 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Token-level Text Image Foundation Model for Document Understanding
Mar 04, 2025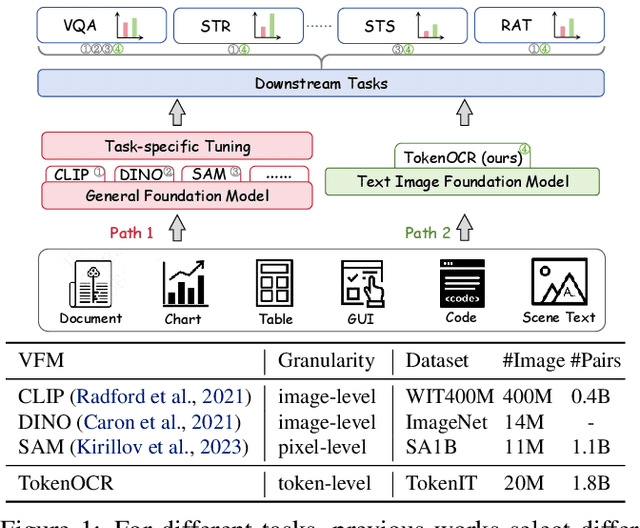
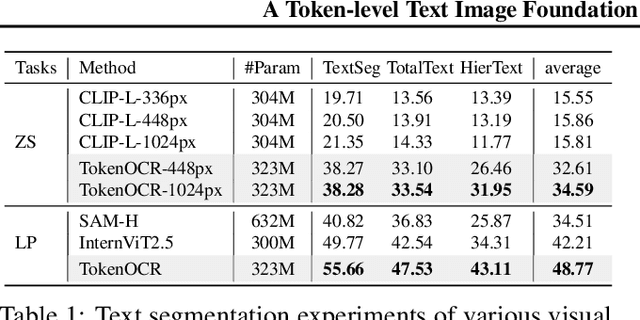
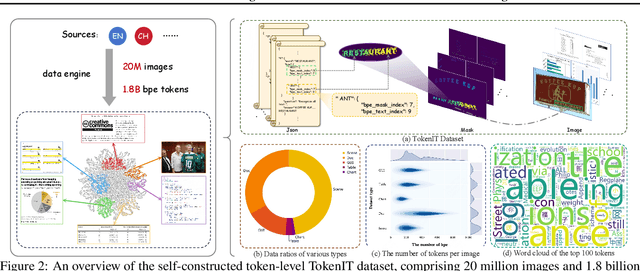
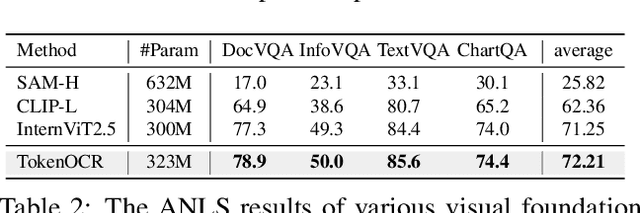
In recent years, general visual foundation models (VFMs) have witnessed increasing adoption, particularly as image encoders for popular multi-modal large language models (MLLMs). However, without semantically fine-grained supervision, these models still encounter fundamental prediction errors in the context of downstream text-image-related tasks, i.e., perception, understanding and reasoning with images containing small and dense texts. To bridge this gap, we develop TokenOCR, the first token-level visual foundation model specifically tailored for text-image-related tasks, designed to support a variety of traditional downstream applications. To facilitate the pretraining of TokenOCR, we also devise a high-quality data production pipeline that constructs the first token-level image text dataset, TokenIT, comprising 20 million images and 1.8 billion token-mask pairs. Furthermore, leveraging this foundation with exceptional image-as-text capability, we seamlessly replace previous VFMs with TokenOCR to construct a document-level MLLM, TokenVL, for VQA-based document understanding tasks. Finally, extensive experiments demonstrate the effectiveness of TokenOCR and TokenVL. Code, datasets, and weights will be available at https://token-family.github.io/TokenOCR_project.
CharGen: High Accurate Character-Level Visual Text Generation Model with MultiModal Encoder
Dec 23, 2024Recently, significant advancements have been made in diffusion-based visual text generation models. Although the effectiveness of these methods in visual text rendering is rapidly improving, they still encounter challenges such as inaccurate characters and strokes when rendering complex visual text. In this paper, we propose CharGen, a highly accurate character-level visual text generation and editing model. Specifically, CharGen employs a character-level multimodal encoder that not only extracts character-level text embeddings but also encodes glyph images character by character. This enables it to capture fine-grained cross-modality features more effectively. Additionally, we introduce a new perceptual loss in CharGen to enhance character shape supervision and address the issue of inaccurate strokes in generated text. It is worth mentioning that CharGen can be integrated into existing diffusion models to generate visual text with high accuracy. CharGen significantly improves text rendering accuracy, outperforming recent methods in public benchmarks such as AnyText-benchmark and MARIO-Eval, with improvements of more than 8% and 6%, respectively. Notably, CharGen achieved a 5.5% increase in accuracy on Chinese test sets.
High-Resolution Image Synthesis via Next-Token Prediction
Nov 22, 2024
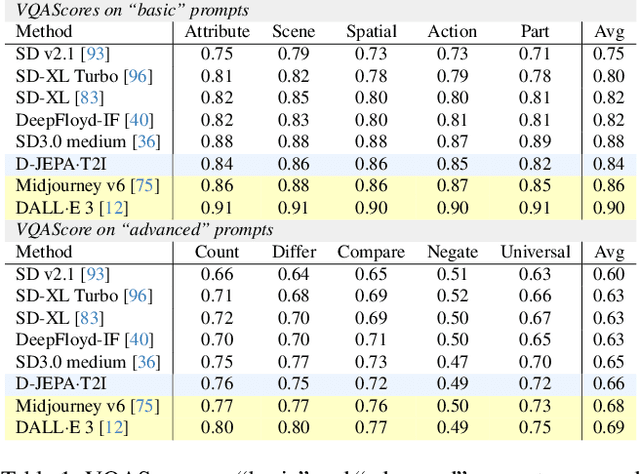

