 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmartEval: A Benchmark for Evaluating LLM-Generated Smart Contracts from Natural Language Specifications
May 10, 2026We introduce SmartEval, a benchmark for systematically evaluating the quality of Solidity smart contracts generated by large language models (LLMs) from natural language specifications. SmartEval provides a corpus of 9,000 generated contracts paired with expert-written ground-truth implementations drawn from the FSMSCG dataset, a five-dimensional evaluation rubric covering functional completeness, variable fidelity, state-machine correctness, business-logic fidelity, and code quality, and a reproducible generation-and-evaluation pipeline. To validate the benchmark's reliability, we conduct three independent empirical studies: a five-condition ablation study (N=300 per condition) isolating the contribution of each pipeline component, a human expert evaluation by three Columbia University PhD researchers confirming automated scores align with expert judgment to within 0.34 points, and external security analysis via the Slither static analyzer confirming 79.4% agreement between the LLM auditor and a non-LLM rule-based tool. Systematic analysis of 9,000 generated contracts reveals characteristic failure modes (logic omissions at 35.3%, state transition errors at 23.4%, and complexity-driven degradation) and quantifies a +8.29 composite-score advantage of generated contracts over ground-truth implementations, attributable to LLMs' literal specification-following behavior. SmartEval establishes a reproducible, validated foundation for empirical research on LLM smart contract synthesis quality, with all data, evaluation code, and generated contracts publicly released.
PREFER: Personalized Review Summarization with Online Preference Learning
May 07, 2026Product reviews significantly influence purchasing decisions on e-commerce platforms. However, the sheer volume of reviews can overwhelm users, obscuring the information most relevant to their specific needs. Current e-commerce summarization systems typically produce generic, static summaries that fail to account for the fact that (i) different users care about different product characteristics, and (ii) these preferences may evolve with interactions. To address the challenge of unknown latent preferences, we propose an online learning framework that generates personalized summaries for each user. Our system iteratively refines its understanding of user preferences by incorporating feedback directly from the generated summaries over time. We provide a case study using the Amazon Reviews'23 dataset, showing in controlled simulations that online preference learning improves alignment with target user interests while maintaining summary quality.
Designing Agentic AI-Based Screening for Portfolio Investment
Mar 24, 2026We introduce a new agentic artificial intelligence (AI) platform for portfolio management. Our architecture consists of three layers. First, two large language model (LLM) agents are assigned specialized tasks: one agent screens for firms with desirable fundamentals, while a sentiment analysis agent screens for firms with desirable news. Second, these agents deliberate to generate and agree upon buy and sell signals from a large portfolio, substantially narrowing the pool of candidate assets. Finally, we apply a high-dimensional precision matrix estimation procedure to determine optimal portfolio weights. A defining theoretical feature of our framework is that the number of assets in the portfolio is itself a random variable, realized through the screening process. We introduce the concept of sensible screening and establish that, under mild screening errors, the squared Sharpe ratio of the screened portfolio consistently estimates its target. Empirically, our method achieves superior Sharpe ratios relative to an unscreened baseline portfolio and to conventional screening approaches, evaluated on S&P 500 data over the period 2020--2024.
An end-to-end agentic pipeline for smart contract translation and quality evaluation
Feb 14, 2026We present an end-to-end framework for systematic evaluation of LLM-generated smart contracts from natural-language specifications. The system parses contractual text into structured schemas, generates Solidity code, and performs automated quality assessment through compilation and security checks. Using CrewAI-style agent teams with iterative refinement, the pipeline produces structured artifacts with full provenance metadata. Quality is measured across five dimensions, including functional completeness, variable fidelity, state-machine correctness, business-logic fidelity, and code quality aggregated into composite scores. The framework supports paired evaluation against ground-truth implementations, quantifying alignment and identifying systematic error modes such as logic omissions and state transition inconsistencies. This provides a reproducible benchmark for empirical research on smart contract synthesis quality and supports extensions to formal verification and compliance checking.
The Nonstationarity-Complexity Tradeoff in Return Prediction
Dec 29, 2025We investigate machine learning models for stock return prediction in non-stationary environments, revealing a fundamental nonstationarity-complexity tradeoff: complex models reduce misspecification error but require longer training windows that introduce stronger non-stationarity. We resolve this tension with a novel model selection method that jointly optimizes model class and training window size using a tournament procedure that adaptively evaluates candidates on non-stationary validation data. Our theoretical analysis demonstrates that this approach balances misspecification error, estimation variance, and non-stationarity, performing close to the best model in hindsight. Applying our method to 17 industry portfolio returns, we consistently outperform standard rolling-window benchmarks, improving out-of-sample $R^2$ by 14-23% on average. During NBER-designated recessions, improvements are substantial: our method achieves positive $R^2$ during the Gulf War recession while benchmarks are negative, and improves $R^2$ in absolute terms by at least 80bps during the 2001 recession as well as superior performance during the 2008 Financial Crisis. Economically, a trading strategy based on our selected model generates 31% higher cumulative returns averaged across the industries.
