 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Reinforcement Learning for Tool Use in Large Language Models
Mar 09, 2026While large language models (LLMs) exhibit strong reasoning abilities, their performance on complex tasks is often constrained by the limitations of their internal knowledge. A compelling approach to overcome this challenge is to augment these models with external tools -- such as Python interpreters for mathematical computations or search engines for retrieving factual information. However, enabling models to use these tools effectively remains a significant challenge. Existing methods typically rely on cold-start pipelines that begin with supervised fine-tuning (SFT), followed by reinforcement learning (RL). These approaches often require substantial amounts of labeled data for SFT, which is expensive to annotate or synthesize. In this work, we propose In-Context Reinforcement Learning (ICRL), an RL-only framework that eliminates the need for SFT by leveraging few-shot prompting during the rollout stage of RL. Specifically, ICRL introduces in-context examples within the rollout prompts to teach the model how to invoke external tools. Furthermore, as training progresses, the number of in-context examples is gradually reduced, eventually reaching a zero-shot setting where the model learns to call tools independently. We conduct extensive experiments across a range of reasoning and tool-use benchmarks. Results show that ICRL achieves state-of-the-art performance, demonstrating its effectiveness as a scalable, data-efficient alternative to traditional SFT-based pipelines.
Efficient Process Reward Model Training via Active Learning
Apr 14, 2025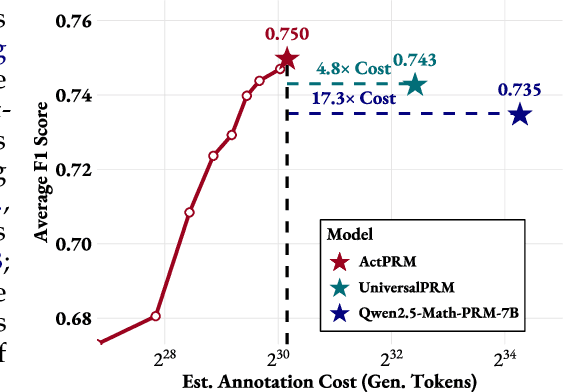
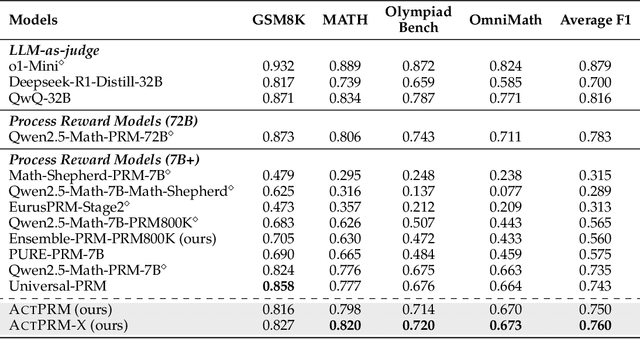
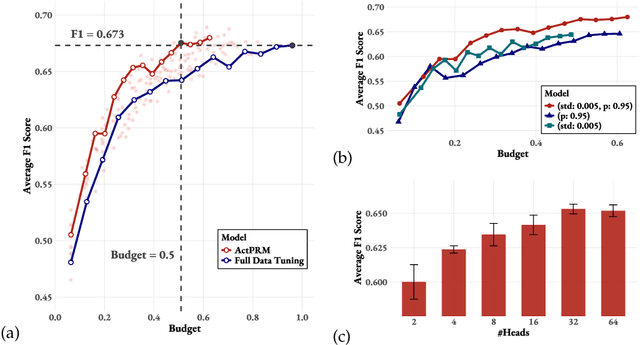
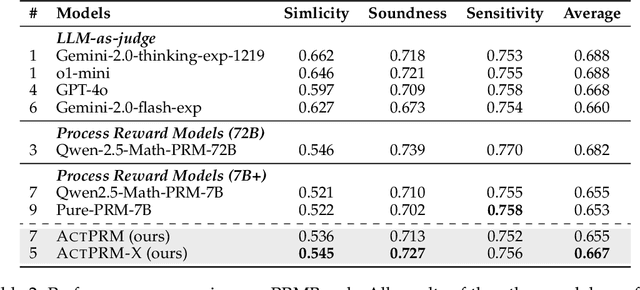
Process Reward Models (PRMs) provide step-level supervision to large language models (LLMs), but scaling up training data annotation remains challenging for both humans and LLMs. To address this limitation, we propose an active learning approach, ActPRM, which proactively selects the most uncertain samples for training, substantially reducing labeling costs. During training, we use the PRM to estimate uncertainty after the forward pass, retaining only highly uncertain data. A capable yet costly reasoning model then labels this data. Then we compute the loss with respect to the labels and update the PRM's weights. We compare ActPRM vs. vanilla fine-tuning, on a pool-based active learning setting, demonstrating that ActPRM reduces 50% annotation, but achieving the comparable or even better performance. Beyond annotation efficiency, we further advance the actively trained PRM by filtering over 1M+ math reasoning trajectories with ActPRM, retaining 60% of the data. A subsequent training on this selected dataset yields a new state-of-the-art (SOTA) PRM on ProcessBench (75.0%) and PRMBench (65.5%) compared with same sized models.
