 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstructCoder: Empowering Language Models for Code Editing
Oct 31, 2023Code editing encompasses a variety of pragmatic tasks that developers deal with daily. Despite its relevance and practical usefulness, automatic code editing remains an underexplored area in the evolution of deep learning models, partly due to data scarcity. In this work, we explore the use of large language models (LLMs) to edit code based on user instructions, covering a broad range of implicit tasks such as comment insertion, code optimization, and code refactoring. To facilitate this, we introduce InstructCoder, the first dataset designed to adapt LLMs for general-purpose code editing, containing highdiversity code-editing tasks. It consists of over 114,000 instruction-input-output triplets and covers multiple distinct code editing scenarios. The dataset is systematically expanded through an iterative process that commences with code editing data sourced from GitHub commits as seed tasks. Seed and generated tasks are used subsequently to prompt ChatGPT for more task data. Our experiments demonstrate that open-source LLMs fine-tuned on InstructCoder can edit code correctly based on users' instructions most of the time, exhibiting unprecedented code-editing performance levels. Such results suggest that proficient instruction-finetuning can lead to significant amelioration in code editing abilities. The dataset and the source code are available at https://github.com/qishenghu/CodeInstruct.
SimTeG: A Frustratingly Simple Approach Improves Textual Graph Learning
Aug 03, 2023



Textual graphs (TGs) are graphs whose nodes correspond to text (sentences or documents), which are widely prevalent. The representation learning of TGs involves two stages: (i) unsupervised feature extraction and (ii) supervised graph representation learning. In recent years, extensive efforts have been devoted to the latter stage, where Graph Neural Networks (GNNs) have dominated. However, the former stage for most existing graph benchmarks still relies on traditional feature engineering techniques. More recently, with the rapid development of language models (LMs), researchers have focused on leveraging LMs to facilitate the learning of TGs, either by jointly training them in a computationally intensive framework (merging the two stages), or designing complex self-supervised training tasks for feature extraction (enhancing the first stage). In this work, we present SimTeG, a frustratingly Simple approach for Textual Graph learning that does not innovate in frameworks, models, and tasks. Instead, we first perform supervised parameter-efficient fine-tuning (PEFT) on a pre-trained LM on the downstream task, such as node classification. We then generate node embeddings using the last hidden states of finetuned LM. These derived features can be further utilized by any GNN for training on the same task. We evaluate our approach on two fundamental graph representation learning tasks: node classification and link prediction. Through extensive experiments, we show that our approach significantly improves the performance of various GNNs on multiple graph benchmarks.
Multi-Source Test-Time Adaptation as Dueling Bandits for Extractive Question Answering
Jun 11, 2023In this work, we study multi-source test-time model adaptation from user feedback, where K distinct models are established for adaptation. To allow efficient adaptation, we cast the problem as a stochastic decision-making process, aiming to determine the best adapted model after adaptation. We discuss two frameworks: multi-armed bandit learning and multi-armed dueling bandits. Compared to multi-armed bandit learning, the dueling framework allows pairwise collaboration among K models, which is solved by a novel method named Co-UCB proposed in this work. Experiments on six datasets of extractive question answering (QA) show that the dueling framework using Co-UCB is more effective than other strong baselines for our studied problem.
Automatic Model Selection with Large Language Models for Reasoning
May 23, 2023Chain-of-Thought and Program-Aided Language Models represent two distinct reasoning methods, each with its own strengths and weaknesses. We demonstrate that it is possible to combine the best of both worlds by using different models for different problems, employing a large language model (LLM) to perform model selection. Through a theoretical analysis, we discover that the performance improvement is determined by the differences between the combined methods and the success rate of choosing the correct model. On eight reasoning datasets, our proposed approach shows significant improvements. Furthermore, we achieve new state-of-the-art results on GSM8K and SVAMP with accuracies of 96.5% and 93.7%, respectively. Our code is publicly available at https://github.com/XuZhao0/Model-Selection-Reasoning.
