlinear systems subject to matched uncertainties. The approach allows for the use of a broad class of model learning tools including deep neural networks to learn uncertain dynamics while still providing guarantees of transient tracking performance throughout the learning phase, including the special case of no learning. Within the proposed approach, a disturbance estimation law is proposed to estimate the pointwise value of the uncertainty, with pre-computable estimation error bounds (EEBs). The learned dynamics, the estimated disturbances, and the EEBs are then incorporated in a robust Riemannian energy condition to compute the control law that guarantees exponential convergence of actual trajectories to desired ones throughout the learning phase, even when the learned model is poor. On the other hand, with improved accuracy, the learned model can be incorporated in a high-level planner to plan better trajectories with improved performance, e.g., lower energy consumption and shorter travel time. The proposed framework is validated on a planar quadrotor navigation example.