 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTacForeSight: Force-Guided Tactile World Model for Contact-Rich Manipulation
Jun 09, 2026Contact-rich manipulation requires robots to continuously perceive and regulate evolving physical interactions under dynamic contact transitions or complex surface geometries. Recent imitation learning methods improve contact-aware control by incorporating tactile or force feedback, but they rarely model the asymmetric spatiotemporal roles of global force and local tactile sensing. To address this, we propose TacForeSight, a lightweight force-conditioned tactile foresight framework for real-time manipulation. The core component is TacForceWM, a tactile world model that predicts short-horizon tactile latent dynamics from dual-finger tactile observations conditioned on high-frequency wrist force and torque signals. Another key component, the Predictive Tactile-Conditioned Policy, leverages the predicted latents as anticipatory contact priors, models the current-to-future tactile evolution via cross-attention, and adaptively fuses visuo-tactile features through a tactile-guided gating module. By forecasting purely within a compact latent space, TacForeSight enables proactive contact reasoning with efficient real-time inference suitable for high-frequency manipulation control. Real-robot experiments on five representative tasks and three in-process perturbation settings show that TacForeSight consistently outperforms existing baselines, particularly under dynamic contact disturbances. All models and datasets will be made publicly available on the project website at https://tacforesight.github.io/ProjectPage.
InstructTable: Improving Table Structure Recognition Through Instructions
Apr 03, 2026Table structure recognition (TSR) holds widespread practical importance by parsing tabular images into structured representations, yet encounters significant challenges when processing complex layouts involving merged or empty cells. Traditional visual-centric models rely exclusively on visual information while lacking crucial semantic support, thereby impeding accurate structural recognition in complex scenarios. Vision-language models leverage contextual semantics to enhance comprehension; however, these approaches underemphasize the modeling of visual structural information. To address these limitations, this paper introduces InstructTable, an instruction-guided multi-stage training TSR framework. Meticulously designed table instruction pre-training directs attention toward fine-grained structural patterns, enhancing comprehension of complex tables. Complementary TSR fine-tuning preserves robust visual information modeling, maintaining high-precision table parsing across diverse scenarios. Furthermore, we introduce Table Mix Expand (TME), an innovative template-free method for synthesizing large-scale authentic tabular data. Leveraging TME, we construct the Balanced Complex Dense Synthetic Tables (BCDSTab) benchmark, comprising 900 complex table images synthesized through our method to serve as a rigorous benchmark. Extensive experiments on multiple public datasets (FinTabNet, PubTabNet, MUSTARD) and BCDSTab demonstrate that InstructTable achieves state-of-the-art performance in TSR tasks. Ablation studies further confirm the positive impact of the proposed tabular-data-specific instructions and synthetic data.
Rhythm: Learning Interactive Whole-Body Control for Dual Humanoids
Mar 03, 2026Realizing interactive whole-body control for multi-humanoid systems is critical for unlocking complex collaborative capabilities in shared environments. Although recent advancements have significantly enhanced the agility of individual robots, bridging the gap to physically coupled multi-humanoid interaction remains challenging, primarily due to severe kinematic mismatches and complex contact dynamics. To address this, we introduce Rhythm, the first unified framework enabling real-world deployment of dual-humanoid systems for complex, physically plausible interactions. Our framework integrates three core components: (1) an Interaction-Aware Motion Retargeting (IAMR) module that generates feasible humanoid interaction references from human data; (2) an Interaction-Guided Reinforcement Learning (IGRL) policy that masters coupled dynamics via graph-based rewards; and (3) a real-world deployment system that enables robust transfer of dual-humanoid interaction. Extensive experiments on physical Unitree G1 robots demonstrate that our framework achieves robust interactive whole-body control, successfully transferring diverse behaviors such as hugging and dancing from simulation to reality.