Prediction-Enhanced Monte Carlo: A Machine Learning View on Control Variate
Dec 15, 2024



Despite being an essential tool across engineering and finance, Monte Carlo simulation can be computationally intensive, especially in large-scale, path-dependent problems that hinder straightforward parallelization. A natural alternative is to replace simulation with machine learning or surrogate prediction, though this introduces challenges in understanding the resulting errors.We introduce a Prediction-Enhanced Monte Carlo (PEMC) framework where we leverage machine learning prediction as control variates, thus maintaining unbiased evaluations instead of the direct use of ML predictors. Traditional control variate methods require knowledge of means and focus on per-sample variance reduction. In contrast, PEMC aims at overall cost-aware variance reduction, eliminating the need for mean knowledge. PEMC leverages pre-trained neural architectures to construct effective control variates and replaces computationally expensive sample-path generation with efficient neural network evaluations. This allows PEMC to address scenarios where no good control variates are known. We showcase the efficacy of PEMC through two production-grade exotic option-pricing problems: swaption pricing in HJM model and the variance swap pricing in a stochastic local volatility model.
Causal Inference (C-inf) -- asymmetric scenario of typical phase transitions
Jan 02, 2023In this paper, we revisit and further explore a mathematically rigorous connection between Causal inference (C-inf) and the Low-rank recovery (LRR) established in [10]. Leveraging the Random duality - Free probability theory (RDT-FPT) connection, we obtain the exact explicit typical C-inf asymmetric phase transitions (PT). We uncover a doubling low-rankness phenomenon, which means that exactly two times larger low rankness is allowed in asymmetric scenarios compared to the symmetric worst case ones considered in [10]. Consequently, the final PT mathematical expressions are as elegant as those obtained in [10], and highlight direct relations between the targeted C-inf matrix low rankness and the time of treatment. Our results have strong implications for applications, where C-inf matrices are not necessarily symmetric.
Causal Inference (C-inf) -- closed form worst case typical phase transitions
