 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic World Modeling: Foundations, Capabilities, Laws, and Beyond
Apr 24, 2026As AI systems move from generating text to accomplishing goals through sustained interaction, the ability to model environment dynamics becomes a central bottleneck. Agents that manipulate objects, navigate software, coordinate with others, or design experiments require predictive environment models, yet the term world model carries different meanings across research communities. We introduce a "levels x laws" taxonomy organized along two axes. The first defines three capability levels: L1 Predictor, which learns one-step local transition operators; L2 Simulator, which composes them into multi-step, action-conditioned rollouts that respect domain laws; and L3 Evolver, which autonomously revises its own model when predictions fail against new evidence. The second identifies four governing-law regimes: physical, digital, social, and scientific. These regimes determine what constraints a world model must satisfy and where it is most likely to fail. Using this framework, we synthesize over 400 works and summarize more than 100 representative systems spanning model-based reinforcement learning, video generation, web and GUI agents, multi-agent social simulation, and AI-driven scientific discovery. We analyze methods, failure modes, and evaluation practices across level-regime pairs, propose decision-centric evaluation principles and a minimal reproducible evaluation package, and outline architectural guidance, open problems, and governance challenges. The resulting roadmap connects previously isolated communities and charts a path from passive next-step prediction toward world models that can simulate, and ultimately reshape, the environments in which agents operate.
STARE at the Structure: Steering ICL Exemplar Selection with Structural Alignment
Aug 28, 2025In-Context Learning (ICL) has become a powerful paradigm that enables LLMs to perform a wide range of tasks without task-specific fine-tuning. However, the effectiveness of ICL heavily depends on the quality of exemplar selection. In particular, for structured prediction tasks such as semantic parsing, existing ICL selection strategies often overlook structural alignment, leading to suboptimal performance and poor generalization. To address this issue, we propose a novel two-stage exemplar selection strategy that achieves a strong balance between efficiency, generalizability, and performance. First, we fine-tune a BERT-based retriever using structure-aware supervision, guiding it to select exemplars that are both semantically relevant and structurally aligned. Then, we enhance the retriever with a plug-in module, which amplifies syntactically meaningful information in the hidden representations. This plug-in is model-agnostic, requires minimal overhead, and can be seamlessly integrated into existing pipelines. Experiments on four benchmarks spanning three semantic parsing tasks demonstrate that our method consistently outperforms existing baselines with multiple recent LLMs as inference-time models.
Coordinating Search-Informed Reasoning and Reasoning-Guided Search in Claim Verification
Jun 09, 2025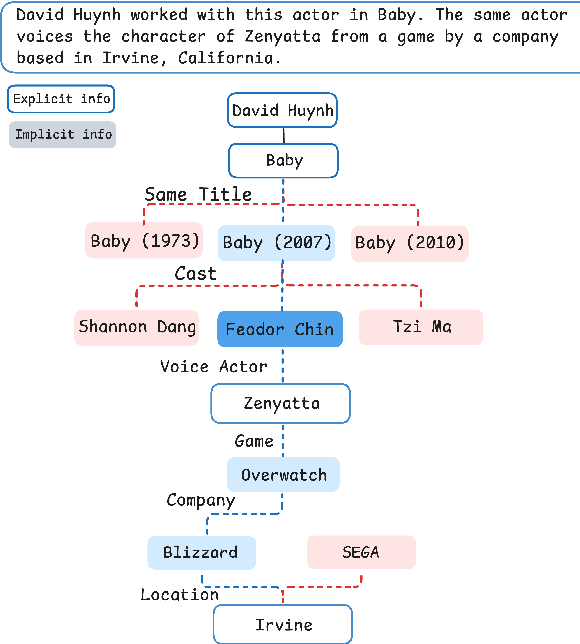
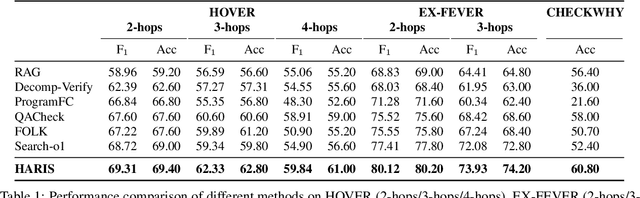
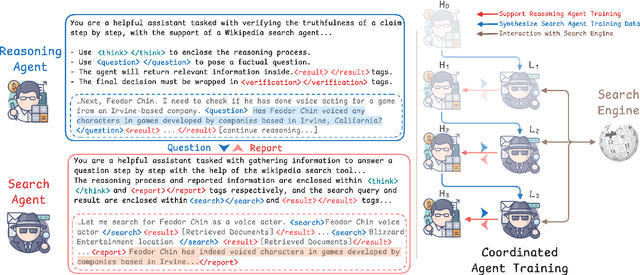
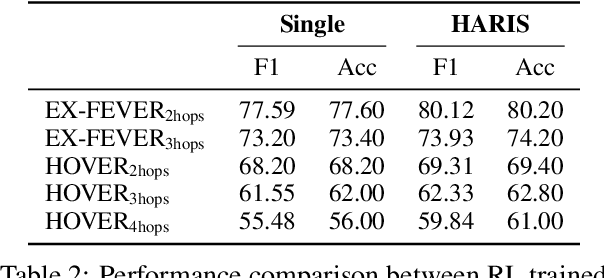
