 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Low-Rank Training in Transformer Language Models: Efficiency and Scaling Analysis
Jul 13, 2024



State-of-the-art LLMs often rely on scale with high computational costs, which has sparked a research agenda to reduce parameter counts and costs without significantly impacting performance. Our study focuses on Transformer-based LLMs, specifically applying low-rank parametrization to the computationally intensive feedforward networks (FFNs), which are less studied than attention blocks. In contrast to previous works, (i) we explore low-rank parametrization at scale, up to 1.3B parameters; (ii) within Transformer language models rather than convolutional architectures; and (iii) starting from training from scratch. Experiments on the large RefinedWeb dataset show that low-rank parametrization is both efficient (e.g., 2.6$\times$ FFN speed-up with 32\% parameters) and effective during training. Interestingly, these structured FFNs exhibit steeper scaling curves than the original models. Motivated by this finding, we develop the wide and structured networks surpassing the current medium-sized and large-sized Transformer in perplexity and throughput performance.
Building on Efficient Foundations: Effectively Training LLMs with Structured Feedforward Layers
Jun 24, 2024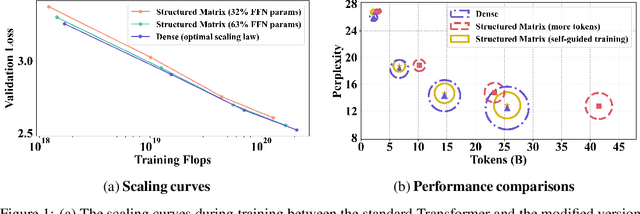
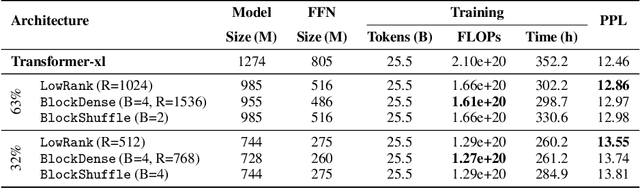
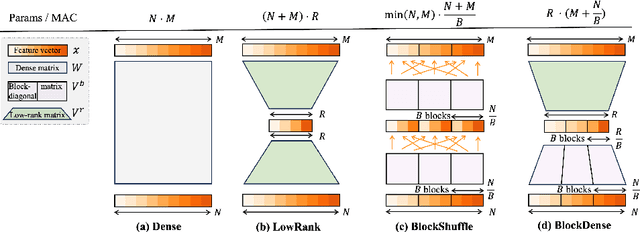
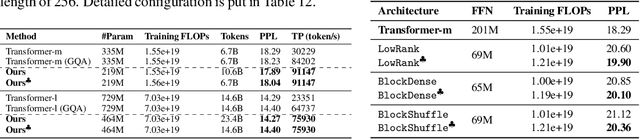
State-of-the-art results in large language models (LLMs) often rely on scale, which becomes computationally expensive. This has sparked a research agenda to reduce these models' parameter count and computational costs without significantly impacting their performance. Our study focuses on transformer-based LLMs, specifically targeting the computationally intensive feedforward networks (FFN), which are less studied than attention blocks. We consider three candidate linear layer approximations in the FFN by combining efficient low-rank and block-diagonal matrices. In contrast to many previous works that examined these approximations, our study i) explores these structures from the training-from-scratch perspective, ii) scales up to 1.3B parameters, and iii) is conducted within recent Transformer-based LLMs rather than convolutional architectures. We first demonstrate they can lead to actual computational gains in various scenarios, including online decoding when using a pre-merge technique. Additionally, we propose a novel training regime, called \textit{self-guided training}, aimed at improving the poor training dynamics that these approximations exhibit when used from initialization. Experiments on the large RefinedWeb dataset show that our methods are both efficient and effective for training and inference. Interestingly, these structured FFNs exhibit steeper scaling curves than the original models. Further applying self-guided training to the structured matrices with 32\% FFN parameters and 2.5$\times$ speed-up enables only a 0.4 perplexity increase under the same training FLOPs. Finally, we develop the wide and structured networks surpassing the current medium-sized and large-sized Transformer in perplexity and throughput performance. Our code is available at \url{https://github.com/CLAIRE-Labo/StructuredFFN/tree/main}.
