 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic World Modeling: Foundations, Capabilities, Laws, and Beyond
Apr 24, 2026As AI systems move from generating text to accomplishing goals through sustained interaction, the ability to model environment dynamics becomes a central bottleneck. Agents that manipulate objects, navigate software, coordinate with others, or design experiments require predictive environment models, yet the term world model carries different meanings across research communities. We introduce a "levels x laws" taxonomy organized along two axes. The first defines three capability levels: L1 Predictor, which learns one-step local transition operators; L2 Simulator, which composes them into multi-step, action-conditioned rollouts that respect domain laws; and L3 Evolver, which autonomously revises its own model when predictions fail against new evidence. The second identifies four governing-law regimes: physical, digital, social, and scientific. These regimes determine what constraints a world model must satisfy and where it is most likely to fail. Using this framework, we synthesize over 400 works and summarize more than 100 representative systems spanning model-based reinforcement learning, video generation, web and GUI agents, multi-agent social simulation, and AI-driven scientific discovery. We analyze methods, failure modes, and evaluation practices across level-regime pairs, propose decision-centric evaluation principles and a minimal reproducible evaluation package, and outline architectural guidance, open problems, and governance challenges. The resulting roadmap connects previously isolated communities and charts a path from passive next-step prediction toward world models that can simulate, and ultimately reshape, the environments in which agents operate.
Learning Query-Aware Budget-Tier Routing for Runtime Agent Memory
Feb 05, 2026Memory is increasingly central to Large Language Model (LLM) agents operating beyond a single context window, yet most existing systems rely on offline, query-agnostic memory construction that can be inefficient and may discard query-critical information. Although runtime memory utilization is a natural alternative, prior work often incurs substantial overhead and offers limited explicit control over the performance-cost trade-off. In this work, we present \textbf{BudgetMem}, a runtime agent memory framework for explicit, query-aware performance-cost control. BudgetMem structures memory processing as a set of memory modules, each offered in three budget tiers (i.e., \textsc{Low}/\textsc{Mid}/\textsc{High}). A lightweight router performs budget-tier routing across modules to balance task performance and memory construction cost, which is implemented as a compact neural policy trained with reinforcement learning. Using BudgetMem as a unified testbed, we study three complementary strategies for realizing budget tiers: implementation (method complexity), reasoning (inference behavior), and capacity (module model size). Across LoCoMo, LongMemEval, and HotpotQA, BudgetMem surpasses strong baselines when performance is prioritized (i.e., high-budget setting), and delivers better accuracy-cost frontiers under tighter budgets. Moreover, our analysis disentangles the strengths and weaknesses of different tiering strategies, clarifying when each axis delivers the most favorable trade-offs under varying budget regimes.
Self-Verification Dilemma: Experience-Driven Suppression of Overused Checking in LLM Reasoning
Feb 03, 2026Large Reasoning Models (LRMs) achieve strong performance by generating long reasoning traces with reflection. Through a large-scale empirical analysis, we find that a substantial fraction of reflective steps consist of self-verification (recheck) that repeatedly confirm intermediate results. These rechecks occur frequently across models and benchmarks, yet the vast majority are confirmatory rather than corrective, rarely identifying errors and altering reasoning outcomes. This reveals a mismatch between how often self-verification is activated and how often it is actually useful. Motivated by this, we propose a novel, experience-driven test-time framework that reduces the overused verification. Our method detects the activation of recheck behavior, consults an offline experience pool of past verification outcomes, and estimates whether a recheck is likely unnecessary via efficient retrieval. When historical experience suggests unnecessary, a suppression signal redirects the model to proceed. Across multiple model and benchmarks, our approach reduces token usage up to 20.3% while maintaining the accuracy, and in some datasets even yields accuracy improvements.
