 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight Forcing: Accelerating Autoregressive Video Diffusion via Sparse Attention
Feb 04, 2026Advanced autoregressive (AR) video generation models have improved visual fidelity and interactivity, but the quadratic complexity of attention remains a primary bottleneck for efficient deployment. While existing sparse attention solutions have shown promise on bidirectional models, we identify that applying these solutions to AR models leads to considerable performance degradation for two reasons: isolated consideration of chunk generation and insufficient utilization of past informative context. Motivated by these observations, we propose \textsc{Light Forcing}, the \textit{first} sparse attention solution tailored for AR video generation models. It incorporates a \textit{Chunk-Aware Growth} mechanism to quantitatively estimate the contribution of each chunk, which determines their sparsity allocation. This progressive sparsity increase strategy enables the current chunk to inherit prior knowledge in earlier chunks during generation. Additionally, we introduce a \textit{Hierarchical Sparse Attention} to capture informative historical and local context in a coarse-to-fine manner. Such two-level mask selection strategy (\ie, frame and block level) can adaptively handle diverse attention patterns. Extensive experiments demonstrate that our method outperforms existing sparse attention in quality (\eg, 84.5 on VBench) and efficiency (\eg, $1.2{\sim}1.3\times$ end-to-end speedup). Combined with FP8 quantization and LightVAE, \textsc{Light Forcing} further achieves a $2.3\times$ speedup and 19.7\,FPS on an RTX~5090 GPU. Code will be released at \href{https://github.com/chengtao-lv/LightForcing}{https://github.com/chengtao-lv/LightForcing}.
LLMC+: Benchmarking Vision-Language Model Compression with a Plug-and-play Toolkit
Aug 13, 2025Large Vision-Language Models (VLMs) exhibit impressive multi-modal capabilities but suffer from prohibitive computational and memory demands, due to their long visual token sequences and massive parameter sizes. To address these issues, recent works have proposed training-free compression methods. However, existing efforts often suffer from three major limitations: (1) Current approaches do not decompose techniques into comparable modules, hindering fair evaluation across spatial and temporal redundancy. (2) Evaluation confined to simple single-turn tasks, failing to reflect performance in realistic scenarios. (3) Isolated use of individual compression techniques, without exploring their joint potential. To overcome these gaps, we introduce LLMC+, a comprehensive VLM compression benchmark with a versatile, plug-and-play toolkit. LLMC+ supports over 20 algorithms across five representative VLM families and enables systematic study of token-level and model-level compression. Our benchmark reveals that: (1) Spatial and temporal redundancies demand distinct technical strategies. (2) Token reduction methods degrade significantly in multi-turn dialogue and detail-sensitive tasks. (3) Combining token and model compression achieves extreme compression with minimal performance loss. We believe LLMC+ will facilitate fair evaluation and inspire future research in efficient VLM. Our code is available at https://github.com/ModelTC/LightCompress.