Jan 02, 2023In this paper we establish a mathematically rigorous connection between Causal inference (C-inf) and the low-rank recovery (LRR). Using Random Duality Theory (RDT) concepts developed in [46,48,50] and novel mathematical strategies related to free probability theory, we obtain the exact explicit typical (and achievable) worst case phase transitions (PT). These PT precisely separate scenarios where causal inference via LRR is possible from those where it is not. We supplement our mathematical analysis with numerical experiments that confirm the theoretical predictions of PT phenomena, and further show that the two closely match for fairly small sample sizes. We obtain simple closed form representations for the resulting PTs, which highlight direct relations between the low rankness of the target C-inf matrix and the time of the treatment. Hence, our results can be used to determine the range of C-inf's typical applicability.
Robo-advising: Learning Investors' Risk Preferences via Portfolio Choices
Nov 16, 2019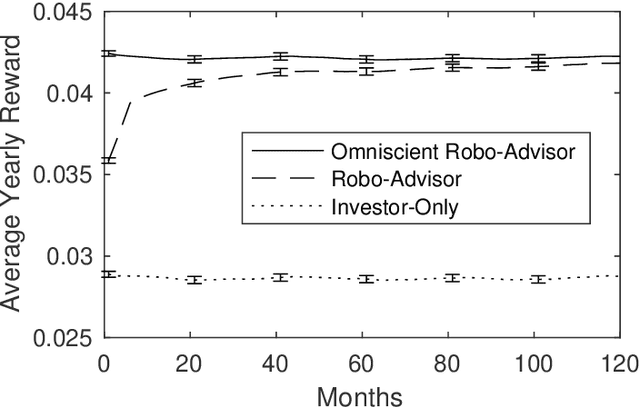

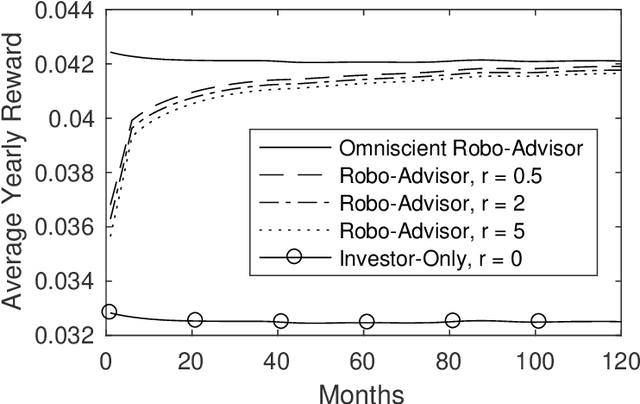
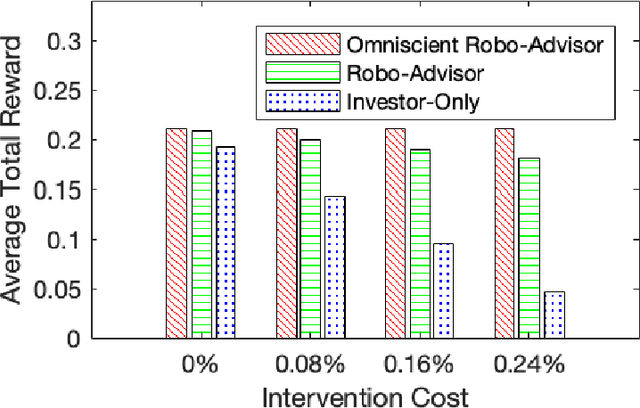
We introduce a reinforcement learning framework for retail robo-advising. The robo-advisor does not know the investor's risk preference, but learns it over time by observing her portfolio choices in different market environments. We develop an exploration-exploitation algorithm which trades off costly solicitations of portfolio choices by the investor with autonomous trading decisions based on stale estimates of investor's risk aversion. We show that the algorithm's value function converges to the optimal value function of an omniscient robo-advisor over a number of periods that is polynomial in the state and action space. By correcting for the investor's mistakes, the robo-advisor may outperform a stand-alone investor, regardless of the investor's opportunity cost for making portfolio decisions.
Risk-Sensitive Cooperative Games for Human-Machine Systems
May 26, 2017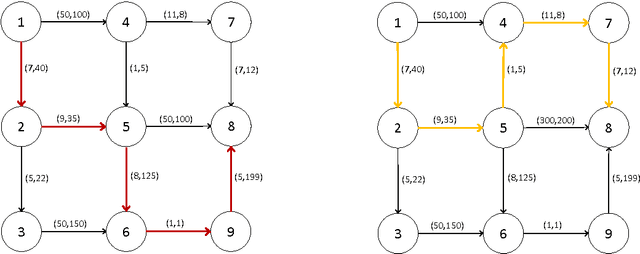
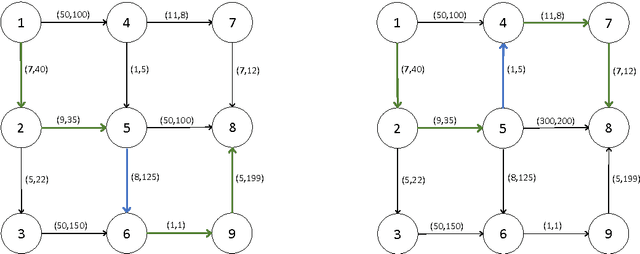
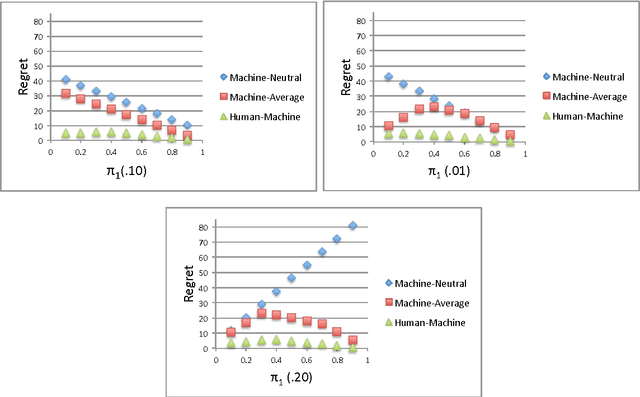
Autonomous systems can substantially enhance a human's efficiency and effectiveness in complex environments. Machines, however, are often unable to observe the preferences of the humans that they serve. Despite the fact that the human's and machine's objectives are aligned, asymmetric information, along with heterogeneous sensitivities to risk by the human and machine, make their joint optimization process a game with strategic interactions. We propose a framework based on risk-sensitive dynamic games; the human seeks to optimize her risk-sensitive criterion according to her true preferences, while the machine seeks to adaptively learn the human's preferences and at the same time provide a good service to the human. We develop a class of performance measures for the proposed framework based on the concept of regret. We then evaluate their dependence on the risk-sensitivity and the degree of uncertainty. We present applications of our framework to self-driving taxis, and robo-financial advising.