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents
Feb 02, 2026Most Large Language Model (LLM) agent memory systems rely on a small set of static, hand-designed operations for extracting memory. These fixed procedures hard-code human priors about what to store and how to revise memory, making them rigid under diverse interaction patterns and inefficient on long histories. To this end, we present \textbf{MemSkill}, which reframes these operations as learnable and evolvable memory skills, structured and reusable routines for extracting, consolidating, and pruning information from interaction traces. Inspired by the design philosophy of agent skills, MemSkill employs a \emph{controller} that learns to select a small set of relevant skills, paired with an LLM-based \emph{executor} that produces skill-guided memories. Beyond learning skill selection, MemSkill introduces a \emph{designer} that periodically reviews hard cases where selected skills yield incorrect or incomplete memories, and evolves the skill set by proposing refinements and new skills. Together, MemSkill forms a closed-loop procedure that improves both the skill-selection policy and the skill set itself. Experiments on LoCoMo, LongMemEval, HotpotQA, and ALFWorld demonstrate that MemSkill improves task performance over strong baselines and generalizes well across settings. Further analyses shed light on how skills evolve, offering insights toward more adaptive, self-evolving memory management for LLM agents.
Programming over Thinking: Efficient and Robust Multi-Constraint Planning
Jan 14, 2026Multi-constraint planning involves identifying, evaluating, and refining candidate plans while satisfying multiple, potentially conflicting constraints. Existing large language model (LLM) approaches face fundamental limitations in this domain. Pure reasoning paradigms, which rely on long natural language chains, are prone to inconsistency, error accumulation, and prohibitive cost as constraints compound. Conversely, LLMs combined with coding- or solver-based strategies lack flexibility: they often generate problem-specific code from scratch or depend on fixed solvers, failing to capture generalizable logic across diverse problems. To address these challenges, we introduce the Scalable COde Planning Engine (SCOPE), a framework that disentangles query-specific reasoning from generic code execution. By separating reasoning from execution, SCOPE produces solver functions that are consistent, deterministic, and reusable across queries while requiring only minimal changes to input parameters. SCOPE achieves state-of-the-art performance while lowering cost and latency. For example, with GPT-4o, it reaches 93.1% success on TravelPlanner, a 61.6% gain over the best baseline (CoT) while cutting inference cost by 1.4x and time by ~4.67x. Code is available at https://github.com/DerrickGXD/SCOPE.