GraphFM: A Comprehensive Benchmark for Graph Foundation Model
Jun 12, 2024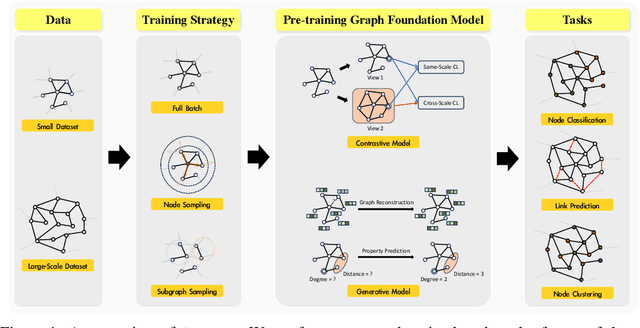
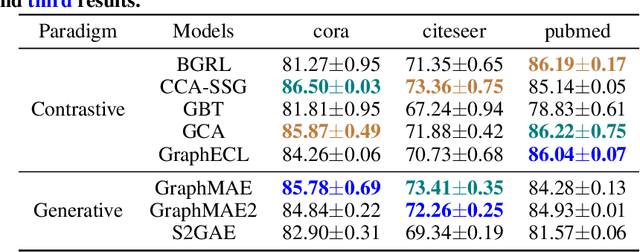
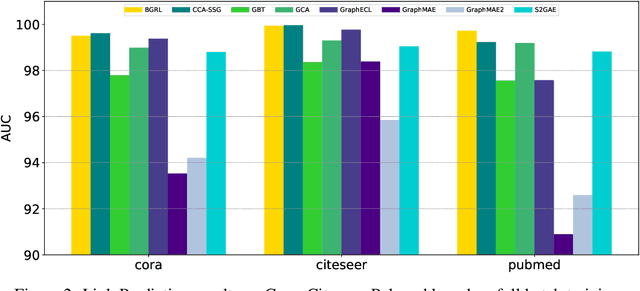
Foundation Models (FMs) serve as a general class for the development of artificial intelligence systems, offering broad potential for generalization across a spectrum of downstream tasks. Despite extensive research into self-supervised learning as the cornerstone of FMs, several outstanding issues persist in Graph Foundation Models that rely on graph self-supervised learning, namely: 1) Homogenization. The extent of generalization capability on downstream tasks remains unclear. 2) Scalability. It is unknown how effectively these models can scale to large datasets. 3) Efficiency. The training time and memory usage of these models require evaluation. 4) Training Stop Criteria. Determining the optimal stopping strategy for pre-training across multiple tasks to maximize performance on downstream tasks. To address these questions, we have constructed a rigorous benchmark that thoroughly analyzes and studies the generalization and scalability of self-supervised Graph Neural Network (GNN) models. Regarding generalization, we have implemented and compared the performance of various self-supervised GNN models, trained to generate node representations, across tasks such as node classification, link prediction, and node clustering. For scalability, we have compared the performance of various models after training using full-batch and mini-batch strategies. Additionally, we have assessed the training efficiency of these models by conducting experiments to test their GPU memory usage and throughput. Through these experiments, we aim to provide insights to motivate future research. The code for this benchmark is publicly available at https://github.com/NYUSHCS/GraphFM.
Logical Reasoning with Relation Network for Inductive Knowledge Graph Completion
Jun 03, 2024



Inductive knowledge graph completion (KGC) aims to infer the missing relation for a set of newly-coming entities that never appeared in the training set. Such a setting is more in line with reality, as real-world KGs are constantly evolving and introducing new knowledge. Recent studies have shown promising results using message passing over subgraphs to embed newly-coming entities for inductive KGC. However, the inductive capability of these methods is usually limited by two key issues. (i) KGC always suffers from data sparsity, and the situation is even exacerbated in inductive KGC where new entities often have few or no connections to the original KG. (ii) Cold-start problem. It is over coarse-grained for accurate KG reasoning to generate representations for new entities by gathering the local information from few neighbors. To this end, we propose a novel iNfOmax RelAtion Network, namely NORAN, for inductive KG completion. It aims to mine latent relation patterns for inductive KG completion. Specifically, by centering on relations, NORAN provides a hyper view towards KG modeling, where the correlations between relations can be naturally captured as entity-independent logical evidence to conduct inductive KGC. Extensive experiment results on five benchmarks show that our framework substantially outperforms the state-of-the-art KGC methods.
