 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk Awareness Injection: Calibrating Vision-Language Models for Safety without Compromising Utility
Feb 03, 2026Vision language models (VLMs) extend the reasoning capabilities of large language models (LLMs) to cross-modal settings, yet remain highly vulnerable to multimodal jailbreak attacks. Existing defenses predominantly rely on safety fine-tuning or aggressive token manipulations, incurring substantial training costs or significantly degrading utility. Recent research shows that LLMs inherently recognize unsafe content in text, and the incorporation of visual inputs in VLMs frequently dilutes risk-related signals. Motivated by this, we propose Risk Awareness Injection (RAI), a lightweight and training-free framework for safety calibration that restores LLM-like risk recognition by amplifying unsafe signals in VLMs. Specifically, RAI constructs an Unsafe Prototype Subspace from language embeddings and performs targeted modulation on selected high-risk visual tokens, explicitly activating safety-critical signals within the cross-modal feature space. This modulation restores the model's LLM-like ability to detect unsafe content from visual inputs, while preserving the semantic integrity of original tokens for cross-modal reasoning. Extensive experiments across multiple jailbreak and utility benchmarks demonstrate that RAI substantially reduces attack success rate without compromising task performance.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
FNBench: Benchmarking Robust Federated Learning against Noisy Labels
May 10, 2025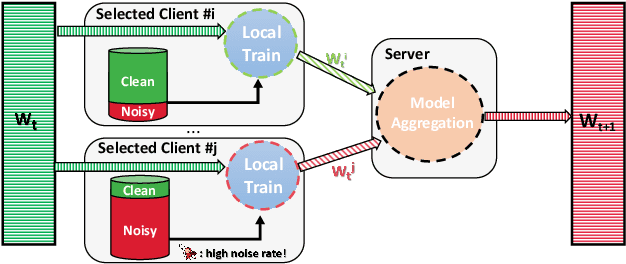
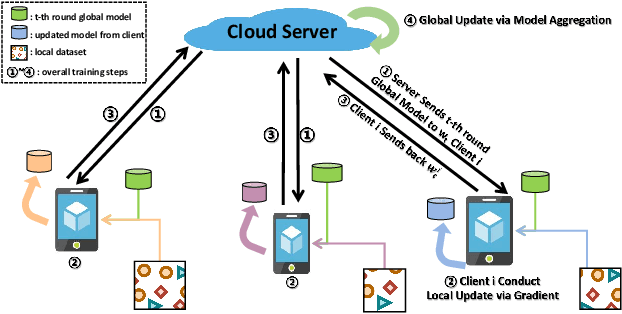
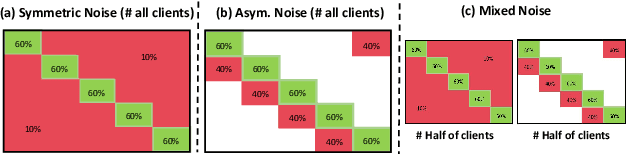
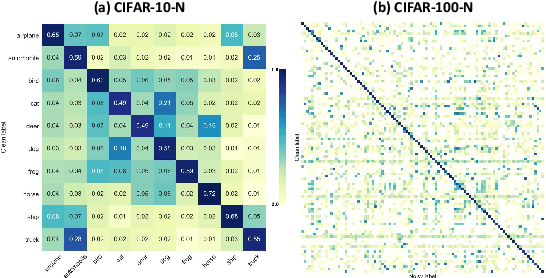
Robustness to label noise within data is a significant challenge in federated learning (FL). From the data-centric perspective, the data quality of distributed datasets can not be guaranteed since annotations of different clients contain complicated label noise of varying degrees, which causes the performance degradation. There have been some early attempts to tackle noisy labels in FL. However, there exists a lack of benchmark studies on comprehensively evaluating their practical performance under unified settings. To this end, we propose the first benchmark study FNBench to provide an experimental investigation which considers three diverse label noise patterns covering synthetic label noise, imperfect human-annotation errors and systematic errors. Our evaluation incorporates eighteen state-of-the-art methods over five image recognition datasets and one text classification dataset. Meanwhile, we provide observations to understand why noisy labels impair FL, and additionally exploit a representation-aware regularization method to enhance the robustness of existing methods against noisy labels based on our observations. Finally, we discuss the limitations of this work and propose three-fold future directions. To facilitate related communities, our source code is open-sourced at https://github.com/Sprinter1999/FNBench.