PositionOCR: Augmenting Positional Awareness in Multi-Modal Models via Hybrid Specialist Integration
Feb 22, 2026In recent years, Multi-modal Large Language Models (MLLMs) have achieved strong performance in OCR-centric Visual Question Answering (VQA) tasks, illustrating their capability to process heterogeneous data and exhibit adaptability across varied contexts. However, these MLLMs rely on a Large Language Model (LLM) as the decoder, which is primarily designed for linguistic processing, and thus inherently lacks the positional reasoning required for precise visual tasks, such as text spotting and text grounding. Additionally, the extensive parameters of MLLMs necessitate substantial computational resources and large-scale data for effective training. Conversely, text spotting specialists achieve state-of-the-art coordinate predictions but lack semantic reasoning capabilities. This dichotomy motivates our key research question: Can we synergize the efficiency of specialists with the contextual power of LLMs to create a positionally-accurate MLLM? To overcome these challenges, we introduce PositionOCR, a parameter-efficient hybrid architecture that seamlessly integrates a text spotting model's positional strengths with an LLM's contextual reasoning. Comprising 131M trainable parameters, this framework demonstrates outstanding multi-modal processing capabilities, particularly excelling in tasks such as text grounding and text spotting, consistently surpassing traditional MLLMs.
AnalogSAGE: Self-evolving Analog Design Multi-Agents with Stratified Memory and Grounded Experience
Dec 27, 2025Analog circuit design remains a knowledge- and experience-intensive process that relies heavily on human intuition for topology generation and device parameter tuning. Existing LLM-based approaches typically depend on prompt-driven netlist generation or predefined topology templates, limiting their ability to satisfy complex specification requirements. We propose AnalogSAGE, an open-source self-evolving multi-agent framework that coordinates three-stage agent explorations through four stratified memory layers, enabling iterative refinement with simulation-grounded feedback. To support reproducibility and generality, we release the source code. Our benchmark spans ten specification-driven operational amplifier design problems of varying difficulty, enabling quantitative and cross-task comparison under identical conditions. Evaluated under the open-source SKY130 PDK with ngspice, AnalogSAGE achieves a 10$\times$ overall pass rate, a 48$\times$ Pass@1, and a 4$\times$ reduction in parameter search space compared with existing frameworks, demonstrating that stratified memory and grounded reasoning substantially enhance the reliability and autonomy of analog design automation in practice.
