 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of Stickers on Multimodal Chat Sentiment Analysis and Intent Recognition: A New Task, Dataset and Baseline
May 14, 2024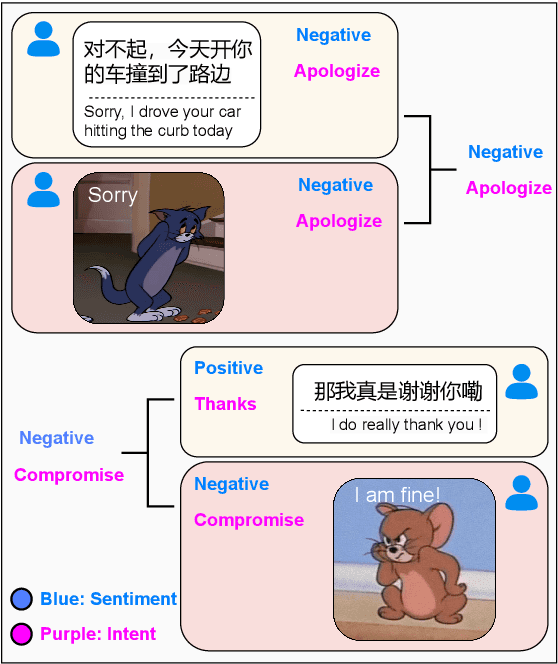
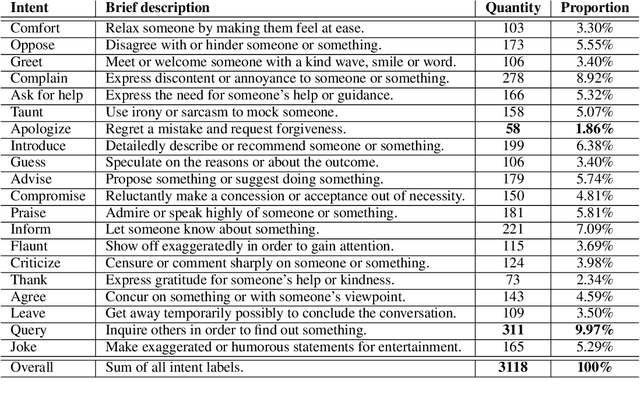
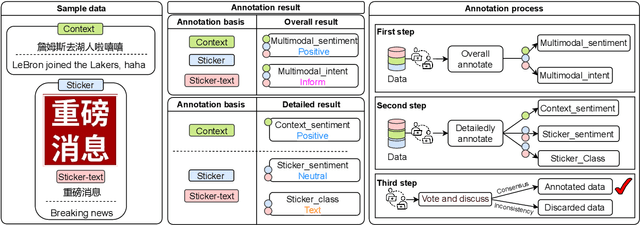
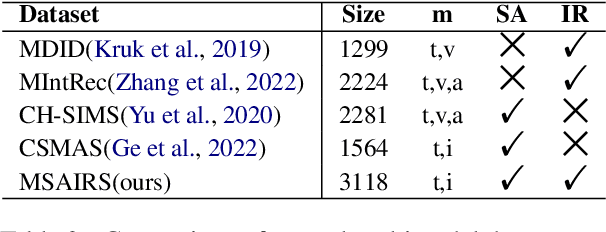
Stickers are increasingly used in social media to express sentiment and intent. When finding typing troublesome, people often use a sticker instead. Despite the significant impact of stickers on sentiment analysis and intent recognition, little research has been conducted. To address this gap, we propose a new task: Multimodal chat Sentiment Analysis and Intent Recognition involving Stickers (MSAIRS). Additionally, we introduce a novel multimodal dataset containing Chinese chat records and stickers excerpted from several mainstream social media platforms. Our dataset includes paired data with the same text but different stickers, and various stickers consisting of the same images with different texts, allowing us to better understand the impact of stickers on chat sentiment and intent. We also propose an effective multimodal joint model, MMSAIR, for our task, which is validated on our datasets and indicates that visual information of stickers counts. Our dataset and code will be publicly available.
Semantic-aware Generation of Multi-view Portrait Drawings
May 04, 2023



Neural radiance fields (NeRF) based methods have shown amazing performance in synthesizing 3D-consistent photographic images, but fail to generate multi-view portrait drawings. The key is that the basic assumption of these methods -- a surface point is consistent when rendered from different views -- doesn't hold for drawings. In a portrait drawing, the appearance of a facial point may changes when viewed from different angles. Besides, portrait drawings usually present little 3D information and suffer from insufficient training data. To combat this challenge, in this paper, we propose a Semantic-Aware GEnerator (SAGE) for synthesizing multi-view portrait drawings. Our motivation is that facial semantic labels are view-consistent and correlate with drawing techniques. We therefore propose to collaboratively synthesize multi-view semantic maps and the corresponding portrait drawings. To facilitate training, we design a semantic-aware domain translator, which generates portrait drawings based on features of photographic faces. In addition, use data augmentation via synthesis to mitigate collapsed results. We apply SAGE to synthesize multi-view portrait drawings in diverse artistic styles. Experimental results show that SAGE achieves significantly superior or highly competitive performance, compared to existing 3D-aware image synthesis methods. The codes are available at https://github.com/AiArt-HDU/SAGE.
Masked and Adaptive Transformer for Exemplar Based Image Translation
Mar 30, 2023


We present a novel framework for exemplar based image translation. Recent advanced methods for this task mainly focus on establishing cross-domain semantic correspondence, which sequentially dominates image generation in the manner of local style control. Unfortunately, cross-domain semantic matching is challenging; and matching errors ultimately degrade the quality of generated images. To overcome this challenge, we improve the accuracy of matching on the one hand, and diminish the role of matching in image generation on the other hand. To achieve the former, we propose a masked and adaptive transformer (MAT) for learning accurate cross-domain correspondence, and executing context-aware feature augmentation. To achieve the latter, we use source features of the input and global style codes of the exemplar, as supplementary information, for decoding an image. Besides, we devise a novel contrastive style learning method, for acquire quality-discriminative style representations, which in turn benefit high-quality image generation. Experimental results show that our method, dubbed MATEBIT, performs considerably better than state-of-the-art methods, in diverse image translation tasks. The codes are available at \url{https://github.com/AiArt-HDU/MATEBIT}.
A Novel Speech Feature Fusion Algorithm for Text-Independent Speaker Recognition
Dec 01, 2022A novel speech feature fusion algorithm with independent vector analysis (IVA) and parallel convolutional neural network (PCNN) is proposed for text-independent speaker recognition. Firstly, some different feature types, such as the time domain (TD) features and the frequency domain (FD) features, can be extracted from a speaker's speech, and the TD and the FD features can be considered as the linear mixtures of independent feature components (IFCs) with an unknown mixing system. To estimate the IFCs, the TD and the FD features of the speaker's speech are concatenated to build the TD and the FD feature matrix, respectively. Then, a feature tensor of the speaker's speech is obtained by paralleling the TD and the FD feature matrix. To enhance the dependence on different feature types and remove the redundancies of the same feature type, the independent vector analysis (IVA) can be used to estimate the IFC matrices of TD and FD features with the feature tensor. The IFC matrices are utilized as the input of the PCNN to extract the deep features of the TD and FD features, respectively. The deep features can be integrated to obtain the fusion feature of the speaker's speech. Finally, the fusion feature of the speaker's speech is employed as the input of a deep convolutional neural network (DCNN) classifier for speaker recognition. The experimental results show the effectiveness and performances of the proposed speaker recognition system.