 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTMI: Segmentation-Guided Token Modulation with Cross-Modal Hypergraph Interaction for Multi-Modal Object Re-Identification
Feb 28, 2026Multi-modal object Re-Identification (ReID) aims to exploit complementary information from different modalities to retrieve specific objects. However, existing methods often rely on hard token filtering or simple fusion strategies, which can lead to the loss of discriminative cues and increased background interference. To address these challenges, we propose STMI, a novel multi-modal learning framework consisting of three key components: (1) Segmentation-Guided Feature Modulation (SFM) module leverages SAM-generated masks to enhance foreground representations and suppress background noise through learnable attention modulation; (2) Semantic Token Reallocation (STR) module employs learnable query tokens and an adaptive reallocation mechanism to extract compact and informative representations without discarding any tokens; (3) Cross-Modal Hypergraph Interaction (CHI) module constructs a unified hypergraph across modalities to capture high-order semantic relationships. Extensive experiments on public benchmarks (i.e., RGBNT201, RGBNT100, and MSVR310) demonstrate the effectiveness and robustness of our proposed STMI framework in multi-modal ReID scenarios.
Mobile-Agent-v3.5: Multi-platform Fundamental GUI Agents
Feb 15, 2026The paper introduces GUI-Owl-1.5, the latest native GUI agent model that features instruct/thinking variants in multiple sizes (2B/4B/8B/32B/235B) and supports a range of platforms (desktop, mobile, browser, and more) to enable cloud-edge collaboration and real-time interaction. GUI-Owl-1.5 achieves state-of-the-art results on more than 20+ GUI benchmarks on open-source models: (1) on GUI automation tasks, it obtains 56.5 on OSWorld, 71.6 on AndroidWorld, and 48.4 on WebArena; (2) on grounding tasks, it obtains 80.3 on ScreenSpotPro; (3) on tool-calling tasks, it obtains 47.6 on OSWorld-MCP, and 46.8 on MobileWorld; (4) on memory and knowledge tasks, it obtains 75.5 on GUI-Knowledge Bench. GUI-Owl-1.5 incorporates several key innovations: (1) Hybird Data Flywheel: we construct the data pipeline for UI understanding and trajectory generation based on a combination of simulated environments and cloud-based sandbox environments, in order to improve the efficiency and quality of data collection. (2) Unified Enhancement of Agent Capabilities: we use a unified thought-synthesis pipeline to enhance the model's reasoning capabilities, while placing particular emphasis on improving key agent abilities, including Tool/MCP use, memory and multi-agent adaptation; (3) Multi-platform Environment RL Scaling: We propose a new environment RL algorithm, MRPO, to address the challenges of multi-platform conflicts and the low training efficiency of long-horizon tasks. The GUI-Owl-1.5 models are open-sourced, and an online cloud-sandbox demo is available at https://github.com/X-PLUG/MobileAgent.
High-Fidelity and Long-Duration Human Image Animation with Diffusion Transformer
Dec 26, 2025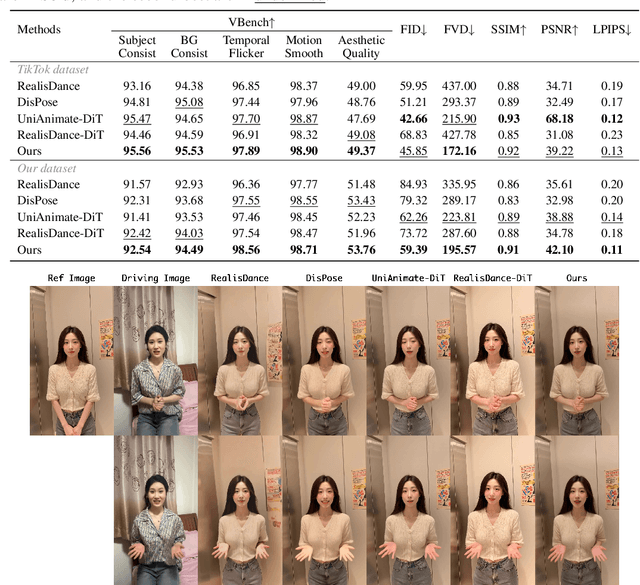

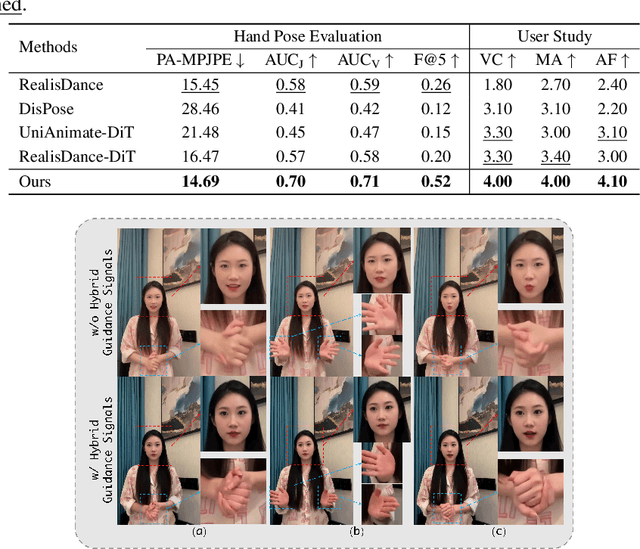
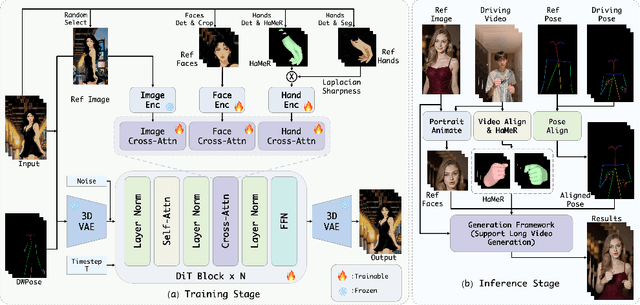