Multi-hop claim verification is inherently challenging, requiring multi-step reasoning to construct verification chains while iteratively searching for information to uncover hidden bridging facts. This process is fundamentally interleaved, as effective reasoning relies on dynamically retrieved evidence, while effective search demands reasoning to refine queries based on partial information. To achieve this, we propose Hierarchical Agent Reasoning and Information Search (HARIS), explicitly modeling the coordinated process of reasoning-driven searching and search-informed reasoning. HARIS consists of a high-level reasoning agent that focuses on constructing the main verification chain, generating factual questions when more information is needed, and a low-level search agent that iteratively retrieves more information, refining its search based on intermediate findings. This design allows each agent to specialize in its respective task, enhancing verification accuracy and interpretability. HARIS is trained using reinforcement learning with outcome-based rewards. Experimental results on the EX-FEVER and HOVER benchmarks demonstrate that HARIS achieves strong performance, greatly advancing multi-hop claim verification.
BOOST: Bootstrapping Strategy-Driven Reasoning Programs for Program-Guided Fact-Checking
Apr 03, 2025



Program-guided reasoning has shown promise in complex claim fact-checking by decomposing claims into function calls and executing reasoning programs. However, prior work primarily relies on few-shot in-context learning (ICL) with ad-hoc demonstrations, which limit program diversity and require manual design with substantial domain knowledge. Fundamentally, the underlying principles of effective reasoning program generation still remain underexplored, making it challenging to construct effective demonstrations. To address this, we propose BOOST, a bootstrapping-based framework for few-shot reasoning program generation. BOOST explicitly integrates claim decomposition and information-gathering strategies as structural guidance for program generation, iteratively refining bootstrapped demonstrations in a strategy-driven and data-centric manner without human intervention. This enables a seamless transition from zero-shot to few-shot strategic program-guided learning, enhancing interpretability and effectiveness. Experimental results show that BOOST outperforms prior few-shot baselines in both zero-shot and few-shot settings for complex claim verification.
Just What You Desire: Constrained Timeline Summarization with Self-Reflection for Enhanced Relevance
Dec 23, 2024



Given news articles about an entity, such as a public figure or organization, timeline summarization (TLS) involves generating a timeline that summarizes the key events about the entity. However, the TLS task is too underspecified, since what is of interest to each reader may vary, and hence there is not a single ideal or optimal timeline. In this paper, we introduce a novel task, called Constrained Timeline Summarization (CTLS), where a timeline is generated in which all events in the timeline meet some constraint. An example of a constrained timeline concerns the legal battles of Tiger Woods, where only events related to his legal problems are selected to appear in the timeline. We collected a new human-verified dataset of constrained timelines involving 47 entities and 5 constraints per entity. We propose an approach that employs a large language model (LLM) to summarize news articles according to a specified constraint and cluster them to identify key events to include in a constrained timeline. In addition, we propose a novel self-reflection method during summary generation, demonstrating that this approach successfully leads to improved performance.