SimTeG: A Frustratingly Simple Approach Improves Textual Graph Learning
Aug 03, 2023



Textual graphs (TGs) are graphs whose nodes correspond to text (sentences or documents), which are widely prevalent. The representation learning of TGs involves two stages: (i) unsupervised feature extraction and (ii) supervised graph representation learning. In recent years, extensive efforts have been devoted to the latter stage, where Graph Neural Networks (GNNs) have dominated. However, the former stage for most existing graph benchmarks still relies on traditional feature engineering techniques. More recently, with the rapid development of language models (LMs), researchers have focused on leveraging LMs to facilitate the learning of TGs, either by jointly training them in a computationally intensive framework (merging the two stages), or designing complex self-supervised training tasks for feature extraction (enhancing the first stage). In this work, we present SimTeG, a frustratingly Simple approach for Textual Graph learning that does not innovate in frameworks, models, and tasks. Instead, we first perform supervised parameter-efficient fine-tuning (PEFT) on a pre-trained LM on the downstream task, such as node classification. We then generate node embeddings using the last hidden states of finetuned LM. These derived features can be further utilized by any GNN for training on the same task. We evaluate our approach on two fundamental graph representation learning tasks: node classification and link prediction. Through extensive experiments, we show that our approach significantly improves the performance of various GNNs on multiple graph benchmarks.
Contrastive Knowledge Graph Error Detection
Nov 18, 2022
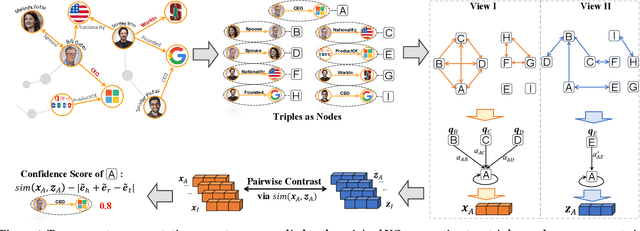
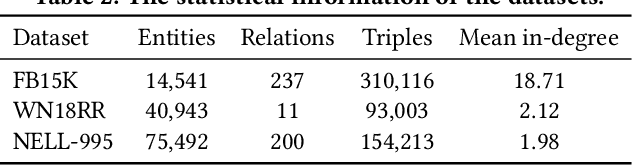
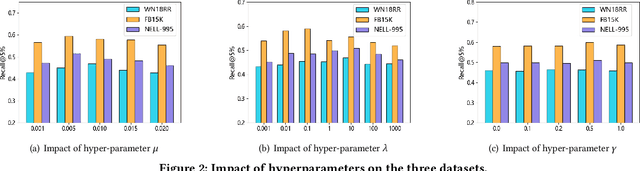
Knowledge Graph (KG) errors introduce non-negligible noise, severely affecting KG-related downstream tasks. Detecting errors in KGs is challenging since the patterns of errors are unknown and diverse, while ground-truth labels are rare or even unavailable. A traditional solution is to construct logical rules to verify triples, but it is not generalizable since different KGs have distinct rules with domain knowledge involved. Recent studies focus on designing tailored detectors or ranking triples based on KG embedding loss. However, they all rely on negative samples for training, which are generated by randomly replacing the head or tail entity of existing triples. Such a negative sampling strategy is not enough for prototyping practical KG errors, e.g., (Bruce_Lee, place_of_birth, China), in which the three elements are often relevant, although mismatched. We desire a more effective unsupervised learning mechanism tailored for KG error detection. To this end, we propose a novel framework - ContrAstive knowledge Graph Error Detection (CAGED). It introduces contrastive learning into KG learning and provides a novel way of modeling KG. Instead of following the traditional setting, i.e., considering entities as nodes and relations as semantic edges, CAGED augments a KG into different hyper-views, by regarding each relational triple as a node. After joint training with KG embedding and contrastive learning loss, CAGED assesses the trustworthiness of each triple based on two learning signals, i.e., the consistency of triple representations across multi-views and the self-consistency within the triple. Extensive experiments on three real-world KGs show that CAGED outperforms state-of-the-art methods in KG error detection. Our codes and datasets are available at https://github.com/Qing145/CAGED.git.