Coordinating Search-Informed Reasoning and Reasoning-Guided Search in Claim Verification
Jun 09, 2025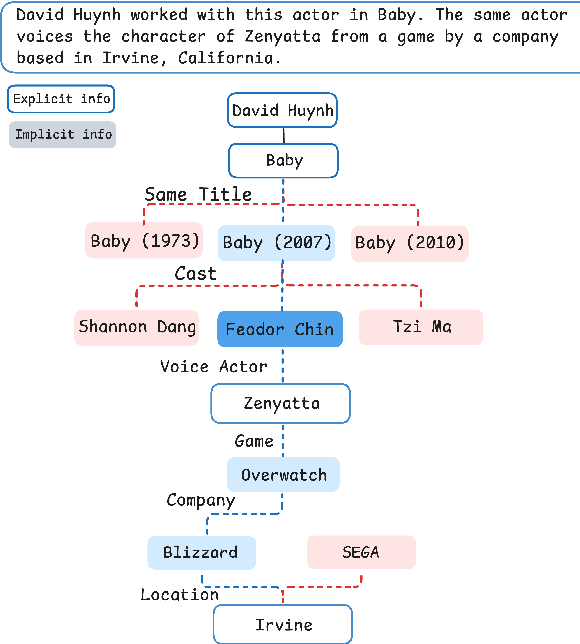
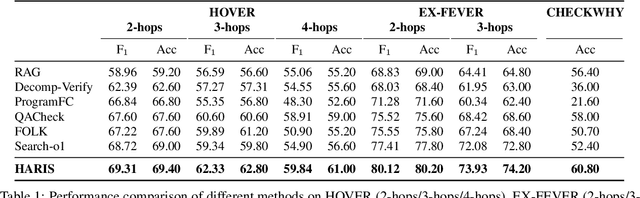
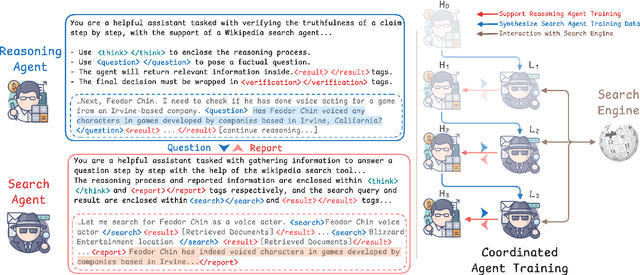
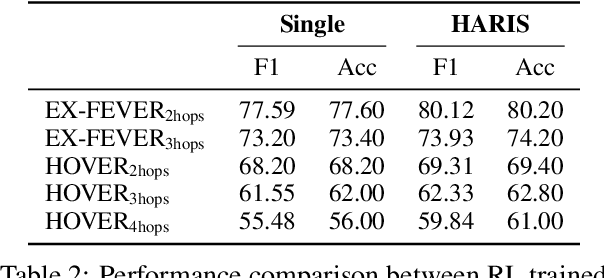
Multi-hop claim verification is inherently challenging, requiring multi-step reasoning to construct verification chains while iteratively searching for information to uncover hidden bridging facts. This process is fundamentally interleaved, as effective reasoning relies on dynamically retrieved evidence, while effective search demands reasoning to refine queries based on partial information. To achieve this, we propose Hierarchical Agent Reasoning and Information Search (HARIS), explicitly modeling the coordinated process of reasoning-driven searching and search-informed reasoning. HARIS consists of a high-level reasoning agent that focuses on constructing the main verification chain, generating factual questions when more information is needed, and a low-level search agent that iteratively retrieves more information, refining its search based on intermediate findings. This design allows each agent to specialize in its respective task, enhancing verification accuracy and interpretability. HARIS is trained using reinforcement learning with outcome-based rewards. Experimental results on the EX-FEVER and HOVER benchmarks demonstrate that HARIS achieves strong performance, greatly advancing multi-hop claim verification.
Static or Dynamic: Towards Query-Adaptive Token Selection for Video Question Answering
Apr 30, 2025
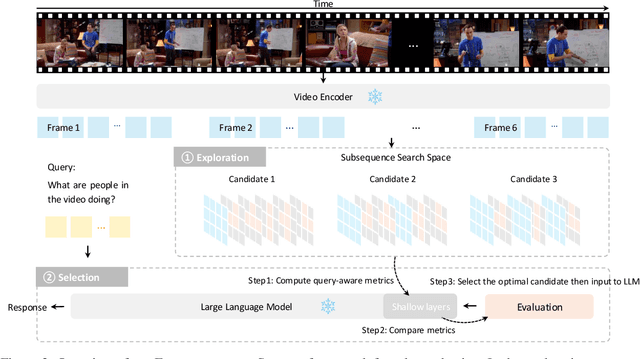
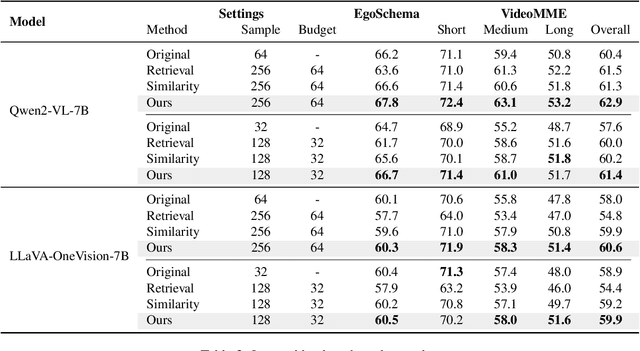
Video question answering benefits from the rich information available in videos, enabling a wide range of applications. However, the large volume of tokens generated from longer videos presents significant challenges to memory efficiency and model performance. To alleviate this issue, existing works propose to compress video inputs, but usually overlooking the varying importance of static and dynamic information across different queries, leading to inefficient token usage within limited budgets. To tackle this, we propose a novel token selection strategy, EXPLORE-THEN-SELECT, that adaptively adjust static and dynamic information needed based on question requirements. Our framework first explores different token allocations between static frames, which preserve spatial details, and dynamic frames, which capture temporal changes. Next, it employs a query-aware attention-based metric to select the optimal token combination without model updates. Our proposed framework is plug-and-play that can be seamlessly integrated within diverse video-language models. Extensive experiments show that our method achieves significant performance improvements (up to 5.8%) among various video question answering benchmarks.
