 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradually Compacting Large Language Models for Reasoning Like a Boiling Frog
Feb 04, 2026Large Language Models (LLMs) have demonstrated impressive reasoning capabilities, but their substantial size often demands significant computational resources. To reduce resource consumption and accelerate inference, it is essential to eliminate redundant parameters without compromising performance. However, conventional pruning methods that directly remove such parameters often lead to a dramatic drop in model performance in reasoning tasks, and require extensive post-training to recover the lost capabilities. In this work, we propose a gradual compacting method that divides the compression process into multiple fine-grained iterations, applying a Prune-Tune Loop (PTL) at each stage to incrementally reduce model size while restoring performance with finetuning. This iterative approach-reminiscent of the "boiling frog" effect-enables the model to be progressively compressed without abrupt performance loss. Experimental results show that PTL can compress LLMs to nearly half their original size with only lightweight post-training, while maintaining performance comparable to the original model on reasoning tasks. Moreover, PTL is flexible and can be applied to various pruning strategies, such as neuron pruning and layer pruning, as well as different post-training methods, including continual pre-training and reinforcement learning. Additionally, experimental results confirm the effectiveness of PTL on a variety of tasks beyond mathematical reasoning, such as code generation, demonstrating its broad applicability.
ThinkMorph: Emergent Properties in Multimodal Interleaved Chain-of-Thought Reasoning
Oct 30, 2025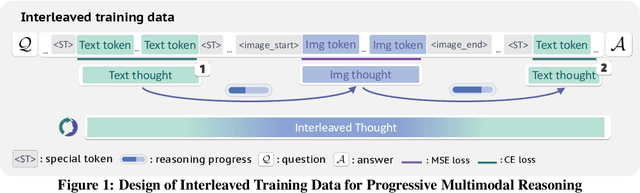
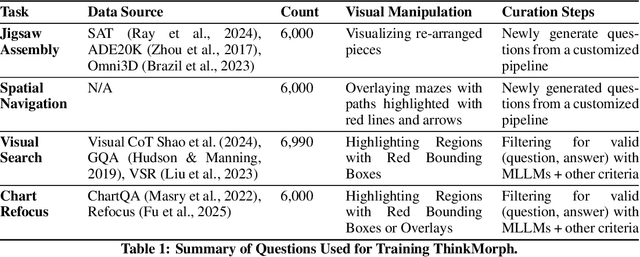


Multimodal reasoning requires iterative coordination between language and vision, yet it remains unclear what constitutes a meaningful interleaved chain of thought. We posit that text and image thoughts should function as complementary, rather than isomorphic, modalities that mutually advance reasoning. Guided by this principle, we build ThinkMorph, a unified model fine-tuned on 24K high-quality interleaved reasoning traces spanning tasks with varying visual engagement. ThinkMorph learns to generate progressive text-image reasoning steps that concretely manipulate visual content while maintaining coherent verbal logic. It delivers large gains on vision-centric benchmarks (averaging 34.7% over the base model) and generalizes to out-of-domain tasks, matching or surpassing larger and proprietary VLMs. Beyond performance, ThinkMorph exhibits emergent multimodal intelligence, including unseen visual manipulation skills, adaptive switching between reasoning modes, and better test-time scaling through diversified multimodal thoughts.These findings suggest promising directions for characterizing the emergent capabilities of unified models for multimodal reasoning.
The Emergence of Abstract Thought in Large Language Models Beyond Any Language
Jun 11, 2025As large language models (LLMs) continue to advance, their capacity to function effectively across a diverse range of languages has shown marked improvement. Preliminary studies observe that the hidden activations of LLMs often resemble English, even when responding to non-English prompts. This has led to the widespread assumption that LLMs may "think" in English. However, more recent results showing strong multilingual performance, even surpassing English performance on specific tasks in other languages, challenge this view. In this work, we find that LLMs progressively develop a core language-agnostic parameter space-a remarkably small subset of parameters whose deactivation results in significant performance degradation across all languages. This compact yet critical set of parameters underlies the model's ability to generalize beyond individual languages, supporting the emergence of abstract thought that is not tied to any specific linguistic system. Specifically, we identify language-related neurons-those are consistently activated during the processing of particular languages, and categorize them as either shared (active across multiple languages) or exclusive (specific to one). As LLMs undergo continued development over time, we observe a marked increase in both the proportion and functional importance of shared neurons, while exclusive neurons progressively diminish in influence. These shared neurons constitute the backbone of the core language-agnostic parameter space, supporting the emergence of abstract thought. Motivated by these insights, we propose neuron-specific training strategies tailored to LLMs' language-agnostic levels at different development stages. Experiments across diverse LLM families support our approach.
