 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLamiGauss: Pitching Radiative Gaussian for Sparse-View X-ray Laminography Reconstruction
Sep 17, 2025



X-ray Computed Laminography (CL) is essential for non-destructive inspection of plate-like structures in applications such as microchips and composite battery materials, where traditional computed tomography (CT) struggles due to geometric constraints. However, reconstructing high-quality volumes from laminographic projections remains challenging, particularly under highly sparse-view acquisition conditions. In this paper, we propose a reconstruction algorithm, namely LamiGauss, that combines Gaussian Splatting radiative rasterization with a dedicated detector-to-world transformation model incorporating the laminographic tilt angle. LamiGauss leverages an initialization strategy that explicitly filters out common laminographic artifacts from the preliminary reconstruction, preventing redundant Gaussians from being allocated to false structures and thereby concentrating model capacity on representing the genuine object. Our approach effectively optimizes directly from sparse projections, enabling accurate and efficient reconstruction with limited data. Extensive experiments on both synthetic and real datasets demonstrate the effectiveness and superiority of the proposed method over existing techniques. LamiGauss uses only 3$\%$ of full views to achieve superior performance over the iterative method optimized on a full dataset.
Blind Restoration of High-Resolution Ultrasound Video
May 20, 2025Ultrasound imaging is widely applied in clinical practice, yet ultrasound videos often suffer from low signal-to-noise ratios (SNR) and limited resolutions, posing challenges for diagnosis and analysis. Variations in equipment and acquisition settings can further exacerbate differences in data distribution and noise levels, reducing the generalizability of pre-trained models. This work presents a self-supervised ultrasound video super-resolution algorithm called Deep Ultrasound Prior (DUP). DUP employs a video-adaptive optimization process of a neural network that enhances the resolution of given ultrasound videos without requiring paired training data while simultaneously removing noise. Quantitative and visual evaluations demonstrate that DUP outperforms existing super-resolution algorithms, leading to substantial improvements for downstream applications.
Bilateral Signal Warping for Left Ventricular Hypertrophy Diagnosis
Nov 13, 2024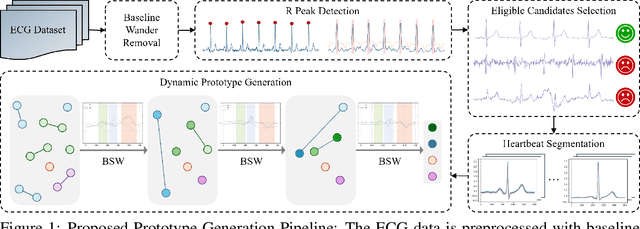
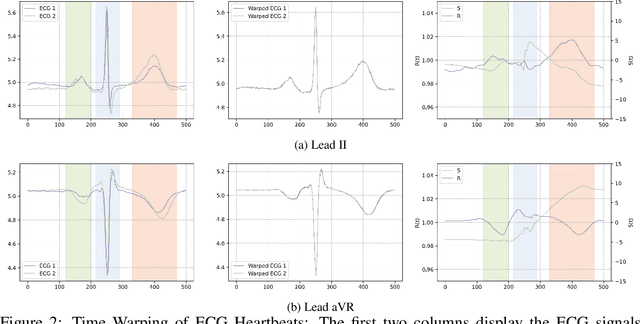
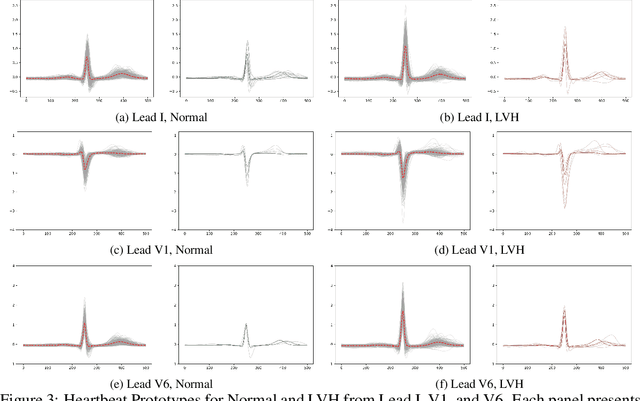
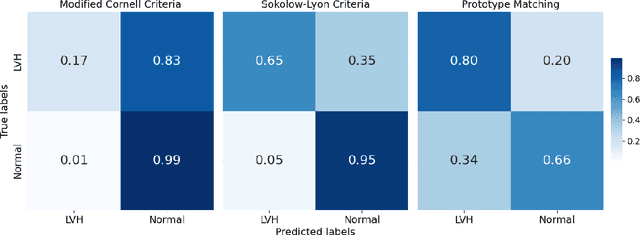
Left Ventricular Hypertrophy (LVH) is a major cardiovascular risk factor, linked to heart failure, arrhythmia, and sudden cardiac death, often resulting from chronic stress like hypertension. Electrocardiography (ECG), while varying in sensitivity, is widely accessible and cost-effective for detecting LVH-related morphological changes. This work introduces a bilateral signal warping (BSW) approach to improve ECG-based LVH diagnosis. Our method creates a library of heartbeat prototypes from patients with consistent ECG patterns. After preprocessing to eliminate baseline wander and detect R peaks, we apply BSW to cluster heartbeats, generating prototypes for both normal and LVH classes. We compare each new record to these references to support diagnosis. Experimental results show promising potential for practical application in clinical settings.
PiLocNet: Physics-informed neural network on 3D localization with rotating point spread function
Oct 17, 2024



