 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReDiStory: Region-Disentangled Diffusion for Consistent Visual Story Generation
Feb 01, 2026Generating coherent visual stories requires maintaining subject identity across multiple images while preserving frame-specific semantics. Recent training-free methods concatenate identity and frame prompts into a unified representation, but this often introduces inter-frame semantic interference that weakens identity preservation in complex stories. We propose ReDiStory, a training-free framework that improves multi-frame story generation via inference-time prompt embedding reorganization. ReDiStory explicitly decomposes text embeddings into identity-related and frame-specific components, then decorrelates frame embeddings by suppressing shared directions across frames. This reduces cross-frame interference without modifying diffusion parameters or requiring additional supervision. Under identical diffusion backbones and inference settings, ReDiStory improves identity consistency while maintaining prompt fidelity. Experiments on the ConsiStory+ benchmark show consistent gains over 1Prompt1Story on multiple identity consistency metrics. Code is available at: https://github.com/YuZhenyuLindy/ReDiStory
StoryState: Agent-Based State Control for Consistent and Editable Storybooks
Feb 01, 2026Large multimodal models have enabled one-click storybook generation, where users provide a short description and receive a multi-page illustrated story. However, the underlying story state, such as characters, world settings, and page-level objects, remains implicit, making edits coarse-grained and often breaking visual consistency. We present StoryState, an agent-based orchestration layer that introduces an explicit and editable story state on top of training-free text-to-image generation. StoryState represents each story as a structured object composed of a character sheet, global settings, and per-page scene constraints, and employs a small set of LLM agents to maintain this state and derive 1Prompt1Story-style prompts for generation and editing. Operating purely through prompts, StoryState is model-agnostic and compatible with diverse generation backends. System-level experiments on multi-page editing tasks show that StoryState enables localized page edits, improves cross-page consistency, and reduces unintended changes, interaction turns, and editing time compared to 1Prompt1Story, while approaching the one-shot consistency of Gemini Storybook. Code is available at https://github.com/YuZhenyuLindy/StoryState
LamiGauss: Pitching Radiative Gaussian for Sparse-View X-ray Laminography Reconstruction
Sep 17, 2025



X-ray Computed Laminography (CL) is essential for non-destructive inspection of plate-like structures in applications such as microchips and composite battery materials, where traditional computed tomography (CT) struggles due to geometric constraints. However, reconstructing high-quality volumes from laminographic projections remains challenging, particularly under highly sparse-view acquisition conditions. In this paper, we propose a reconstruction algorithm, namely LamiGauss, that combines Gaussian Splatting radiative rasterization with a dedicated detector-to-world transformation model incorporating the laminographic tilt angle. LamiGauss leverages an initialization strategy that explicitly filters out common laminographic artifacts from the preliminary reconstruction, preventing redundant Gaussians from being allocated to false structures and thereby concentrating model capacity on representing the genuine object. Our approach effectively optimizes directly from sparse projections, enabling accurate and efficient reconstruction with limited data. Extensive experiments on both synthetic and real datasets demonstrate the effectiveness and superiority of the proposed method over existing techniques. LamiGauss uses only 3$\%$ of full views to achieve superior performance over the iterative method optimized on a full dataset.
Blind Restoration of High-Resolution Ultrasound Video
May 20, 2025Ultrasound imaging is widely applied in clinical practice, yet ultrasound videos often suffer from low signal-to-noise ratios (SNR) and limited resolutions, posing challenges for diagnosis and analysis. Variations in equipment and acquisition settings can further exacerbate differences in data distribution and noise levels, reducing the generalizability of pre-trained models. This work presents a self-supervised ultrasound video super-resolution algorithm called Deep Ultrasound Prior (DUP). DUP employs a video-adaptive optimization process of a neural network that enhances the resolution of given ultrasound videos without requiring paired training data while simultaneously removing noise. Quantitative and visual evaluations demonstrate that DUP outperforms existing super-resolution algorithms, leading to substantial improvements for downstream applications.