Decomposition Enhances Reasoning via Self-Evaluation Guided Decoding
May 02, 2023



We endow Large Language Models (LLMs) with fine-grained self-evaluation to refine multi-step reasoning inference. We propose an effective prompting approach that integrates self-evaluation guidance through stochastic beam search. Our approach explores the reasoning search space using a well-calibrated automatic criterion. This enables an efficient search to produce higher-quality final predictions. With the self-evaluation guided stochastic beam search, we also balance the quality-diversity trade-off in the generation of reasoning chains. This allows our approach to adapt well with majority voting and surpass the corresponding Codex-backboned baselines by $6.34\%$, $9.56\%$, and $5.46\%$ on the GSM8K, AQuA, and StrategyQA benchmarks, respectively, in few-shot accuracy. Analysis of our decompositional reasoning finds it pinpoints logic failures and leads to higher consistency and robustness. Our code is publicly available at https://github.com/YuxiXie/SelfEval-Guided-Decoding.
Meta Pseudo Labels
Apr 23, 2020
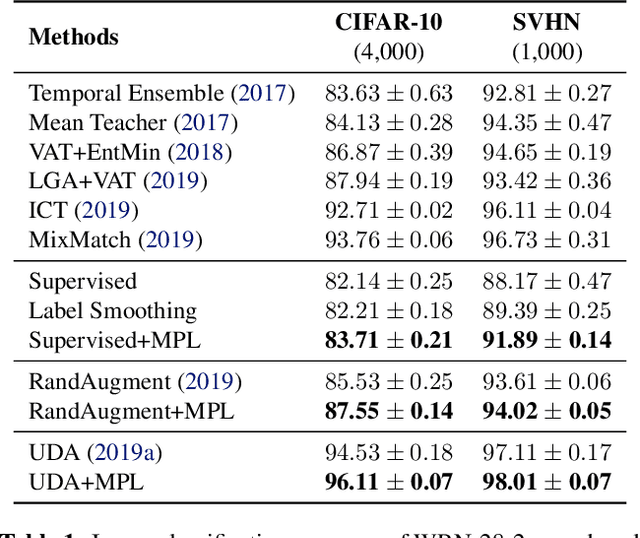

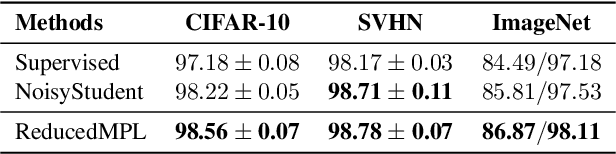
Many training algorithms of a deep neural network can be interpreted as minimizing the cross entropy loss between the prediction made by the network and a target distribution. In supervised learning, this target distribution is typically the ground-truth one-hot vector. In semi-supervised learning, this target distribution is typically generated by a pre-trained teacher model to train the main network. In this work, instead of using such predefined target distributions, we show that learning to adjust the target distribution based on the learning state of the main network can lead to better performances. In particular, we propose an efficient meta-learning algorithm, which encourages the teacher to adjust the target distributions of training examples in the manner that improves the learning of the main network. The teacher is updated by policy gradients computed by evaluating the main network on a held-out validation set. Our experiments demonstrate substantial improvements over strong baselines and establish state-ofthe-art performance on CIFAR-10, SVHN, and ImageNet. For instance, with ResNets on small datasets, we achieve 96.1% on CIFAR-10 with 4,000 labeled examples and 73.9% top-1 on ImageNet with 10% examples. Meanwhile, with EfficientNet on full datasets plus extra unlabeled data, we attain 98.6% accuracy on CIFAR-10 and 86.9% top-1 accuracy on ImageNet.