TextSplat: Text-Guided Semantic Fusion for Generalizable Gaussian Splatting
Apr 13, 2025Recent advancements in Generalizable Gaussian Splatting have enabled robust 3D reconstruction from sparse input views by utilizing feed-forward Gaussian Splatting models, achieving superior cross-scene generalization. However, while many methods focus on geometric consistency, they often neglect the potential of text-driven guidance to enhance semantic understanding, which is crucial for accurately reconstructing fine-grained details in complex scenes. To address this limitation, we propose TextSplat--the first text-driven Generalizable Gaussian Splatting framework. By employing a text-guided fusion of diverse semantic cues, our framework learns robust cross-modal feature representations that improve the alignment of geometric and semantic information, producing high-fidelity 3D reconstructions. Specifically, our framework employs three parallel modules to obtain complementary representations: the Diffusion Prior Depth Estimator for accurate depth information, the Semantic Aware Segmentation Network for detailed semantic information, and the Multi-View Interaction Network for refined cross-view features. Then, in the Text-Guided Semantic Fusion Module, these representations are integrated via the text-guided and attention-based feature aggregation mechanism, resulting in enhanced 3D Gaussian parameters enriched with detailed semantic cues. Experimental results on various benchmark datasets demonstrate improved performance compared to existing methods across multiple evaluation metrics, validating the effectiveness of our framework. The code will be publicly available.
BioChemInsight: An Open-Source Toolkit for Automated Identification and Recognition of Optical Chemical Structures and Activity Data in Scientific Publications
Apr 12, 2025Automated extraction of chemical structures and their bioactivity data is crucial for accelerating drug discovery and enabling data-driven pharmaceutical research. Existing optical chemical structure recognition (OCSR) tools fail to autonomously associate molecular structures with their bioactivity profiles, creating a critical bottleneck in structure-activity relationship (SAR) analysis. Here, we present BioChemInsight, an open-source pipeline that integrates: (1) DECIMER Segmentation and MolVec for chemical structure recognition, (2) Qwen2.5-VL-32B for compound identifier association, and (3) PaddleOCR with Gemini-2.0-flash for bioactivity extraction and unit normalization. We evaluated the performance of BioChemInsight on 25 patents and 17 articles. BioChemInsight achieved 95% accuracy for tabular patent data (structure/identifier recognition), with lower accuracy in non-tabular patents (~80% structures, ~75% identifiers), plus 92.2 % bioactivity extraction accuracy. For articles, it attained >99% identifiers and 78-80% structure accuracy in non-tabular formats, plus 97.4% bioactivity extraction accuracy. The system generates ready-to-use SAR datasets, reducing data preprocessing time from weeks to hours while enabling applications in high-throughput screening and ML-driven drug design (https://github.com/dahuilangda/BioChemInsight).
Safe-VAR: Safe Visual Autoregressive Model for Text-to-Image Generative Watermarking
Mar 14, 2025With the success of autoregressive learning in large language models, it has become a dominant approach for text-to-image generation, offering high efficiency and visual quality. However, invisible watermarking for visual autoregressive (VAR) models remains underexplored, despite its importance in misuse prevention. Existing watermarking methods, designed for diffusion models, often struggle to adapt to the sequential nature of VAR models. To bridge this gap, we propose Safe-VAR, the first watermarking framework specifically designed for autoregressive text-to-image generation. Our study reveals that the timing of watermark injection significantly impacts generation quality, and watermarks of different complexities exhibit varying optimal injection times. Motivated by this observation, we propose an Adaptive Scale Interaction Module, which dynamically determines the optimal watermark embedding strategy based on the watermark information and the visual characteristics of the generated image. This ensures watermark robustness while minimizing its impact on image quality. Furthermore, we introduce a Cross-Scale Fusion mechanism, which integrates mixture of both heads and experts to effectively fuse multi-resolution features and handle complex interactions between image content and watermark patterns. Experimental results demonstrate that Safe-VAR achieves state-of-the-art performance, significantly surpassing existing counterparts regarding image quality, watermarking fidelity, and robustness against perturbations. Moreover, our method exhibits strong generalization to an out-of-domain watermark dataset QR Codes.