A Comprehensive Study on Large-Scale Graph Training: Benchmarking and Rethinking
Oct 14, 2022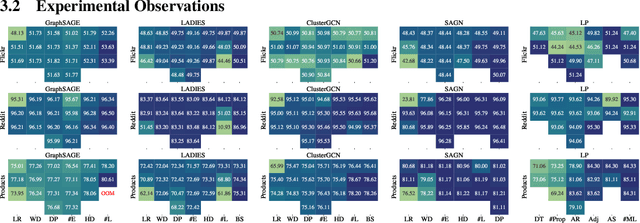
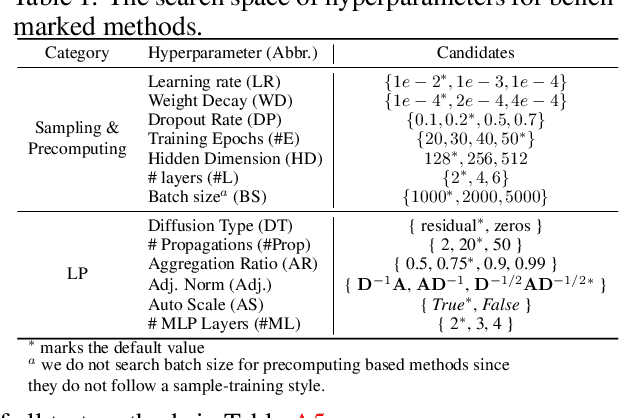

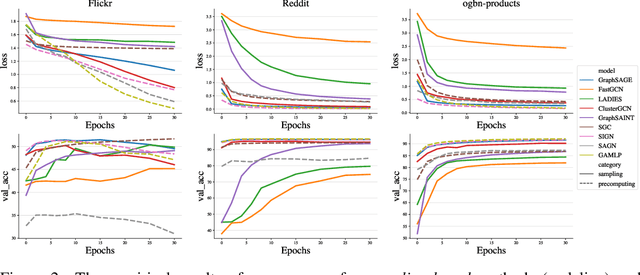
Large-scale graph training is a notoriously challenging problem for graph neural networks (GNNs). Due to the nature of evolving graph structures into the training process, vanilla GNNs usually fail to scale up, limited by the GPU memory space. Up to now, though numerous scalable GNN architectures have been proposed, we still lack a comprehensive survey and fair benchmark of this reservoir to find the rationale for designing scalable GNNs. To this end, we first systematically formulate the representative methods of large-scale graph training into several branches and further establish a fair and consistent benchmark for them by a greedy hyperparameter searching. In addition, regarding efficiency, we theoretically evaluate the time and space complexity of various branches and empirically compare them w.r.t GPU memory usage, throughput, and convergence. Furthermore, We analyze the pros and cons for various branches of scalable GNNs and then present a new ensembling training manner, named EnGCN, to address the existing issues. Remarkably, our proposed method has achieved new state-of-the-art (SOTA) performance on large-scale datasets. Our code is available at https://github.com/VITA-Group/Large_Scale_GCN_Benchmarking.
Bag of Tricks for Training Deeper Graph Neural Networks: A Comprehensive Benchmark Study
Aug 24, 2021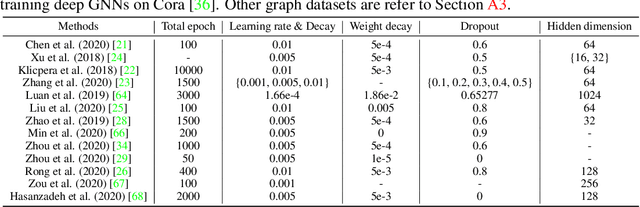
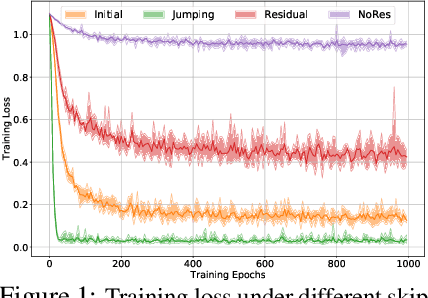

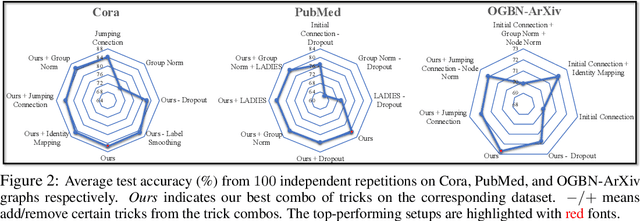
Training deep graph neural networks (GNNs) is notoriously hard. Besides the standard plights in training deep architectures such as vanishing gradients and overfitting, the training of deep GNNs also uniquely suffers from over-smoothing, information squashing, and so on, which limits their potential power on large-scale graphs. Although numerous efforts are proposed to address these limitations, such as various forms of skip connections, graph normalization, and random dropping, it is difficult to disentangle the advantages brought by a deep GNN architecture from those "tricks" necessary to train such an architecture. Moreover, the lack of a standardized benchmark with fair and consistent experimental settings poses an almost insurmountable obstacle to gauging the effectiveness of new mechanisms. In view of those, we present the first fair and reproducible benchmark dedicated to assessing the "tricks" of training deep GNNs. We categorize existing approaches, investigate their hyperparameter sensitivity, and unify the basic configuration. Comprehensive evaluations are then conducted on tens of representative graph datasets including the recent large-scale Open Graph Benchmark (OGB), with diverse deep