Selective Focus: Investigating Semantics Sensitivity in Post-training Quantization for Lane Detection
May 10, 2024Lane detection (LD) plays a crucial role in enhancing the L2+ capabilities of autonomous driving, capturing widespread attention. The Post-Processing Quantization (PTQ) could facilitate the practical application of LD models, enabling fast speeds and limited memories without labeled data. However, prior PTQ methods do not consider the complex LD outputs that contain physical semantics, such as offsets, locations, etc., and thus cannot be directly applied to LD models. In this paper, we pioneeringly investigate semantic sensitivity to post-processing for lane detection with a novel Lane Distortion Score. Moreover, we identify two main factors impacting the LD performance after quantization, namely intra-head sensitivity and inter-head sensitivity, where a small quantization error in specific semantics can cause significant lane distortion. Thus, we propose a Selective Focus framework deployed with Semantic Guided Focus and Sensitivity Aware Selection modules, to incorporate post-processing information into PTQ reconstruction. Based on the observed intra-head sensitivity, Semantic Guided Focus is introduced to prioritize foreground-related semantics using a practical proxy. For inter-head sensitivity, we present Sensitivity Aware Selection, efficiently recognizing influential prediction heads and refining the optimization objectives at runtime. Extensive experiments have been done on a wide variety of models including keypoint-, anchor-, curve-, and segmentation-based ones. Our method produces quantized models in minutes on a single GPU and can achieve 6.4% F1 Score improvement on the CULane dataset.
* Accepted by AAAI-24
Fast and Controllable Post-training Sparsity: Learning Optimal Sparsity Allocation with Global Constraint in Minutes
May 09, 2024Neural network sparsity has attracted many research interests due to its similarity to biological schemes and high energy efficiency. However, existing methods depend on long-time training or fine-tuning, which prevents large-scale applications. Recently, some works focusing on post-training sparsity (PTS) have emerged. They get rid of the high training cost but usually suffer from distinct accuracy degradation due to neglect of the reasonable sparsity rate at each layer. Previous methods for finding sparsity rates mainly focus on the training-aware scenario, which usually fails to converge stably under the PTS setting with limited data and much less training cost. In this paper, we propose a fast and controllable post-training sparsity (FCPTS) framework. By incorporating a differentiable bridge function and a controllable optimization objective, our method allows for rapid and accurate sparsity allocation learning in minutes, with the added assurance of convergence to a predetermined global sparsity rate. Equipped with these techniques, we can surpass the state-of-the-art methods by a large margin, e.g., over 30\% improvement for ResNet-50 on ImageNet under the sparsity rate of 80\%. Our plug-and-play code and supplementary materials are open-sourced at https://github.com/ModelTC/FCPTS.
QLLM: Accurate and Efficient Low-Bitwidth Quantization for Large Language Models
Oct 12, 2023Large Language Models (LLMs) excel in NLP, but their demands hinder their widespread deployment. While Quantization-Aware Training (QAT) offers a solution, its extensive training costs make Post-Training Quantization (PTQ) a more practical approach for LLMs. In existing studies, activation outliers in particular channels are identified as the bottleneck to PTQ accuracy. They propose to transform the magnitudes from activations to weights, which however offers limited alleviation or suffers from unstable gradients, resulting in a severe performance drop at low-bitwidth. In this paper, we propose QLLM, an accurate and efficient low-bitwidth PTQ method designed for LLMs. QLLM introduces an adaptive channel reassembly technique that reallocates the magnitude of outliers to other channels, thereby mitigating their impact on the quantization range. This is achieved by channel disassembly and channel assembly, which first breaks down the outlier channels into several sub-channels to ensure a more balanced distribution of activation magnitudes. Then similar channels are merged to maintain the original channel number for efficiency. Additionally, an adaptive strategy is designed to autonomously determine the optimal number of sub-channels for channel disassembly. To further compensate for the performance loss caused by quantization, we propose an efficient tuning method that only learns a small number of low-rank weights while freezing the pre-trained quantized model. After training, these low-rank parameters can be fused into the frozen weights without affecting inference. Extensive experiments on LLaMA-1 and LLaMA-2 show that QLLM can obtain accurate quantized models efficiently. For example, QLLM quantizes the 4-bit LLaMA-2-70B within 10 hours on a single A100-80G GPU, outperforming the previous state-of-the-art method by 7.89% on the average accuracy across five zero-shot tasks.