DrivePI: Spatial-aware 4D MLLM for Unified Autonomous Driving Understanding, Perception, Prediction and Planning
Dec 14, 2025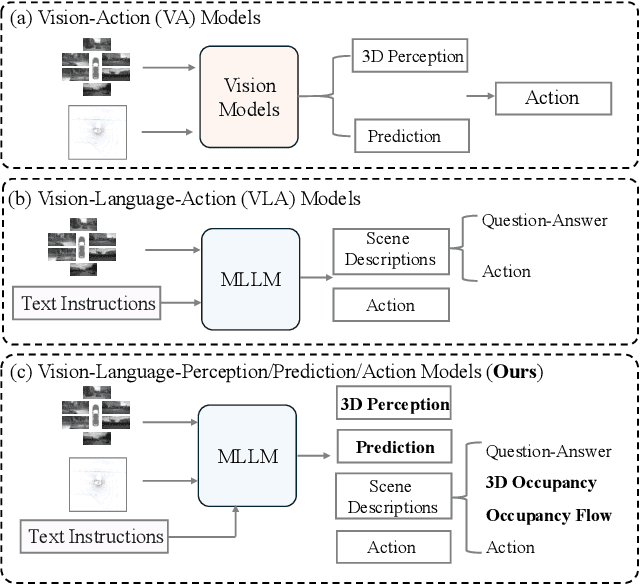
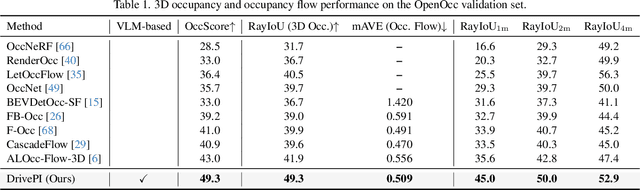
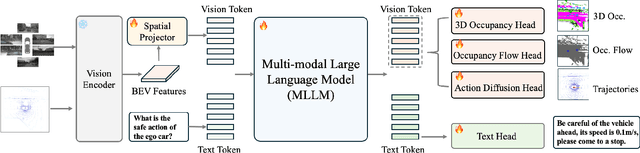
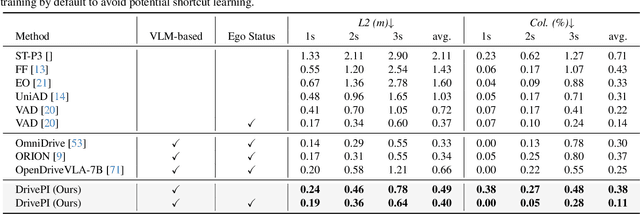
Although multi-modal large language models (MLLMs) have shown strong capabilities across diverse domains, their application in generating fine-grained 3D perception and prediction outputs in autonomous driving remains underexplored. In this paper, we propose DrivePI, a novel spatial-aware 4D MLLM that serves as a unified Vision-Language-Action (VLA) framework that is also compatible with vision-action (VA) models. Our method jointly performs spatial understanding, 3D perception (i.e., 3D occupancy), prediction (i.e., occupancy flow), and planning (i.e., action outputs) in parallel through end-to-end optimization. To obtain both precise geometric information and rich visual appearance, our approach integrates point clouds, multi-view images, and language instructions within a unified MLLM architecture. We further develop a data engine to generate text-occupancy and text-flow QA pairs for 4D spatial understanding. Remarkably, with only a 0.5B Qwen2.5 model as MLLM backbone, DrivePI as a single unified model matches or exceeds both existing VLA models and specialized VA models. Specifically, compared to VLA models, DrivePI outperforms OpenDriveVLA-7B by 2.5% mean accuracy on nuScenes-QA and reduces collision rate by 70% over ORION (from 0.37% to 0.11%) on nuScenes. Against specialized VA models, DrivePI surpasses FB-OCC by 10.3 RayIoU for 3D occupancy on OpenOcc, reduces the mAVE from 0.591 to 0.509 for occupancy flow on OpenOcc, and achieves 32% lower L2 error than VAD (from 0.72m to 0.49m) for planning on nuScenes. Code will be available at https://github.com/happinesslz/DrivePI
MoDES: Accelerating Mixture-of-Experts Multimodal Large Language Models via Dynamic Expert Skipping
Nov 19, 2025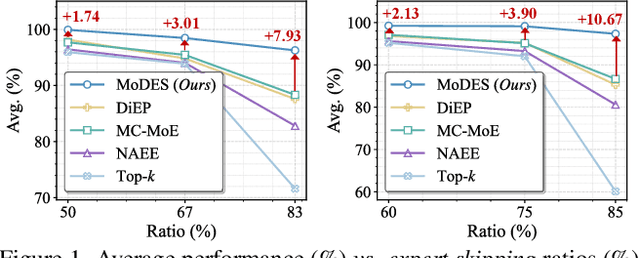

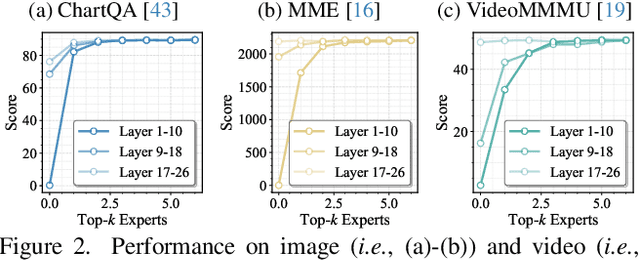
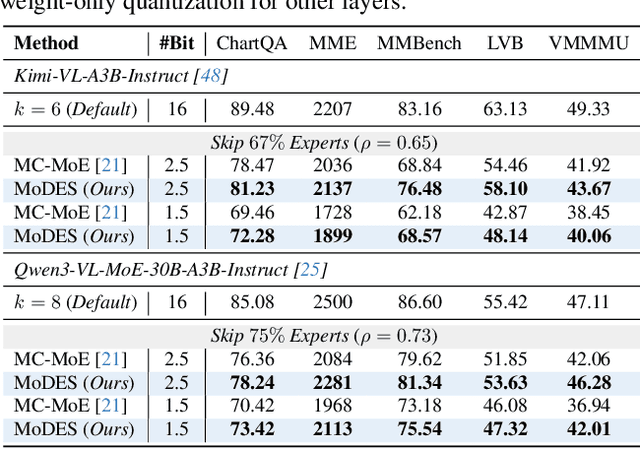