Recent progress in diffusion models has significantly advanced the field of human image animation. While existing methods can generate temporally consistent results for short or regular motions, significant challenges remain, particularly in generating long-duration videos. Furthermore, the synthesis of fine-grained facial and hand details remains under-explored, limiting the applicability of current approaches in real-world, high-quality applications. To address these limitations, we propose a diffusion transformer (DiT)-based framework which focuses on generating high-fidelity and long-duration human animation videos. First, we design a set of hybrid implicit guidance signals and a sharpness guidance factor, enabling our framework to additionally incorporate detailed facial and hand features as guidance. Next, we incorporate the time-aware position shift fusion module, modify the input format within the DiT backbone, and refer to this mechanism as the Position Shift Adaptive Module, which enables video generation of arbitrary length. Finally, we introduce a novel data augmentation strategy and a skeleton alignment model to reduce the impact of human shape variations across different identities. Experimental results demonstrate that our method outperforms existing state-of-the-art approaches, achieving superior performance in both high-fidelity and long-duration human image animation.
Comprehend and Talk: Text to Speech Synthesis via Dual Language Modeling
Sep 26, 2025Existing Large Language Model (LLM) based autoregressive (AR) text-to-speech (TTS) systems, while achieving state-of-the-art quality, still face critical challenges. The foundation of this LLM-based paradigm is the discretization of the continuous speech waveform into a sequence of discrete tokens by neural audio codec. However, single codebook modeling is well suited to text LLMs, but suffers from significant information loss; hierarchical acoustic tokens, typically generated via Residual Vector Quantization (RVQ), often lack explicit semantic structure, placing a heavy learning burden on the model. Furthermore, the autoregressive process is inherently susceptible to error accumulation, which can degrade generation stability. To address these limitations, we propose CaT-TTS, a novel framework for robust and semantically-grounded zero-shot synthesis. First, we introduce S3Codec, a split RVQ codec that injects explicit linguistic features into its primary codebook via semantic distillation from a state-of-the-art ASR model, providing a structured representation that simplifies the learning task. Second, we propose an ``Understand-then-Generate'' dual-Transformer architecture that decouples comprehension from rendering. An initial ``Understanding'' Transformer models the cross-modal relationship between text and the audio's semantic tokens to form a high-level utterance plan. A subsequent ``Generation'' Transformer then executes this plan, autoregressively synthesizing hierarchical acoustic tokens. Finally, to enhance generation stability, we introduce Masked Audio Parallel Inference (MAPI), a nearly parameter-free inference strategy that dynamically guides the decoding process to mitigate local errors.