Lossy and Lossless Post-training Model Size Compression
Aug 08, 2023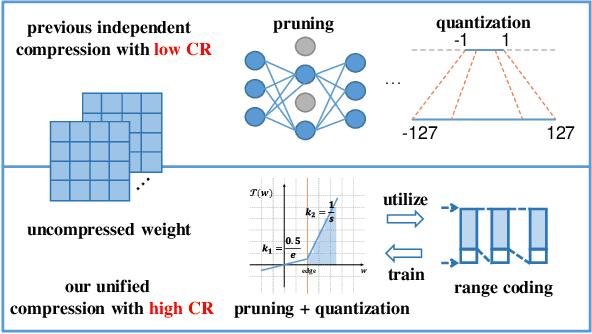
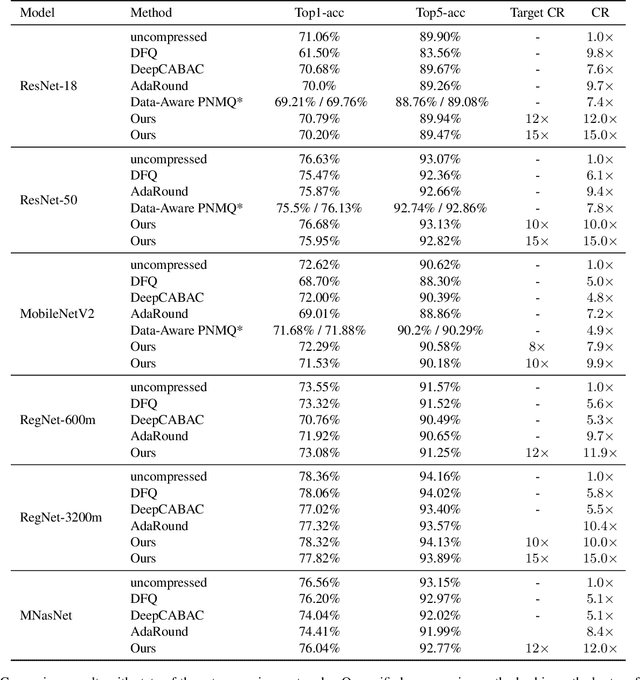
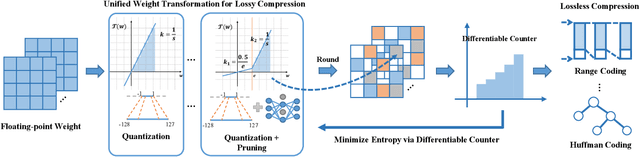
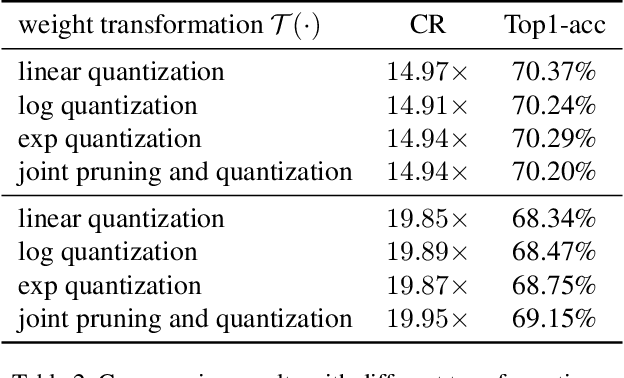
Deep neural networks have delivered remarkable performance and have been widely used in various visual tasks. However, their huge size causes significant inconvenience for transmission and storage. Many previous studies have explored model size compression. However, these studies often approach various lossy and lossless compression methods in isolation, leading to challenges in achieving high compression ratios efficiently. This work proposes a post-training model size compression method that combines lossy and lossless compression in a unified way. We first propose a unified parametric weight transformation, which ensures different lossy compression methods can be performed jointly in a post-training manner. Then, a dedicated differentiable counter is introduced to guide the optimization of lossy compression to arrive at a more suitable point for later lossless compression. Additionally, our method can easily control a desired global compression ratio and allocate adaptive ratios for different layers. Finally, our method can achieve a stable $10\times$ compression ratio without sacrificing accuracy and a $20\times$ compression ratio with minor accuracy loss in a short time. Our code is available at https://github.com/ModelTC/L2_Compression .
Outlier Suppression+: Accurate quantization of large language models by equivalent and optimal shifting and scaling
Apr 18, 2023



Quantization of transformer language models faces significant challenges due to the existence of detrimental outliers in activations. We observe that these outliers are asymmetric and concentrated in specific channels. To address this issue, we propose the Outlier Suppression+ framework. First, we introduce channel-wise shifting and scaling operations to eliminate asymmetric presentation and scale down problematic channels. We demonstrate that these operations can be seamlessly migrated into subsequent modules while maintaining equivalence. Second, we quantitatively analyze the optimal values for shifting and scaling, taking into account both the asymmetric property and quantization errors of weights in the next layer. Our lightweight framework can incur minimal performance degradation under static and standard post-training quantization settings. Comprehensive results across various tasks and models reveal that our approach achieves near-floating-point performance on both small models, such as BERT, and large language models (LLMs) including OPTs, BLOOM, and BLOOMZ at 8-bit and 6-bit settings. Furthermore, we establish a new state of the art for 4-bit BERT.