NoisyRollout: Reinforcing Visual Reasoning with Data Augmentation
Apr 17, 2025Recent advances in reinforcement learning (RL) have strengthened the reasoning capabilities of vision-language models (VLMs). However, enhancing policy exploration to more effectively scale test-time compute remains underexplored in VLMs. In addition, VLMs continue to struggle with imperfect visual perception, which in turn affects the subsequent reasoning process. To this end, we propose NoisyRollout, a simple yet effective RL approach that mixes trajectories from both clean and moderately distorted images to introduce targeted diversity in visual perception and the resulting reasoning patterns. Without additional training cost, NoisyRollout enhances the exploration capabilities of VLMs by incorporating a vision-oriented inductive bias. Furthermore, NoisyRollout employs a noise annealing schedule that gradually reduces distortion strength over training, ensuring benefit from noisy signals early while maintaining training stability and scalability in later stages. With just 2.1K training samples, NoisyRollout achieves state-of-the-art performance among open-source RL-tuned models on 5 out-of-domain benchmarks spanning both reasoning and perception tasks, while preserving comparable or even better in-domain performance.
Efficient Process Reward Model Training via Active Learning
Apr 14, 2025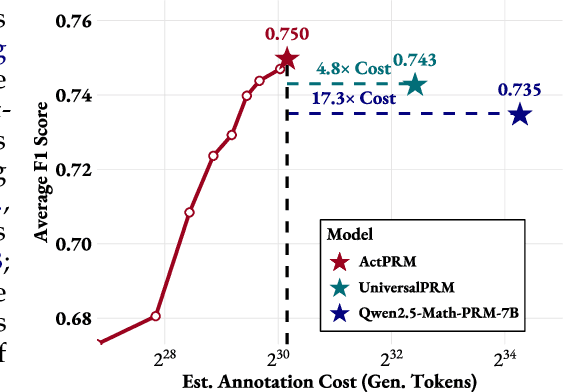
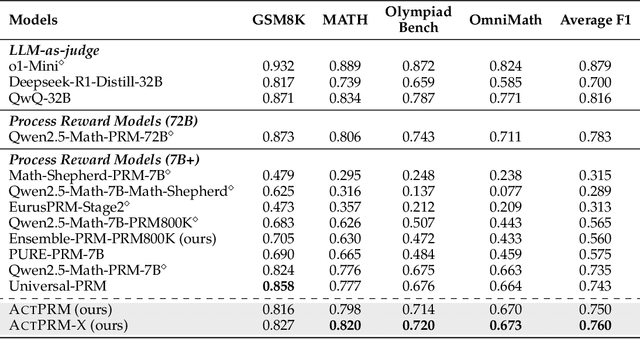
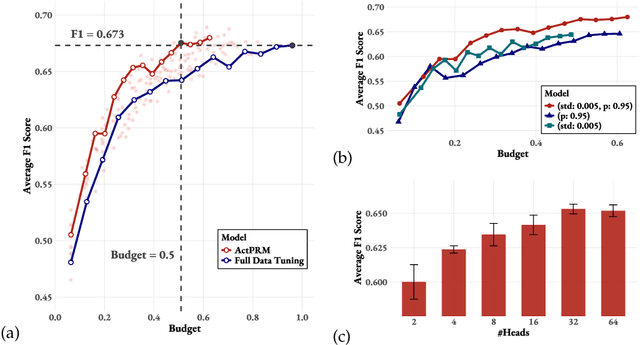
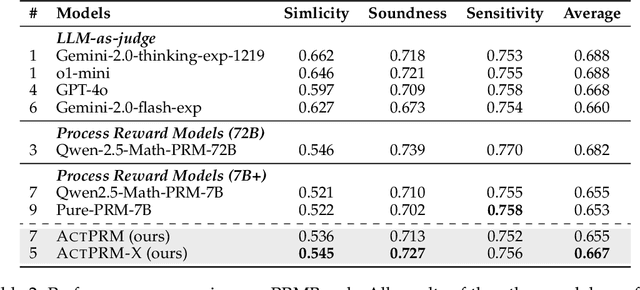
Process Reward Models (PRMs) provide step-level supervision to large language models (LLMs), but scaling up training data annotation remains challenging for both humans and LLMs. To address this limitation, we propose an active learning approach, ActPRM, which proactively selects the most uncertain samples for training, substantially reducing labeling costs. During training, we use the PRM to estimate uncertainty after the forward pass, retaining only highly uncertain data. A capable yet costly reasoning model then labels this data. Then we compute the loss with respect to the labels and update the PRM's weights. We compare ActPRM vs. vanilla fine-tuning, on a pool-based active learning setting, demonstrating that ActPRM reduces 50% annotation, but achieving the comparable or even better performance. Beyond annotation efficiency, we further advance the actively trained PRM by filtering over 1M+ math reasoning trajectories with ActPRM, retaining 60% of the data. A subsequent training on this selected dataset yields a new state-of-the-art (SOTA) PRM on ProcessBench (75.0%) and PRMBench (65.5%) compared with same sized models.