Mobile-Agent-v3: Foundamental Agents for GUI Automation
Aug 21, 2025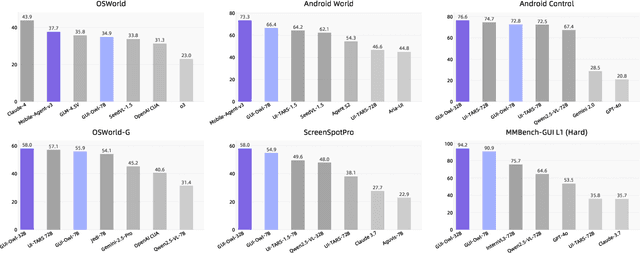
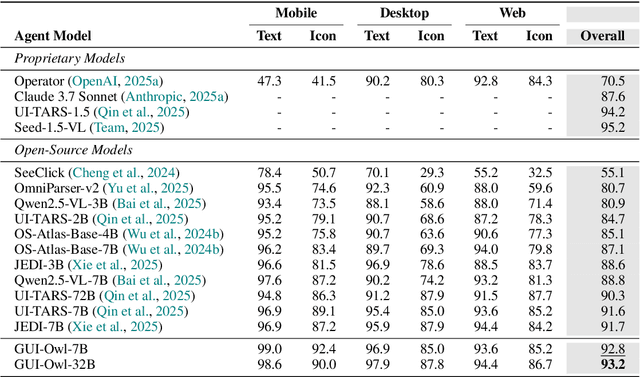
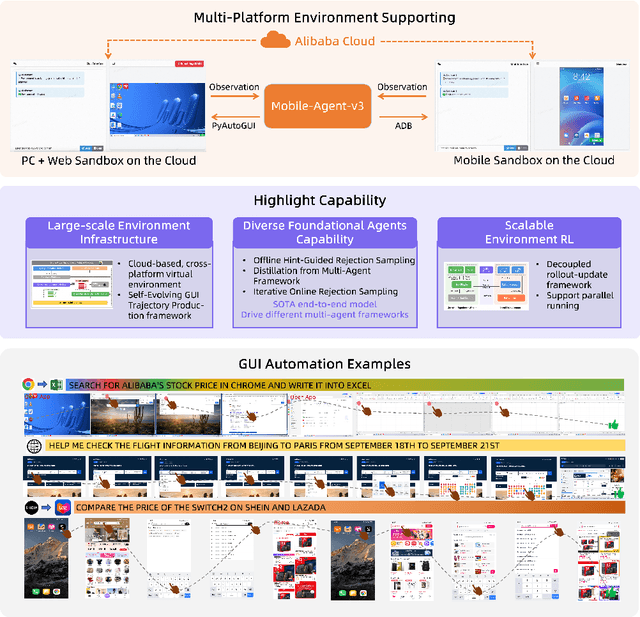
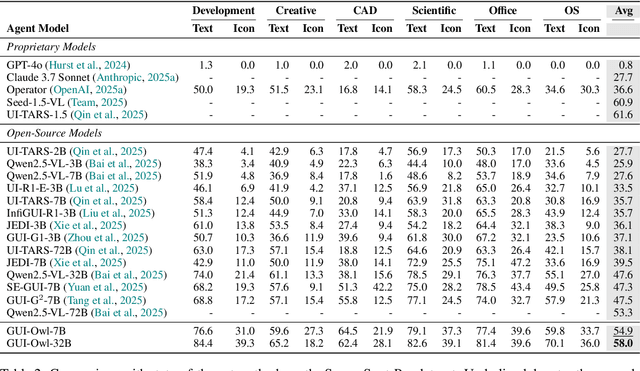
This paper introduces GUI-Owl, a foundational GUI agent model that achieves state-of-the-art performance among open-source end-to-end models on ten GUI benchmarks across desktop and mobile environments, covering grounding, question answering, planning, decision-making, and procedural knowledge. GUI-Owl-7B achieves 66.4 on AndroidWorld and 29.4 on OSWorld. Building on this, we propose Mobile-Agent-v3, a general-purpose GUI agent framework that further improves performance to 73.3 on AndroidWorld and 37.7 on OSWorld, setting a new state-of-the-art for open-source GUI agent frameworks. GUI-Owl incorporates three key innovations: (1) Large-scale Environment Infrastructure: a cloud-based virtual environment spanning Android, Ubuntu, macOS, and Windows, enabling our Self-Evolving GUI Trajectory Production framework. This generates high-quality interaction data via automated query generation and correctness validation, leveraging GUI-Owl to refine trajectories iteratively, forming a self-improving loop. It supports diverse data pipelines and reduces manual annotation. (2) Diverse Foundational Agent Capabilities: by integrating UI grounding, planning, action semantics, and reasoning patterns, GUI-Owl supports end-to-end decision-making and can act as a modular component in multi-agent systems. (3) Scalable Environment RL: we develop a scalable reinforcement learning framework with fully asynchronous training for real-world alignment. We also introduce Trajectory-aware Relative Policy Optimization (TRPO) for online RL, achieving 34.9 on OSWorld. GUI-Owl and Mobile-Agent-v3 are open-sourced at https://github.com/X-PLUG/MobileAgent.