Static or Dynamic: Towards Query-Adaptive Token Selection for Video Question Answering
Apr 30, 2025
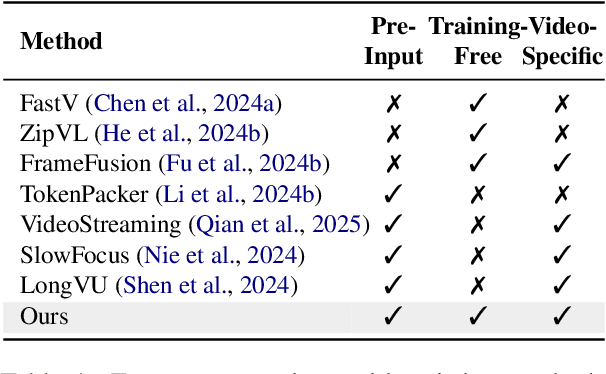
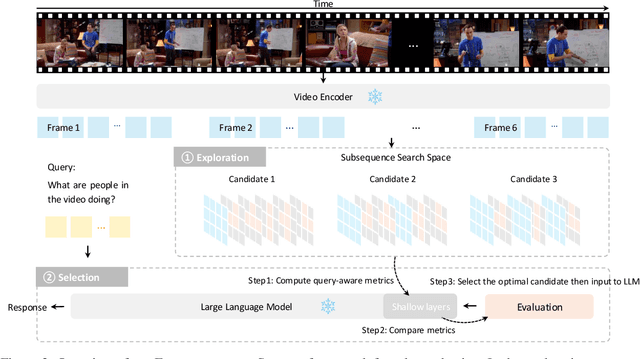
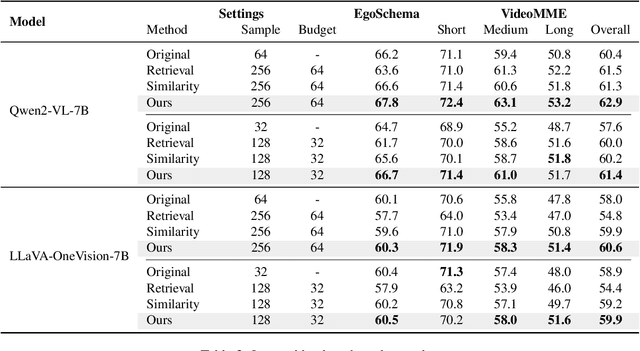
Video question answering benefits from the rich information available in videos, enabling a wide range of applications. However, the large volume of tokens generated from longer videos presents significant challenges to memory efficiency and model performance. To alleviate this issue, existing works propose to compress video inputs, but usually overlooking the varying importance of static and dynamic information across different queries, leading to inefficient token usage within limited budgets. To tackle this, we propose a novel token selection strategy, EXPLORE-THEN-SELECT, that adaptively adjust static and dynamic information needed based on question requirements. Our framework first explores different token allocations between static frames, which preserve spatial details, and dynamic frames, which capture temporal changes. Next, it employs a query-aware attention-based metric to select the optimal token combination without model updates. Our proposed framework is plug-and-play that can be seamlessly integrated within diverse video-language models. Extensive experiments show that our method achieves significant performance improvements (up to 5.8%) among various video question answering benchmarks.
HGNAS: Hardware-Aware Graph Neural Architecture Search for Edge Devices
Aug 23, 2024



Graph Neural Networks (GNNs) are becoming increasingly popular for graph-based learning tasks such as point cloud processing due to their state-of-the-art (SOTA) performance. Nevertheless, the research community has primarily focused on improving model expressiveness, lacking consideration of how to design efficient GNN models for edge scenarios with real-time requirements and limited resources. Examining existing GNN models reveals varied execution across platforms and frequent Out-Of-Memory (OOM) problems, highlighting the need for hardware-aware GNN design. To address this challenge, this work proposes a novel hardware-aware graph neural architecture search framework tailored for resource constraint edge devices, namely HGNAS. To achieve hardware awareness, HGNAS integrates an efficient GNN hardware performance predictor that evaluates the latency and peak memory usage of GNNs in milliseconds. Meanwhile, we study GNN memory usage during inference and offer a peak memory estimation method, enhancing the robustness of architecture evaluations when combined with predictor outcomes. Furthermore, HGNAS constructs a fine-grained design space to enable the exploration of extreme performance architectures by decoupling the GNN paradigm. In addition, the multi-stage hierarchical search strategy is leveraged to facilitate the navigation of huge candidates, which can reduce the single search time to a few GPU hours. To the best of our knowledge, HGNAS is the first automated GNN design framework for edge devices, and also the first work to achieve hardware awareness of GNNs across different platforms. Extensive experiments across various applications and edge devices have proven the superiority of HGNAS. It can achieve up to a 10.6x speedup and an 82.5% peak memory reduction with negligible accuracy loss compared to DGCNN on ModelNet40.