Circular Image Deturbulence using Quasi-conformal Geometry
Apr 21, 2025The presence of inhomogeneous media between optical sensors and objects leads to distorted imaging outputs, significantly complicating downstream image-processing tasks. A key challenge in image restoration is the lack of high-quality, paired-label images required for training supervised models. In this paper, we introduce the Circular Quasi-Conformal Deturbulence (CQCD) framework, an unsupervised approach for removing image distortions through a circular architecture. This design ensures that the restored image remains both geometrically accurate and visually faithful while preventing the accumulation of incorrect estimations. The circular restoration process involves both forward and inverse mapping. To ensure the bijectivity of the estimated non-rigid deformations, computational quasi-conformal geometry theories are leveraged to regularize the mapping, enforcing its homeomorphic properties. This guarantees a well-defined transformation that preserves structural integrity and prevents unwanted artifacts. Furthermore, tight-frame blocks are integrated to encode distortion-sensitive features for precise recovery. To validate the performance of our approach, we conduct evaluations on various synthetic and real-world captured images. Experimental results demonstrate that CQCD not only outperforms existing state-of-the-art deturbulence methods in terms of image restoration quality but also provides highly accurate deformation field estimations.
Implicit Regression in Subspace for High-Sensitivity CEST Imaging
Jul 09, 2024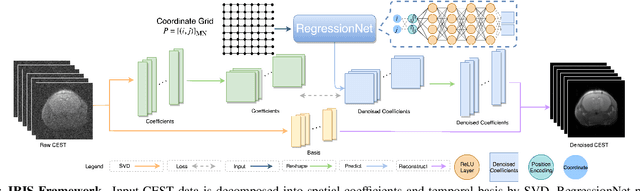
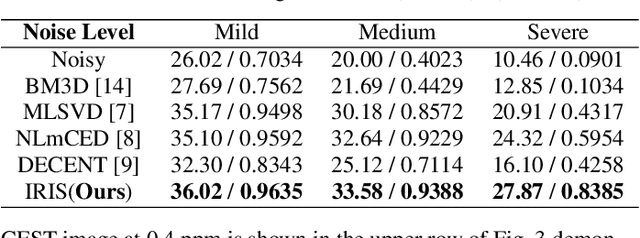
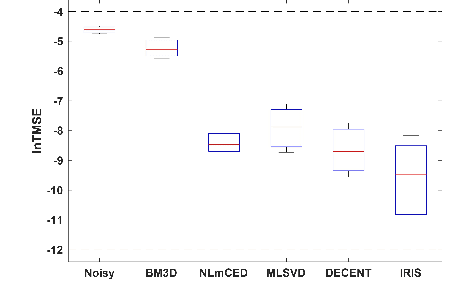
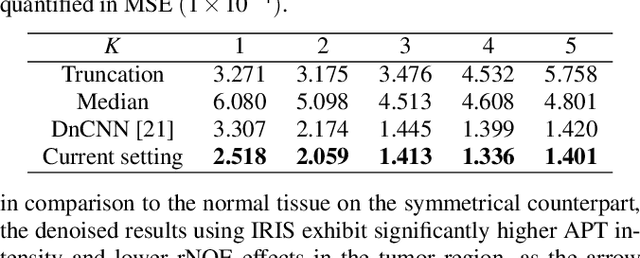
Chemical Exchange Saturation Transfer (CEST) MRI demonstrates its capability in significantly enhancing the detection of proteins and metabolites with low concentrations through exchangeable protons. The clinical application of CEST, however, is constrained by its low contrast and low signal-to-noise ratio (SNR) in the acquired data. Denoising, as one of the post-processing stages for CEST data, can effectively improve the accuracy of CEST quantification. In this work, by modeling spatial variant z-spectrums into low-dimensional subspace, we introduce Implicit Regression in Subspace (IRIS), which is an unsupervised denoising algorithm utilizing the excellent property of implicit neural representation for continuous mapping. Experiments conducted on both synthetic and in-vivo data demonstrate that our proposed method surpasses other CEST denoising methods regarding both qualitative and quantitative performance.