Adaptive Duration Model for Text Speech Alignment
Jul 30, 2025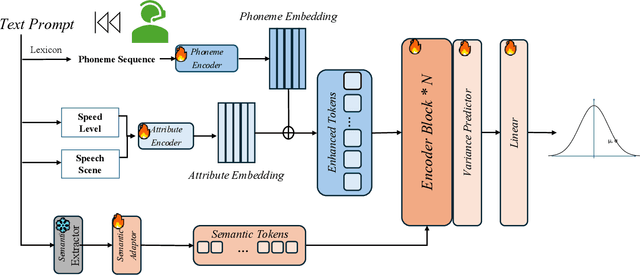



Speech-to-text alignment is a critical component of neural text to-speech (TTS) models. Autoregressive TTS models typically use an attention mechanism to learn these alignments on-line. However, these alignments tend to be brittle and often fail to generalize to long utterances and out-of-domain text, leading to missing or repeating words. Most non-autoregressive end to-end TTS models rely on durations extracted from external sources, using additional duration models for alignment. In this paper, we propose a novel duration prediction framework that can give compromising phoneme-level duration distribution with given text. In our experiments, the proposed duration model has more precise prediction and condition adaptation ability compared to previous baseline models. Numerically, it has roughly a 11.3 percents immprovement on alignment accuracy, and makes the performance of zero-shot TTS models more robust to the mismatch between prompt audio and input audio.
Quantize More, Lose Less: Autoregressive Generation from Residually Quantized Speech Representations
Jul 16, 2025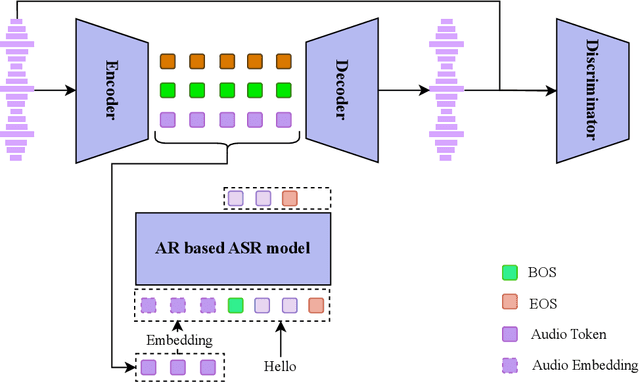

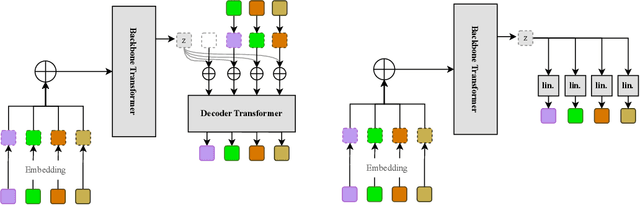
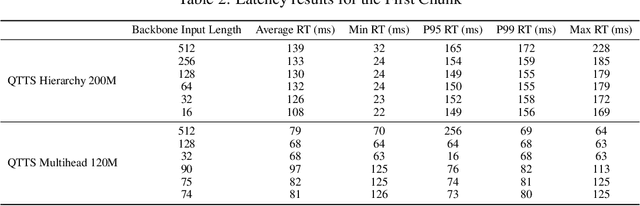
Text-to-speech (TTS) synthesis has seen renewed progress under the discrete modeling paradigm. Existing autoregressive approaches often rely on single-codebook representations, which suffer from significant information loss. Even with post-hoc refinement techniques such as flow matching, these methods fail to recover fine-grained details (e.g., prosodic nuances, speaker-specific timbres), especially in challenging scenarios like singing voice or music synthesis. We propose QTTS, a novel TTS framework built upon our new audio codec, QDAC. The core innovation of QDAC lies in its end-to-end training of an ASR-based auto-regressive network with a GAN, which achieves superior semantic feature disentanglement for scalable, near-lossless compression. QTTS models these discrete codes using two innovative strategies: the Hierarchical Parallel architecture, which uses a dual-AR structure to model inter-codebook dependencies for higher-quality synthesis, and the Delay Multihead approach, which employs parallelized prediction with a fixed delay to accelerate inference speed. Our experiments demonstrate that the proposed framework achieves higher synthesis quality and better preserves expressive content compared to baseline. This suggests that scaling up compression via multi-codebook modeling is a promising direction for high-fidelity, general-purpose speech and audio generation.