Reinforcing Compositional Retrieval: Retrieving Step-by-Step for Composing Informative Contexts
Apr 15, 2025
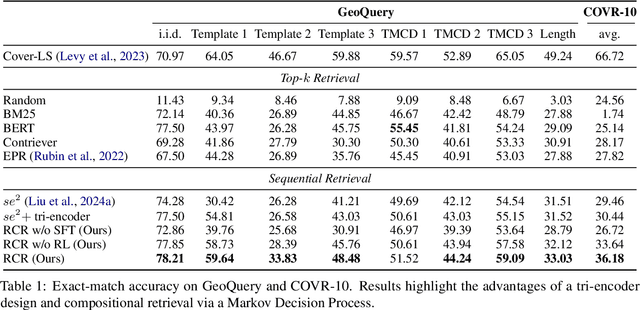
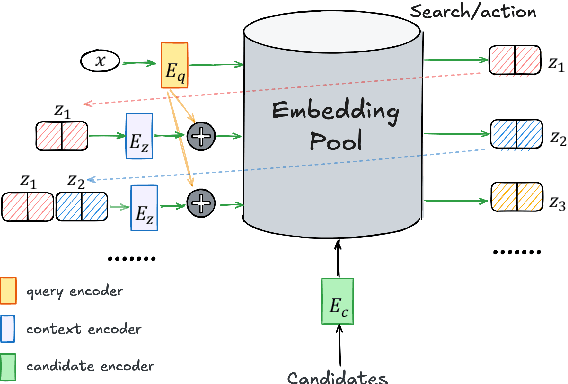
Large Language Models (LLMs) have demonstrated remarkable capabilities across numerous tasks, yet they often rely on external context to handle complex tasks. While retrieval-augmented frameworks traditionally focus on selecting top-ranked documents in a single pass, many real-world scenarios demand compositional retrieval, where multiple sources must be combined in a coordinated manner. In this work, we propose a tri-encoder sequential retriever that models this process as a Markov Decision Process (MDP), decomposing the probability of retrieving a set of elements into a sequence of conditional probabilities and allowing each retrieval step to be conditioned on previously selected examples. We train the retriever in two stages: first, we efficiently construct supervised sequential data for initial policy training; we then refine the policy to align with the LLM's preferences using a reward grounded in the structural correspondence of generated programs. Experimental results show that our method consistently and significantly outperforms baselines, underscoring the importance of explicitly modeling inter-example dependencies. These findings highlight the potential of compositional retrieval for tasks requiring multiple pieces of evidence or examples.
BOOST: Bootstrapping Strategy-Driven Reasoning Programs for Program-Guided Fact-Checking
Apr 03, 2025



Program-guided reasoning has shown promise in complex claim fact-checking by decomposing claims into function calls and executing reasoning programs. However, prior work primarily relies on few-shot in-context learning (ICL) with ad-hoc demonstrations, which limit program diversity and require manual design with substantial domain knowledge. Fundamentally, the underlying principles of effective reasoning program generation still remain underexplored, making it challenging to construct effective demonstrations. To address this, we propose BOOST, a bootstrapping-based framework for few-shot reasoning program generation. BOOST explicitly integrates claim decomposition and information-gathering strategies as structural guidance for program generation, iteratively refining bootstrapped demonstrations in a strategy-driven and data-centric manner without human intervention. This enables a seamless transition from zero-shot to few-shot strategic program-guided learning, enhancing interpretability and effectiveness. Experimental results show that BOOST outperforms prior few-shot baselines in both zero-shot and few-shot settings for complex claim verification.
Visual-RAG: Benchmarking Text-to-Image Retrieval Augmented Generation for Visual Knowledge Intensive Queries
Feb 23, 2025



Retrieval-Augmented Generation (RAG) is a popular approach for enhancing Large Language Models (LLMs) by addressing their limitations in verifying facts and answering knowledge-intensive questions. As the research in LLM extends their capability to handle input modality other than text, e.g. image, several multimodal RAG benchmarks are proposed. Nonetheless, they mainly use textual knowledge bases as the primary source of evidences for augmentation. There still lack benchmarks designed to evaluate images as augmentation in RAG systems and how they leverage visual knowledge. We propose Visual-RAG, a novel Question Answering benchmark that emphasizes visual knowledge intensive questions. Unlike prior works relying on text-based evidence, Visual-RAG necessitates text-to-image retrieval and integration of relevant clue images to extract visual knowledge as evidence. With Visual-RAG, we evaluate 5 open-sourced and 3 proprietary Multimodal LLMs (MLLMs), revealing that images can serve as good evidence in RAG; however, even the SoTA models struggle with effectively extracting and utilizing visual knowledge