DMNR: Unsupervised De-noising of Point Clouds Corrupted by Airborne Particles
May 10, 2023
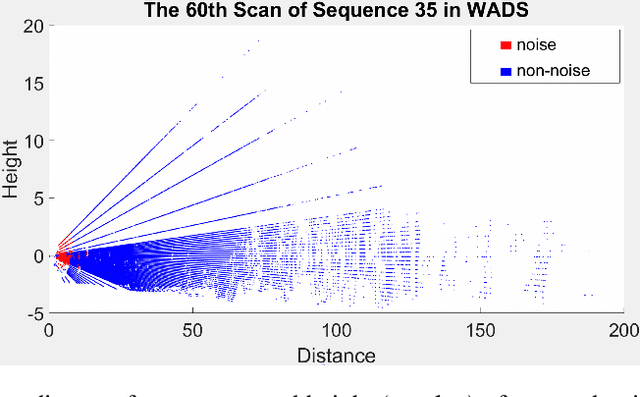
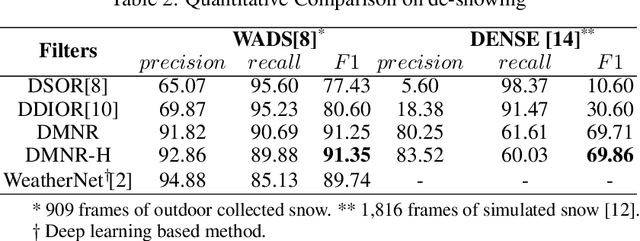

LiDAR sensors are critical for autonomous driving and robotics applications due to their ability to provide accurate range measurements and their robustness to lighting conditions. However, airborne particles, such as fog, rain, snow, and dust, will degrade its performance and it is inevitable to encounter these inclement environmental conditions outdoors. It would be a straightforward approach to remove them by supervised semantic segmentation. But annotating these particles point wisely is too laborious. To address this problem and enhance the perception under inclement conditions, we develop two dynamic filtering methods called Dynamic Multi-threshold Noise Removal (DMNR) and DMNR-H by accurate analysis of the position distribution and intensity characteristics of noisy points and clean points on publicly available WADS and DENSE datasets. Both DMNR and DMNR-H outperform state-of-the-art unsupervised methods by a significant margin on the two datasets and are slightly better than supervised deep learning-based methods. Furthermore, our methods are more robust to different LiDAR sensors and airborne particles, such as snow and fog.
EBM Life Cycle: MCMC Strategies for Synthesis, Defense, and Density Modeling
May 24, 2022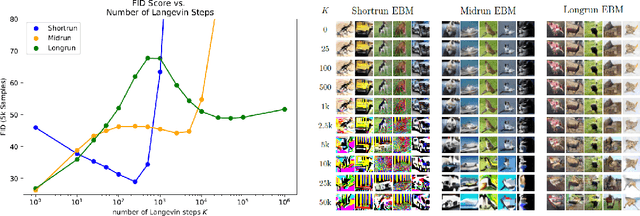

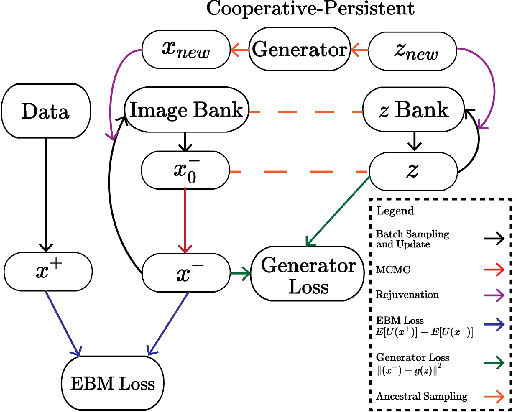
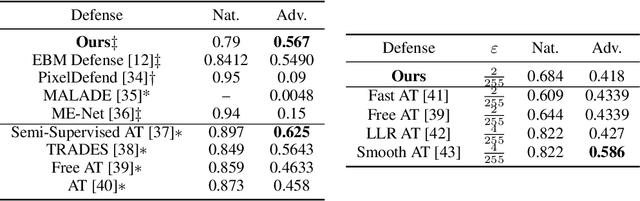
This work presents strategies to learn an Energy-Based Model (EBM) according to the desired length of its MCMC sampling trajectories. MCMC trajectories of different lengths correspond to models with different purposes. Our experiments cover three different trajectory magnitudes and learning outcomes: 1) shortrun sampling for image generation; 2) midrun sampling for classifier-agnostic adversarial defense; and 3) longrun sampling for principled modeling of image probability densities. To achieve these outcomes, we introduce three novel methods of MCMC initialization for negative samples used in Maximum Likelihood (ML) learning. With standard network architectures and an unaltered ML objective, our MCMC initialization methods alone enable significant performance gains across the three applications that we investigate. Our results include state-of-the-art FID scores for unnormalized image densities on the CIFAR-10 and ImageNet datasets; state-of-the-art adversarial defense on CIFAR-10 among purification methods and the first EBM defense on ImageNet; and scalable techniques for learning valid probability densities. Code for this project can be found at https://github.com/point0bar1/ebm-life-cycle.