MMCode: Evaluating Multi-Modal Code Large Language Models with Visually Rich Programming Problems
Apr 15, 2024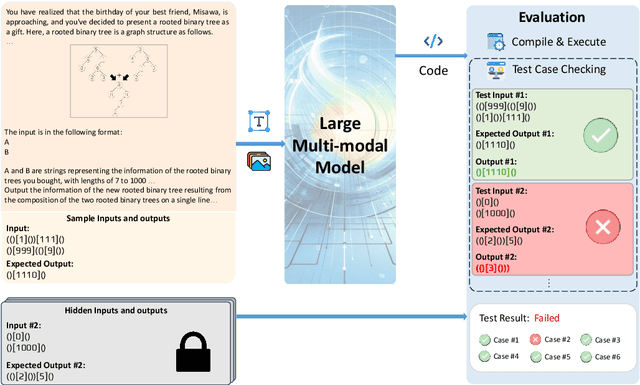
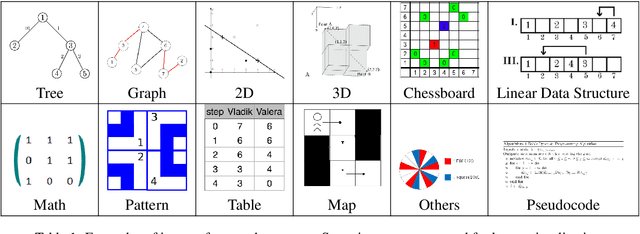
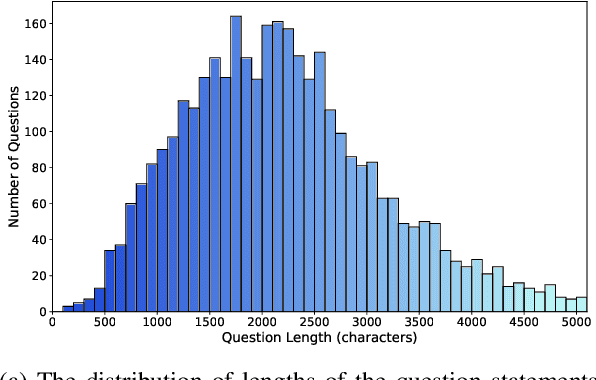
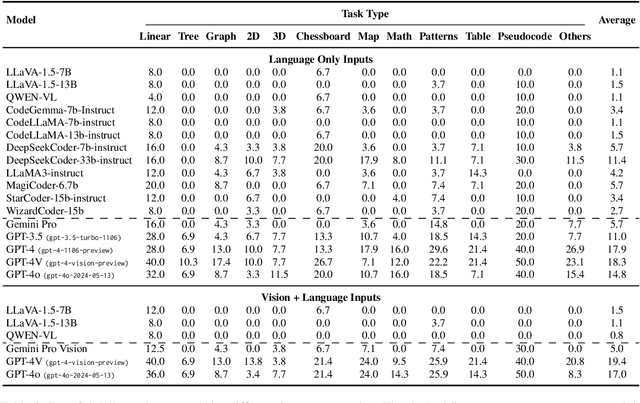
Programming often involves converting detailed and complex specifications into code, a process during which developers typically utilize visual aids to more effectively convey concepts. While recent developments in Large Multimodal Models have demonstrated remarkable abilities in visual reasoning and mathematical tasks, there is little work on investigating whether these models can effectively interpret visual elements for code generation. To this end, we present MMCode, the first multi-modal coding dataset for evaluating algorithmic problem-solving skills in visually rich contexts. MMCode contains 3,548 questions and 6,620 images collected from real-world programming challenges harvested from 10 code competition websites, presenting significant challenges due to the extreme demand for reasoning abilities. Our experiment results show that current state-of-the-art models struggle to solve these problems. The results highlight the lack of powerful vision-code models, and we hope MMCode can serve as an inspiration for future works in this domain. The data and code are publicly available at https://github.com/happylkx/MMCode.
InstructCoder: Empowering Language Models for Code Editing
Oct 31, 2023Code editing encompasses a variety of pragmatic tasks that developers deal with daily. Despite its relevance and practical usefulness, automatic code editing remains an underexplored area in the evolution of deep learning models, partly due to data scarcity. In this work, we explore the use of large language models (LLMs) to edit code based on user instructions, covering a broad range of implicit tasks such as comment insertion, code optimization, and code refactoring. To facilitate this, we introduce InstructCoder, the first dataset designed to adapt LLMs for general-purpose code editing, containing highdiversity code-editing tasks. It consists of over 114,000 instruction-input-output triplets and covers multiple distinct code editing scenarios. The dataset is systematically expanded through an iterative process that commences with code editing data sourced from GitHub commits as seed tasks. Seed and generated tasks are used subsequently to prompt ChatGPT for more task data. Our experiments demonstrate that open-source LLMs fine-tuned on InstructCoder can edit code correctly based on users' instructions most of the time, exhibiting unprecedented code-editing performance levels. Such results suggest that proficient instruction-finetuning can lead to significant amelioration in code editing abilities. The dataset and the source code are available at https://github.com/qishenghu/CodeInstruct.