Lossy and Lossless Post-training Model Size Compression
Aug 08, 2023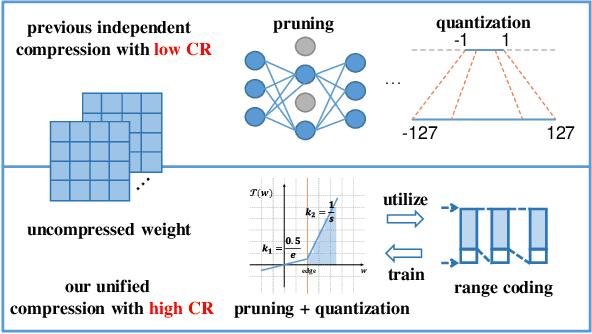
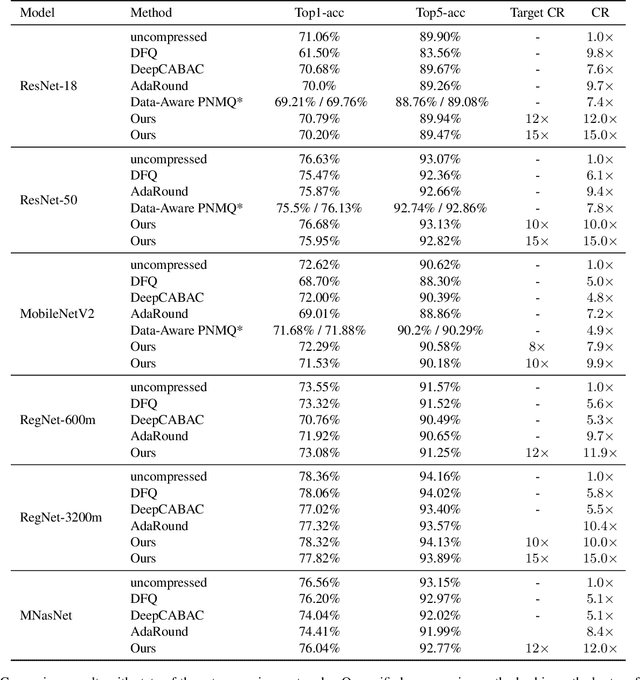
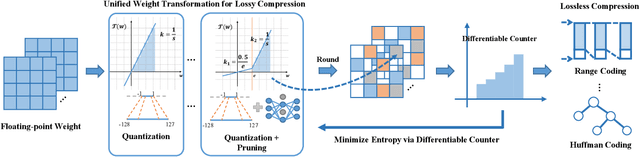
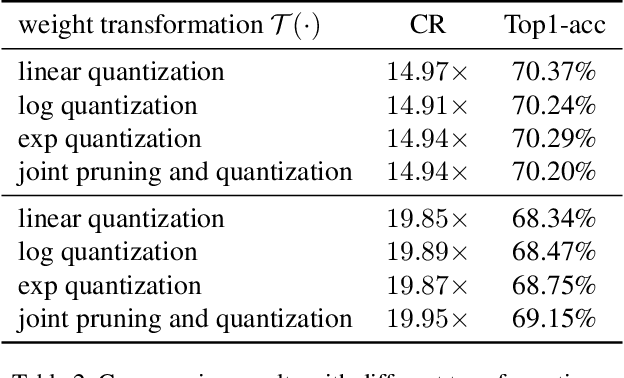
Deep neural networks have delivered remarkable performance and have been widely used in various visual tasks. However, their huge size causes significant inconvenience for transmission and storage. Many previous studies have explored model size compression. However, these studies often approach various lossy and lossless compression methods in isolation, leading to challenges in achieving high compression ratios efficiently. This work proposes a post-training model size compression method that combines lossy and lossless compression in a unified way. We first propose a unified parametric weight transformation, which ensures different lossy compression methods can be performed jointly in a post-training manner. Then, a dedicated differentiable counter is introduced to guide the optimization of lossy compression to arrive at a more suitable point for later lossless compression. Additionally, our method can easily control a desired global compression ratio and allocate adaptive ratios for different layers. Finally, our method can achieve a stable $10\times$ compression ratio without sacrificing accuracy and a $20\times$ compression ratio with minor accuracy loss in a short time. Our code is available at https://github.com/ModelTC/L2_Compression .
Hardware-Aware Graph Neural Network Automated Design for Edge Computing Platforms
Mar 20, 2023


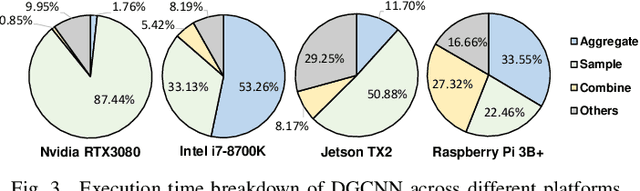
Graph neural networks (GNNs) have emerged as a popular strategy for handling non-Euclidean data due to their state-of-the-art performance. However, most of the current GNN model designs mainly focus on task accuracy, lacking in considering hardware resources limitation and real-time requirements of edge application scenarios. Comprehensive profiling of typical GNN models indicates that their execution characteristics are significantly affected across different computing platforms, which demands hardware awareness for efficient GNN designs. In this work, HGNAS is proposed as the first Hardware-aware Graph Neural Architecture Search framework targeting resource constraint edge devices. By decoupling the GNN paradigm, HGNAS constructs a fine-grained design space and leverages an efficient multi-stage search strategy to explore optimal architectures within a few GPU hours. Moreover, HGNAS achieves hardware awareness during the GNN architecture design by leveraging a hardware performance predictor, which could balance the GNN model accuracy and efficiency corresponding to the characteristics of targeted devices. Experimental results show that HGNAS can achieve about $10.6\times$ speedup and $88.2\%$ peak memory reduction with a negligible accuracy loss compared to DGCNN on various edge devices, including Nvidia RTX3080, Jetson TX2, Intel i7-8700K and Raspberry Pi 3B+.