Self-training with Noisy Student improves ImageNet classification
Nov 11, 2019
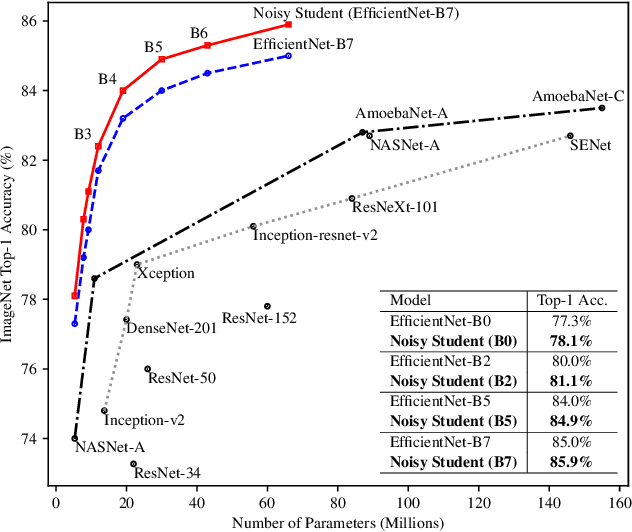
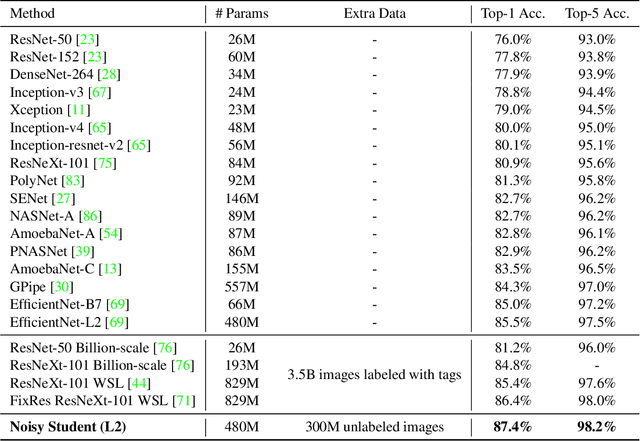

We present a simple self-training method that achieves 87.4% top-1 accuracy on ImageNet, which is 1.0% better than the state-of-the-art model that requires 3.5B weakly labeled Instagram images. On robustness test sets, it improves ImageNet-A top-1 accuracy from 16.6% to 74.2%, reduces ImageNet-C mean corruption error from 45.7 to 31.2, and reduces ImageNet-P mean flip rate from 27.8 to 16.1. To achieve this result, we first train an EfficientNet model on labeled ImageNet images and use it as a teacher to generate pseudo labels on 300M unlabeled images. We then train a larger EfficientNet as a student model on the combination of labeled and pseudo labeled images. We iterate this process by putting back the student as the teacher. During the generation of the pseudo labels, the teacher is not noised so that the pseudo labels are as good as possible. But during the learning of the student, we inject noise such as data augmentation, dropout, stochastic depth to the student so that the noised student is forced to learn harder from the pseudo labels.
Unsupervised Data Augmentation
Apr 29, 2019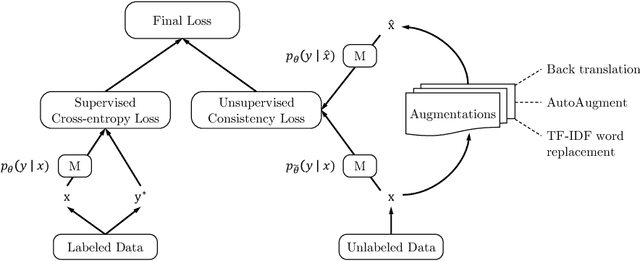
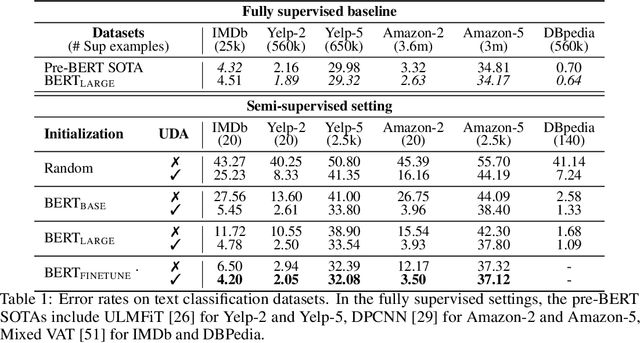
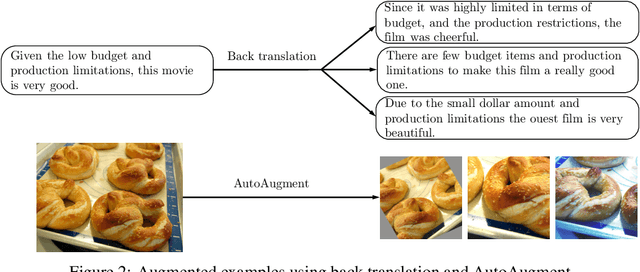

Despite its success, deep learning still needs large labeled datasets to succeed. Data augmentation has shown much promise in alleviating the need for more labeled data, but it so far has mostly been applied in supervised settings and achieved limited gains. In this work, we propose to apply data augmentation to unlabeled data in a semi-supervised learning setting. Our method, named Unsupervised Data Augmentation or UDA, encourages the model predictions to be consistent between an unlabeled example and an augmented unlabeled example. Unlike previous methods that use random noise such as Gaussian noise or dropout noise, UDA has a small twist in that it makes use of harder and