Mixture-of-Experts (MoE) Multimodal large language models (MLLMs) excel at vision-language tasks, but they suffer from high computational inefficiency. To reduce inference overhead, expert skipping methods have been proposed to deactivate redundant experts based on the current input tokens. However, we find that applying these methods-originally designed for unimodal large language models (LLMs)-to MLLMs results in considerable performance degradation. This is primarily because such methods fail to account for the heterogeneous contributions of experts across MoE layers and modality-specific behaviors of tokens within these layers. Motivated by these findings, we propose MoDES, the first training-free framework that adaptively skips experts to enable efficient and accurate MoE MLLM inference. It incorporates a globally-modulated local gating (GMLG) mechanism that integrates global layer-wise importance into local routing probabilities to accurately estimate per-token expert importance. A dual-modality thresholding (DMT) method is then applied, which processes tokens from each modality separately, to derive the skipping schedule. To set the optimal thresholds, we introduce a frontier search algorithm that exploits monotonicity properties, cutting convergence time from several days to a few hours. Extensive experiments for 3 model series across 13 benchmarks demonstrate that MoDES far outperforms previous approaches. For instance, when skipping 88% experts for Qwen3-VL-MoE-30B-A3B-Instruct, the performance boost is up to 10.67% (97.33% vs. 86.66%). Furthermore, MoDES significantly enhances inference speed, improving the prefilling time by 2.16$\times$ and the decoding time by 1.26$\times$.
SentiMM: A Multimodal Multi-Agent Framework for Sentiment Analysis in Social Media
Aug 25, 2025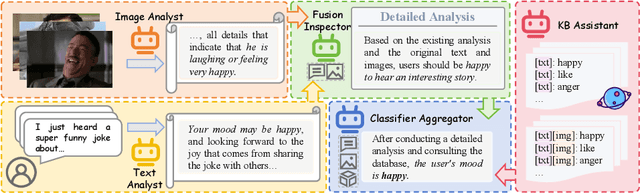
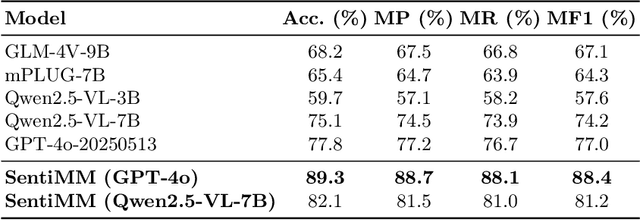
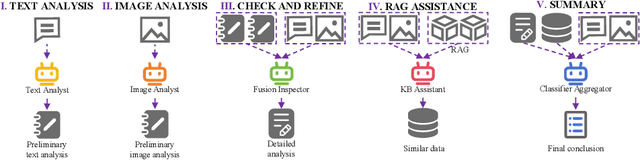

With the increasing prevalence of multimodal content on social media, sentiment analysis faces significant challenges in effectively processing heterogeneous data and recognizing multi-label emotions. Existing methods often lack effective cross-modal fusion and external knowledge integration. We propose SentiMM, a novel multi-agent framework designed to systematically address these challenges. SentiMM processes text and visual inputs through specialized agents, fuses multimodal features, enriches context via knowledge retrieval, and aggregates results for final sentiment classification. We also introduce SentiMMD, a large-scale multimodal dataset with seven fine-grained sentiment categories. Extensive experiments demonstrate that SentiMM achieves superior performance compared to state-of-the-art baselines, validating the effectiveness of our structured approach.