LeCoDe: A Benchmark Dataset for Interactive Legal Consultation Dialogue Evaluation
May 26, 2025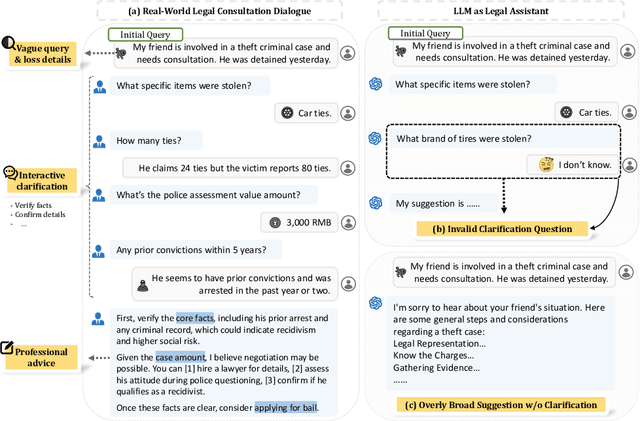


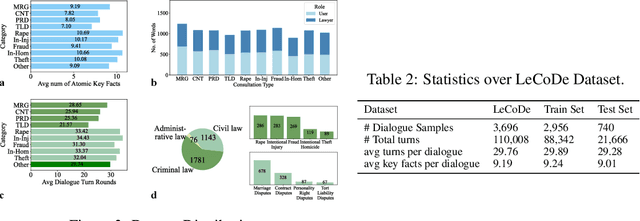
Legal consultation is essential for safeguarding individual rights and ensuring access to justice, yet remains costly and inaccessible to many individuals due to the shortage of professionals. While recent advances in Large Language Models (LLMs) offer a promising path toward scalable, low-cost legal assistance, current systems fall short in handling the interactive and knowledge-intensive nature of real-world consultations. To address these challenges, we introduce LeCoDe, a real-world multi-turn benchmark dataset comprising 3,696 legal consultation dialogues with 110,008 dialogue turns, designed to evaluate and improve LLMs' legal consultation capability. With LeCoDe, we innovatively collect live-streamed consultations from short-video platforms, providing authentic multi-turn legal consultation dialogues. The rigorous annotation by legal experts further enhances the dataset with professional insights and expertise. Furthermore, we propose a comprehensive evaluation framework that assesses LLMs' consultation capabilities in terms of (1) clarification capability and (2) professional advice quality. This unified framework incorporates 12 metrics across two dimensions. Through extensive experiments on various general and domain-specific LLMs, our results reveal significant challenges in this task, with even state-of-the-art models like GPT-4 achieving only 39.8% recall for clarification and 59% overall score for advice quality, highlighting the complexity of professional consultation scenarios. Based on these findings, we further explore several strategies to enhance LLMs' legal consultation abilities. Our benchmark contributes to advancing research in legal domain dialogue systems, particularly in simulating more real-world user-expert interactions.