more realistic noise generated by state-of-the-art data augmentation methods. This small twist leads to substantial improvements on six language tasks and three vision tasks even when the labeled set is extremely small. For example, on the IMDb text classification dataset, with only 20 labeled examples, UDA outperforms the state-of-the-art model trained on 25,000 labeled examples. On standard semi-supervised learning benchmarks, CIFAR-10 with 4,000 examples and SVHN with 1,000 examples, UDA outperforms all previous approaches and reduces more than $30\%$ of the error rates of state-of-the-art methods: going from 7.66% to 5.27% and from 3.53% to 2.46% respectively. UDA also works well on datasets that have a lot of labeled data. For example, on ImageNet, with 1.3M extra unlabeled data, UDA improves the top-1/top-5 accuracy from 78.28/94.36% to 79.04/94.45% when compared to AutoAugment.
The Profiling Machine: Active Generalization over Knowledge
Oct 01, 2018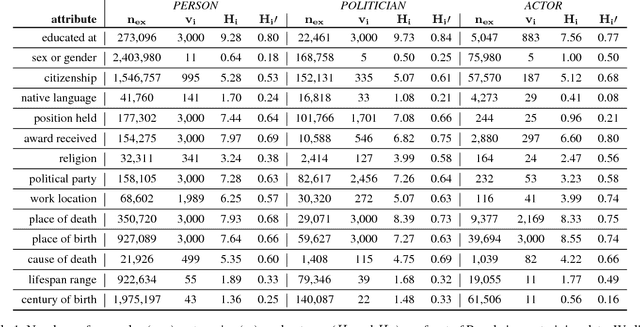
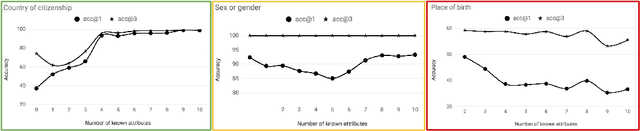
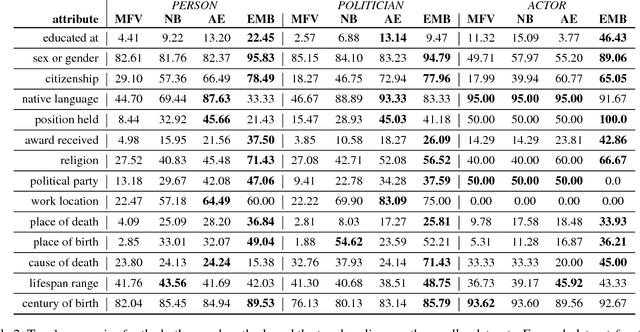
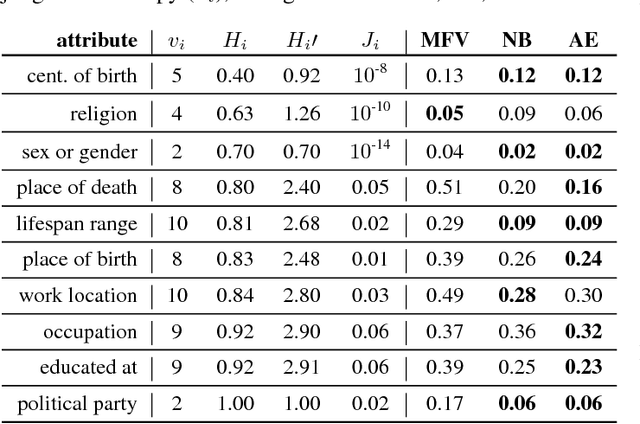
The human mind is a powerful multifunctional knowledge storage and management system that performs generalization, type inference, anomaly detection, stereotyping, and other tasks. A dynamic KR system that appropriately profiles over sparse inputs to provide complete expectations for unknown facets can help with all these tasks. In this paper, we introduce the task of profiling, inspired by theories and findings in social psychology about the potential of profiles for reasoning and information processing. We describe two generic state-of-the-art neural architectures that can be easily instantiated as profiling machines to generate expectations and applied to any kind of knowledge to fill gaps. We evaluate these methods against Wikidata and crowd expectations, and compare the results to gain insight in the nature of knowledge captured by various profiling methods. We make all code and data available to facilitate future research.