WikiGap: Promoting Epistemic Equity by Surfacing Knowledge Gaps Between English Wikipedia and other Language Editions
May 30, 2025With more than 11 times as many pageviews as the next, English Wikipedia dominates global knowledge access relative to other language editions. Readers are prone to assuming English Wikipedia as a superset of all language editions, leading many to prefer it even when their primary language is not English. Other language editions, however, comprise complementary facts rooted in their respective cultures and media environments, which are marginalized in English Wikipedia. While Wikipedia's user interface enables switching between language editions through its Interlanguage Link (ILL) system, it does not reveal to readers that other language editions contain valuable, complementary information. We present WikiGap, a system that surfaces complementary facts sourced from other Wikipedias within the English Wikipedia interface. Specifically, by combining a recent multilingual information-gap discovery method with a user-centered design, WikiGap enables access to complementary information from French, Russian, and Chinese Wikipedia. In a mixed-methods study (n=21), WikiGap significantly improved fact-finding accuracy, reduced task time, and received a 32-point higher usability score relative to Wikipedia's current ILL-based navigation system. Participants reported increased awareness of the availability of complementary information in non-English editions and reconsidered the completeness of English Wikipedia. WikiGap thus paves the way for improved epistemic equity across language editions.
Fine-Grained Evaluation of Large Vision-Language Models in Autonomous Driving
Mar 27, 2025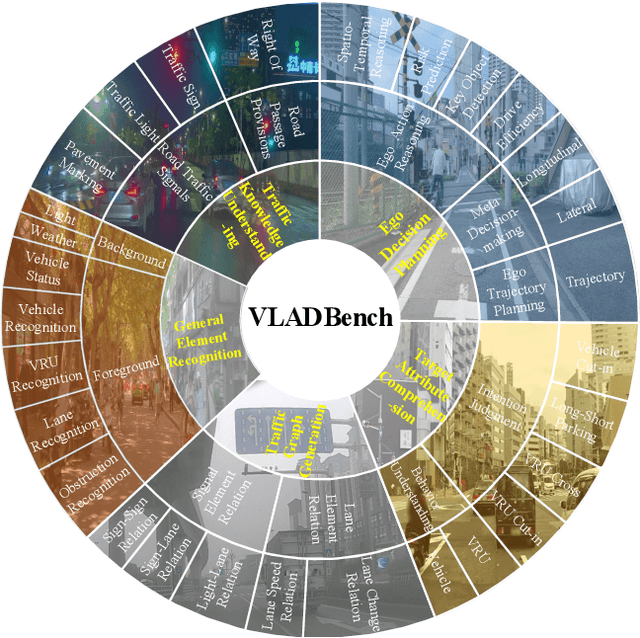

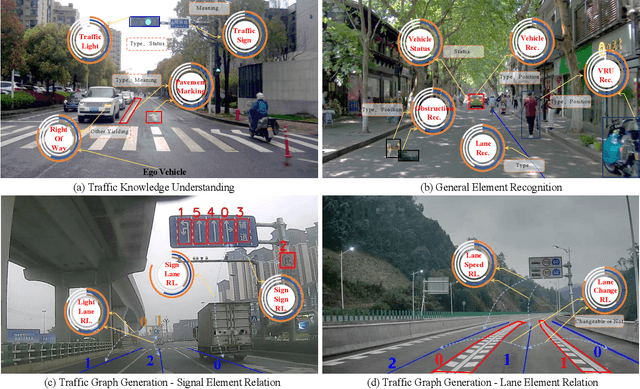

Existing benchmarks for Vision-Language Model (VLM) on autonomous driving (AD) primarily assess interpretability through open-form visual question answering (QA) within coarse-grained tasks, which remain insufficient to assess capabilities in complex driving scenarios. To this end, we introduce $\textbf{VLADBench}$, a challenging and fine-grained dataset featuring close-form QAs that progress from static foundational knowledge and elements to advanced reasoning for dynamic on-road situations. The elaborate $\textbf{VLADBench}$ spans 5 key domains: Traffic Knowledge Understanding, General Element Recognition, Traffic Graph Generation, Target Attribute Comprehension, and Ego Decision-Making and Planning. These domains are further broken down into 11 secondary aspects and 29 tertiary tasks for a granular evaluation. A thorough assessment of general and domain-specific (DS) VLMs on this benchmark reveals both their strengths and critical limitations in AD contexts. To further exploit the cognitive and reasoning interactions among the 5 domains for AD understanding, we start from a small-scale VLM and train the DS models on individual domain datasets (collected from 1.4M DS QAs across public sources). The experimental results demonstrate that the proposed benchmark provides a crucial step toward a more comprehensive assessment of VLMs in AD, paving the way for the development of more cognitively sophisticated and reasoning-capable AD systems.