GNN backbones. Based on synergistic studies, we discover the combo of superior training tricks, that lead us to attain the new state-of-the-art results for deep GCNs, across multiple representative graph datasets. We demonstrate that an organic combo of initial connection, identity mapping, group and batch normalization has the most ideal performance on large datasets. Experiments also reveal a number of "surprises" when combining or scaling up some of the tricks. All codes are available at https://github.com/VITA-Group/Deep_GCN_Benchmarking.
A Comprehensive Survey on Transfer Learning
Dec 17, 2019
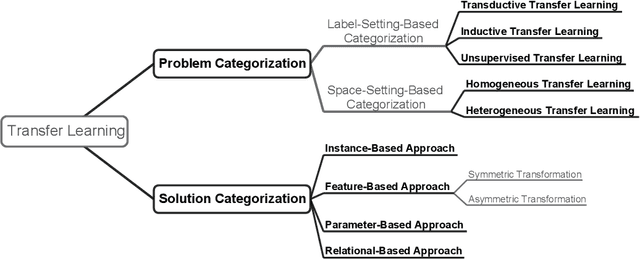
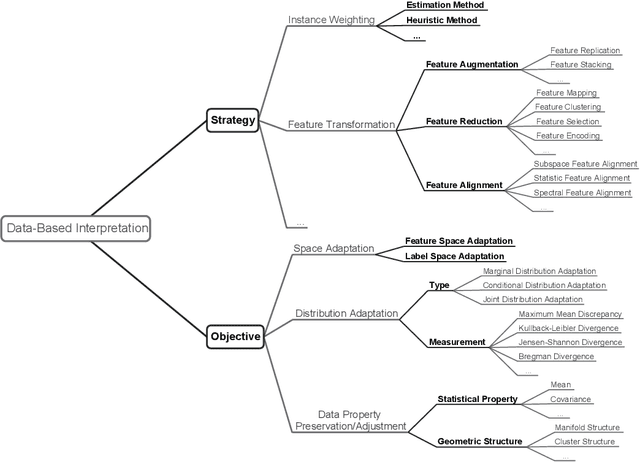

Transfer learning aims at improving the performance of target learners on target domains by transferring the knowledge contained in different but related source domains. In this way, the dependence on a large number of target domain data can be reduced for constructing target learners. Due to the wide application prospects, transfer learning has become a popular and promising area in machine learning. Although there are already some valuable and impressive surveys on transfer learning, these surveys introduce approaches in a relatively isolated way and lack the recent advances in transfer learning. As the rapid expansion of the transfer learning area, it is both necessary and challenging to comprehensively review the relevant studies. This survey attempts to connect and systematize the existing transfer learning researches, as well as to summarize and interpret the mechanisms and the strategies in a comprehensive way, which may help readers have a better understanding of the current research status and ideas. Different from previous surveys, this survey paper reviews over forty representative transfer learning approaches from the perspectives of data and model. The applications of transfer learning are also briefly introduced. In order to show the performance of different transfer learning models, twenty representative transfer learning models are used for experiments. The models are performed on three different datasets, i.e., Amazon Reviews, Reuters-21578, and Office-31. And the experimental results demonstrate the importance of selecting appropriate transfer learning models for different applications in practice.
Transfer Learning Toolkit: Primers and Benchmarks
Nov 20, 2019

The transfer learning toolkit wraps the codes of 17 transfer learning models and provides integrated interfaces, allowing users to use those models by calling a simple function. It is easy for primary researchers to use this toolkit and to choose proper models for real-world applications. The toolkit is written in Python and distributed under MIT open source license. In this paper, the current state of this toolkit is described and the necessary environment setting and usage are introduced.