Improving Autoregressive Image Generation through Coarse-to-Fine Token Prediction
Mar 20, 2025Autoregressive models have shown remarkable success in image generation by adapting sequential prediction techniques from language modeling. However, applying these approaches to images requires discretizing continuous pixel data through vector quantization methods like VQ-VAE. To alleviate the quantization errors that existed in VQ-VAE, recent works tend to use larger codebooks. However, this will accordingly expand vocabulary size, complicating the autoregressive modeling task. This paper aims to find a way to enjoy the benefits of large codebooks without making autoregressive modeling more difficult. Through empirical investigation, we discover that tokens with similar codeword representations produce similar effects on the final generated image, revealing significant redundancy in large codebooks. Based on this insight, we propose to predict tokens from coarse to fine (CTF), realized by assigning the same coarse label for similar tokens. Our framework consists of two stages: (1) an autoregressive model that sequentially predicts coarse labels for each token in the sequence, and (2) an auxiliary model that simultaneously predicts fine-grained labels for all tokens conditioned on their coarse labels. Experiments on ImageNet demonstrate our method's superior performance, achieving an average improvement of 59 points in Inception Score compared to baselines. Notably, despite adding an inference step, our approach achieves faster sampling speeds.
Long-Context Inference with Retrieval-Augmented Speculative Decoding
Feb 27, 2025The emergence of long-context large language models (LLMs) offers a promising alternative to traditional retrieval-augmented generation (RAG) for processing extensive documents. However, the computational overhead of long-context inference, particularly in managing key-value (KV) caches, presents significant efficiency challenges. While Speculative Decoding (SD) traditionally accelerates inference using smaller draft models, its effectiveness diminishes substantially in long-context scenarios due to memory-bound KV cache operations. We present Retrieval-Augmented Speculative Decoding (RAPID), which leverages RAG for both accelerating and enhancing generation quality in long-context inference. RAPID introduces the RAG drafter-a draft LLM operating on shortened retrieval contexts-to speculate on the generation of long-context target LLMs. Our approach enables a new paradigm where same-scale or even larger LLMs can serve as RAG drafters while maintaining computational efficiency. To fully leverage the potentially superior capabilities from stronger RAG drafters, we develop an inference-time knowledge transfer dynamic that enriches the target distribution by RAG. Extensive experiments on the LLaMA-3.1 and Qwen2.5 backbones demonstrate that RAPID effectively integrates the strengths of both approaches, achieving significant performance improvements (e.g., from 39.33 to 42.83 on InfiniteBench for LLaMA-3.1-8B) with more than 2x speedups. Our analyses reveal that RAPID achieves robust acceleration beyond 32K context length and demonstrates superior generation quality in real-world applications.
LongPO: Long Context Self-Evolution of Large Language Models through Short-to-Long Preference Optimization
Feb 20, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities through pretraining and alignment. However, superior short-context LLMs may underperform in long-context scenarios due to insufficient long-context alignment. This alignment process remains challenging due to the impracticality of human annotation for extended contexts and the difficulty in balancing short- and long-context performance. To address these challenges, we introduce LongPO, that enables short-context LLMs to self-evolve to excel on long-context tasks by internally transferring short-context capabilities. LongPO harnesses LLMs to learn from self-generated short-to-long preference data, comprising paired responses generated for identical instructions with long-context inputs and their compressed short-context counterparts, respectively. This preference reveals capabilities and potentials of LLMs cultivated during short-context alignment that may be diminished in under-aligned long-context scenarios. Additionally, LongPO incorporates a short-to-long KL constraint to mitigate short-context performance decline during long-context alignment. When applied to Mistral-7B-Instruct-v0.2 from 128K to 512K context lengths, LongPO fully retains short-context performance and largely outperforms naive SFT and DPO in both long- and short-context tasks. Specifically, LongPO-trained models can achieve results on long-context benchmarks comparable to, or even surpassing, those of superior LLMs (e.g., GPT-4-128K) that involve extensive long-context annotation and larger parameter scales. Our code is available at https://github.com/DAMO-NLP-SG/LongPO.