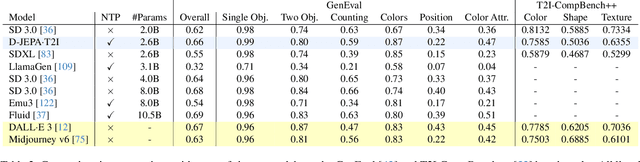
Denoising with a Joint-Embedding Predictive Architecture (D-JEPA), an autoregressive model, has demonstrated outstanding performance in class-conditional image generation. However, the application of next-token prediction in high-resolution text-to-image generation remains underexplored. In this paper, we introduce D-JEPA$\cdot$T2I, an extension of D-JEPA incorporating flow matching loss, designed to enable data-efficient continuous resolution learning. D-JEPA$\cdot$T2I leverages a multimodal visual transformer to effectively integrate textual and visual features and adopts Visual Rotary Positional Embedding (VoPE) to facilitate continuous resolution learning. Furthermore, we devise a data feedback mechanism that significantly enhances data utilization efficiency. For the first time, we achieve state-of-the-art \textbf{high-resolution} image synthesis via next-token prediction. The experimental code and pretrained models will be open-sourced at \url{https://d-jepa.github.io/t2i}.
BAGS: An automatic homework grading system using the pictures taken by smart phones
Jun 10, 2019

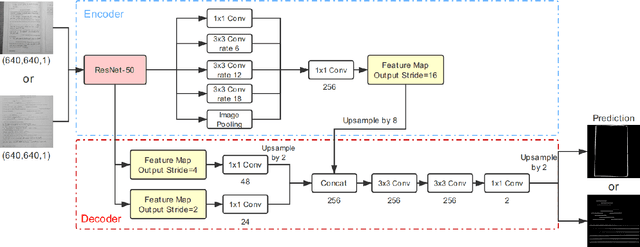

Homework grading is critical to evaluate teaching quality and effect. However, it is usually time-consuming to grade the homework manually. In automatic homework grading scenario, many optical mark reader (OMR)-based solutions which require specific equipments have been proposed. Although many of them can achieve relatively high accuracy, they are less convenient for users. In contrast, with the popularity of smart phones, the automatic grading system which depends on the image photographed by phones becomes more available. In practice, due to different photographing angles or uneven papers, images may be distorted. Moreover, most of images are photographed under complex backgrounds, making answer areas detection more difficult. To solve these problems, we propose BAGS, an automatic homework grading system which can effectively locate and recognize handwritten answers. In BAGS, all the answers would be written above the answer area underlines (AAU), and we use two segmentation networks based on DeepLabv3+ to locate the answer areas. Then, we use the characters recognition part to recognize students' answers. Finally, the grading part is designed for the comparison between the recognized answers and the standard ones. In our test, BAGS correctly locates and recognizes the handwritten answers in 91% of total answer areas.