Inter3D: A Benchmark and Strong Baseline for Human-Interactive 3D Object Reconstruction
Feb 19, 2025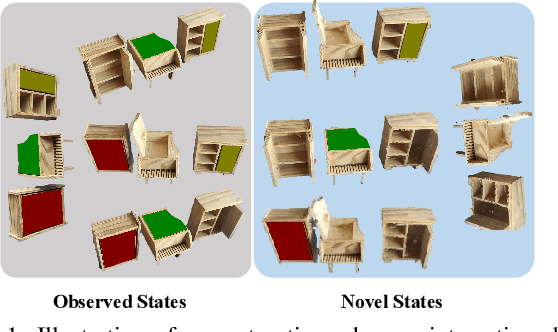

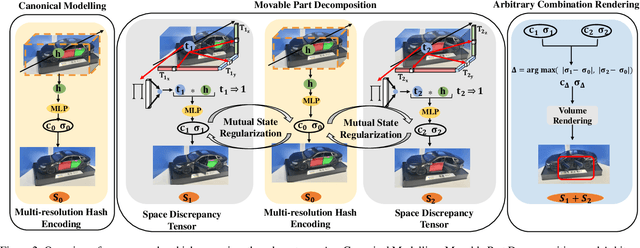

Recent advancements in implicit 3D reconstruction methods, e.g., neural rendering fields and Gaussian splatting, have primarily focused on novel view synthesis of static or dynamic objects with continuous motion states. However, these approaches struggle to efficiently model a human-interactive object with n movable parts, requiring 2^n separate models to represent all discrete states. To overcome this limitation, we propose Inter3D, a new benchmark and approach for novel state synthesis of human-interactive objects. We introduce a self-collected dataset featuring commonly encountered interactive objects and a new evaluation pipeline, where only individual part states are observed during training, while part combination states remain unseen. We also propose a strong baseline approach that leverages Space Discrepancy Tensors to efficiently modelling all states of an object. To alleviate the impractical constraints on camera trajectories across training states, we propose a Mutual State Regularization mechanism to enhance the spatial density consistency of movable parts. In addition, we explore two occupancy grid sampling strategies to facilitate training efficiency. We conduct extensive experiments on the proposed benchmark, showcasing the challenges of the task and the superiority of our approach.
Detail-Preserving Latent Diffusion for Stable Shadow Removal
Dec 23, 2024Achieving high-quality shadow removal with strong generalizability is challenging in scenes with complex global illumination. Due to the limited diversity in shadow removal datasets, current methods are prone to overfitting training data, often leading to reduced performance on unseen cases. To address this, we leverage the rich visual priors of a pre-trained Stable Diffusion (SD) model and propose a two-stage fine-tuning pipeline to adapt the SD model for stable and efficient shadow removal. In the first stage, we fix the VAE and fine-tune the denoiser in latent space, which yields substantial shadow removal but may lose some high-frequency details. To resolve this, we introduce a second stage, called the detail injection stage. This stage selectively extracts features from the VAE encoder to modulate the decoder, injecting fine details into the final results. Experimental results show that our method outperforms state-of-the-art shadow removal techniques. The cross-dataset evaluation further demonstrates that our method generalizes effectively to unseen data, enhancing the applicability of shadow removal methods.
Prediction-Enhanced Monte Carlo: A Machine Learning View on Control Variate
Dec 15, 2024



Despite being an essential tool across engineering and finance, Monte Carlo simulation can be computationally intensive, especially in large-scale, path-dependent problems that hinder straightforward parallelization. A natural alternative is to replace simulation with machine learning or surrogate prediction, though this introduces challenges in understanding the resulting errors.We introduce a Prediction-Enhanced Monte Carlo (PEMC) framework where we leverage machine learning prediction as control variates, thus maintaining unbiased evaluations instead of the direct use of ML predictors. Traditional control variate methods require knowledge of means and focus on per-sample variance reduction. In contrast, PEMC aims at overall cost-aware variance reduction, eliminating the need for mean knowledge. PEMC leverages pre-trained neural architectures to construct effective control variates and replaces computationally expensive sample-path generation with efficient neural network evaluations. This allows PEMC to address scenarios where no good control variates are known. We showcase the efficacy of PEMC through two production-grade exotic option-pricing problems: swaption pricing in HJM model and the variance swap pricing in a stochastic local volatility model.
Hierarchical Search-Based Cooperative Motion Planning
Oct 21, 2024



Cooperative path planning, a crucial aspect of multi-agent systems research, serves a variety of sectors, including military, agriculture, and industry. Many existing algorithms, however, come with certain limitations, such as simplified kinematic models and inadequate support for multiple group scenarios. Focusing on the planning problem associated with a nonholonomic Ackermann model for Unmanned Ground Vehicles (UGV), we propose a leaderless, hierarchical Search-Based Cooperative Motion Planning (SCMP) method. The high-level utilizes a binary conflict search tree to minimize runtime, while the low-level fabricates kinematically feasible, collision-free paths that are shape-constrained. Our algorithm can adapt to scenarios featuring multiple groups with different shapes, outlier agents, and elaborate obstacles. We conduct algorithm comparisons, performance testing, simulation, and real-world testing, verifying the effectiveness and applicability of our algorithm. The implementation of our method will be open-sourced at https://github.com/WYCUniverStar/SCMP.