Towards Stepwise Domain Knowledge-Driven Reasoning Optimization and Reflection Improvement
Apr 12, 2025
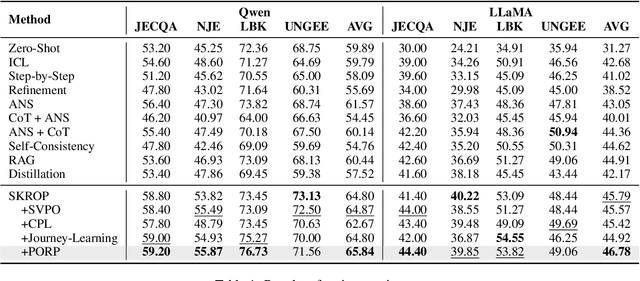
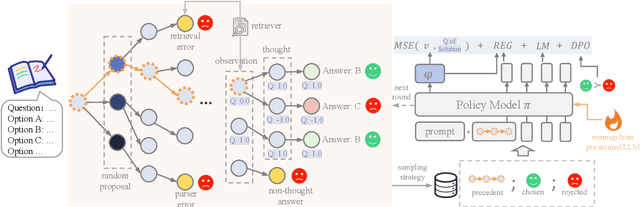
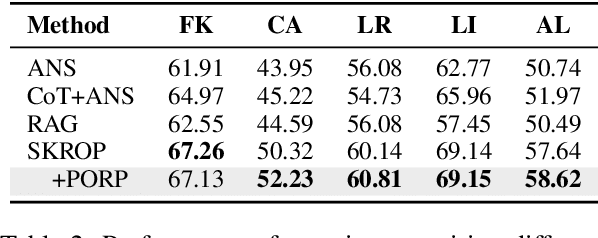
Recently, stepwise supervision on Chain of Thoughts (CoTs) presents an enhancement on the logical reasoning tasks such as coding and math, with the help of Monte Carlo Tree Search (MCTS). However, its contribution to tasks requiring domain-specific expertise and knowledge remains unexplored. Motivated by the interest, we identify several potential challenges of vanilla MCTS within this context, and propose the framework of Stepwise Domain Knowledge-Driven Reasoning Optimization, employing the MCTS algorithm to develop step-level supervision for problems that require essential comprehension, reasoning, and specialized knowledge. Additionally, we also introduce the Preference Optimization towards Reflection Paths, which iteratively learns self-reflection on the reasoning thoughts from better perspectives. We have conducted extensive experiments to evaluate the advantage of the methodologies. Empirical results demonstrate the effectiveness on various legal-domain problems. We also report a diverse set of valuable findings, hoping to encourage the enthusiasm to the research of domain-specific LLMs and MCTS.
DisPose: Disentangling Pose Guidance for Controllable Human Image Animation
Dec 13, 2024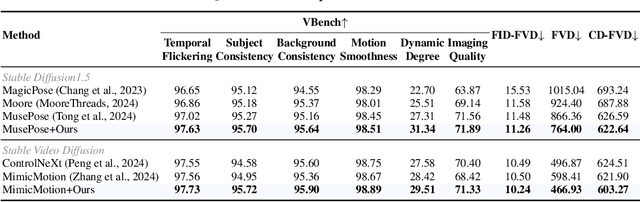
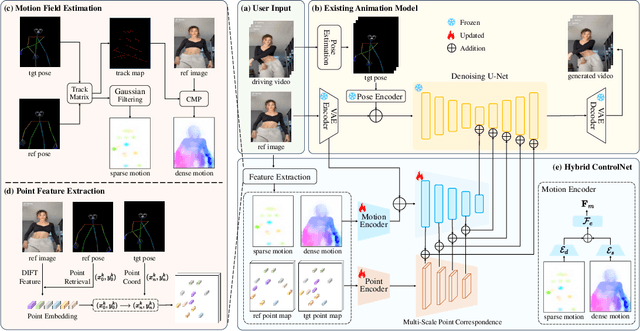
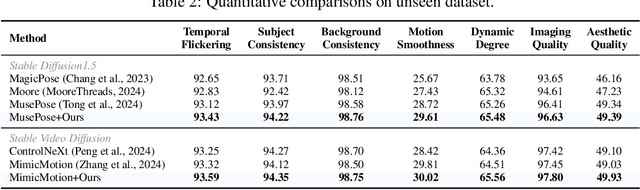

Controllable human image animation aims to generate videos from reference images using driving videos. Due to the limited control signals provided by sparse guidance (e.g., skeleton pose), recent works have attempted to introduce additional dense conditions (e.g., depth map) to ensure motion alignment. However, such strict dense guidance impairs the quality of the generated video when the body shape of the reference character differs significantly from that of the driving video. In this paper, we present DisPose to mine more generalizable and effective control signals without additional dense input, which disentangles the sparse skeleton pose in human image animation into motion field guidance and keypoint correspondence. Specifically, we generate a dense motion field from a sparse motion field and the reference image, which provides region-level dense guidance while maintaining the generalization of the sparse pose control. We also extract diffusion features corresponding to pose keypoints from the reference image, and then these point features are transferred to the target pose to provide distinct identity information. To seamlessly integrate into existing models, we propose a plug-and-play hybrid ControlNet that improves the quality and consistency of generated videos while freezing the existing model parameters. Extensive qualitative and quantitative experiments demonstrate the superiority of DisPose compared to current methods. Code: \href{https://github.com/lihxxx/DisPose}{https://github.com/lihxxx/DisPose}.