Fast and Simple Mixture of Softmaxes with BPE and Hybrid-LightRNN for Language Generation
Sep 25, 2018
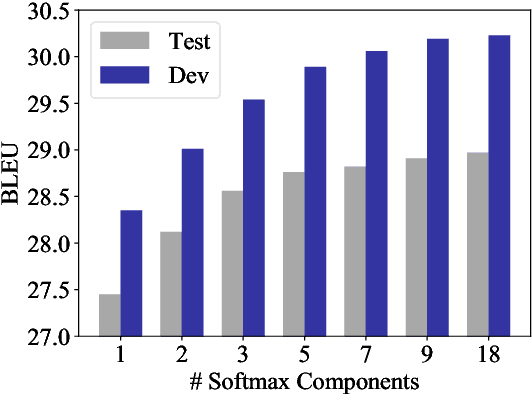
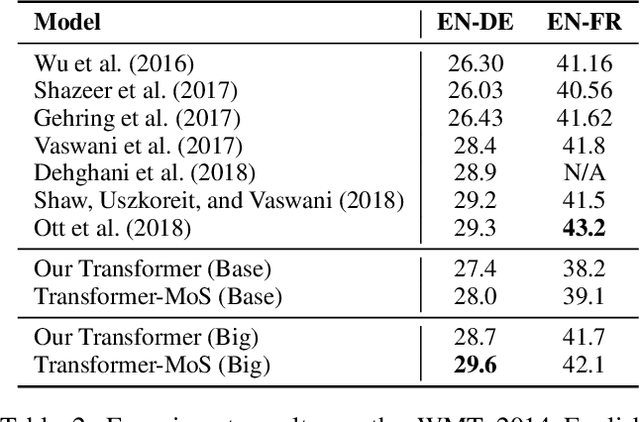

Mixture of Softmaxes (MoS) has been shown to be effective at addressing the expressiveness limitation of Softmax-based models. Despite the known advantage, MoS is practically sealed by its large consumption of memory and computational time due to the need of computing multiple Softmaxes. In this work, we set out to unleash the power of MoS in practical applications by investigating improved word coding schemes, which could effectively reduce the vocabulary size and hence relieve the memory and computation burden. We show both BPE and our proposed Hybrid-LightRNN lead to improved encoding mechanisms that can halve the time and memory consumption of MoS without performance losses. With MoS, we achieve an improvement of 1.5 BLEU scores on IWSLT 2014 German-to-English corpus and an improvement of 0.76 CIDEr score on image captioning. Moreover, on the larger WMT 2014 machine translation dataset, our MoS-boosted Transformer yields 29.5 BLEU score for English-to-German and 42.1 BLEU score for English-to-French, outperforming the single-Softmax Transformer by 0.8 and 0.4 BLEU scores respectively and achieving the state-of-the-art result on WMT 2014 English-to-German task.