Outlier Suppression: Pushing the Limit of Low-bit Transformer Language Models
Sep 27, 2022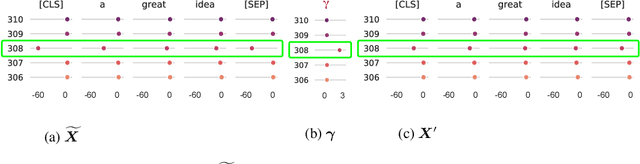

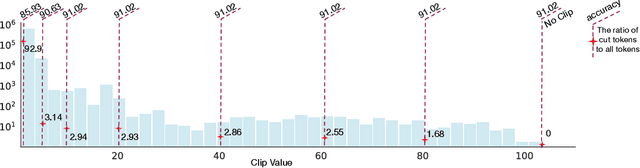

Transformer architecture has become the fundamental element of the widespread natural language processing~(NLP) models. With the trends of large NLP models, the increasing memory and computation costs hinder their efficient deployment on resource-limited devices. Therefore, transformer quantization attracts wide research interest. Recent work recognizes that structured outliers are the critical bottleneck for quantization performance. However, their proposed methods increase the computation overhead and still leave the outliers there. To fundamentally address this problem, this paper delves into the inherent inducement and importance of the outliers. We discover that $\boldsymbol \gamma$ in LayerNorm (LN) acts as a sinful amplifier for the outliers, and the importance of outliers varies greatly where some outliers provided by a few tokens cover a large area but can be clipped sharply without negative impacts. Motivated by these findings, we propose an outlier suppression framework including two components: Gamma Migration and Token-Wise Clipping. The Gamma Migration migrates the outlier amplifier to subsequent modules in an equivalent transformation, contributing to a more quantization-friendly model without any extra burden. The Token-Wise Clipping takes advantage of the large variance of token range and designs a token-wise coarse-to-fine pipeline, obtaining a clipping range with minimal final quantization loss in an efficient way. This framework effectively suppresses the outliers and can be used in a plug-and-play mode. Extensive experiments prove that our framework surpasses the existing works and, for the first time, pushes the 6-bit post-training BERT quantization to the full-precision (FP) level. Our code is available at https://github.com/wimh966/outlier_suppression.
QDrop: Randomly Dropping Quantization for Extremely Low-bit Post-Training Quantization
Mar 11, 2022
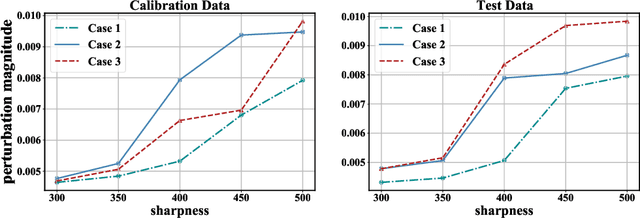

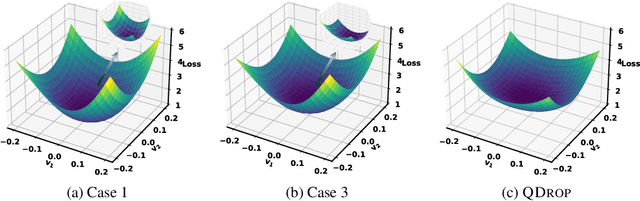
Recently, post-training quantization (PTQ) has driven much attention to produce efficient neural networks without long-time retraining. Despite its low cost, current PTQ works tend to fail under the extremely low-bit setting. In this study, we pioneeringly confirm that properly incorporating activation quantization into the PTQ reconstruction benefits the final accuracy. To deeply understand the inherent reason, a theoretical framework is established, indicating that the flatness of the optimized low-bit model on calibration and test data is crucial. Based on the conclusion, a simple yet effective approach dubbed as QDROP is proposed, which randomly drops the quantization of activations during PTQ. Extensive experiments on various tasks including computer vision (image classification, object detection) and natural language processing (text classification and question answering) prove its superiority. With QDROP, the limit of PTQ is pushed to the 2-bit activation for the first time and the accuracy boost can be up to 51.49%. Without bells and whistles, QDROP establishes a new state of the art for PTQ. Our code is available at https://github.com/wimh966/QDrop and has been integrated into MQBench (https://github.com/ModelTC/MQBench)