For the 3D localization problem using point spread function (PSF) engineering, we propose a novel enhancement of our previously introduced localization neural network, LocNet. The improved network is a physics-informed neural network (PINN) that we call PiLocNet. Previous works on the localization problem may be categorized separately into model-based optimization and neural network approaches. Our PiLocNet combines the unique strengths of both approaches by incorporating forward-model-based information into the network via a data-fitting loss term that constrains the neural network to yield results that are physically sensible. We additionally incorporate certain regularization terms from the variational method, which further improves the robustness of the network in the presence of image noise, as we show for the Poisson and Gaussian noise models. This framework accords interpretability to the neural network, and the results we obtain show its superiority. Although the paper focuses on the use of single-lobe rotating PSF to encode the full 3D source location, we expect the method to be widely applicable to other PSFs and imaging problems that are constrained by known forward processes.
Super-resolving Real-world Image Illumination Enhancement: A New Dataset and A Conditional Diffusion Model
Oct 16, 2024



Most existing super-resolution methods and datasets have been developed to improve the image quality in well-lighted conditions. However, these methods do not work well in real-world low-light conditions as the images captured in such conditions lose most important information and contain significant unknown noises. To solve this problem, we propose a SRRIIE dataset with an efficient conditional diffusion probabilistic models-based method. The proposed dataset contains 4800 paired low-high quality images. To ensure that the dataset are able to model the real-world image degradation in low-illumination environments, we capture images using an ILDC camera and an optical zoom lens with exposure levels ranging from -6 EV to 0 EV and ISO levels ranging from 50 to 12800. We comprehensively evaluate with various reconstruction and perceptual metrics and demonstrate the practicabilities of the SRRIIE dataset for deep learning-based methods. We show that most existing methods are less effective in preserving the structures and sharpness of restored images from complicated noises. To overcome this problem, we revise the condition for Raw sensor data and propose a novel time-melding condition for diffusion probabilistic model. Comprehensive quantitative and qualitative experimental results on the real-world benchmark datasets demonstrate the feasibility and effectivenesses of the proposed conditional diffusion probabilistic model on Raw sensor data. Code and dataset will be available at https://github.com/Yaofang-Liu/Super-Resolving
Real-Time Localization and Bimodal Point Pattern Analysis of Palms Using UAV Imagery
Oct 14, 2024



Understanding the spatial distribution of palms within tropical forests is essential for effective ecological monitoring, conservation strategies, and the sustainable integration of natural forest products into local and global supply chains. However, the analysis of remotely sensed data in these environments faces significant challenges, such as overlapping palm and tree crowns, uneven shading across the canopy surface, and the heterogeneous nature of the forest landscapes, which often affect the performance of palm detection and segmentation algorithms. To overcome these issues, we introduce PalmDSNet, a deep learning framework for real-time detection, segmentation, and counting of canopy palms. Additionally, we employ a bimodal reproduction algorithm that simulates palm spatial propagation to further enhance the understanding of these point patterns using PalmDSNet's results. We used UAV-captured imagery to create orthomosaics from 21 sites across western Ecuadorian tropical forests, covering a gradient from the everwet Choc\'o forests near Colombia to the drier forests of southwestern Ecuador. Expert annotations were used to create a comprehensive dataset, including 7,356 bounding boxes on image patches and 7,603 palm centers across five orthomosaics, encompassing a total area of 449 hectares. By combining PalmDSNet with the bimodal reproduction algorithm, which optimizes parameters for both local and global spatial variability, we effectively simulate the spatial distribution of palms in diverse and dense tropical environments, validating its utility for advanced applications in tropical forest monitoring and remote sensing analysis.
A Mathematical Explanation of UNet
Oct 06, 2024



The UNet architecture has transformed image segmentation. UNet's versatility and accuracy have driven its widespread adoption, significantly advancing fields reliant on machine learning problems with images. In this work, we give a clear and concise mathematical explanation of UNet. We explain what is the meaning and function of each of the components of UNet. We will show that UNet is solving a control problem. We decompose the control variables using multigrid methods. Then, operator-splitting techniques is used to solve the problem, whose architecture exactly recovers the UNet architecture. Our result shows that UNet is a one-step operator-splitting algorithm for the control problem.
Redefining Temporal Modeling in Video Diffusion: The Vectorized Timestep Approach
Oct 04, 2024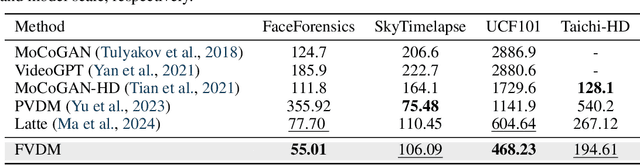
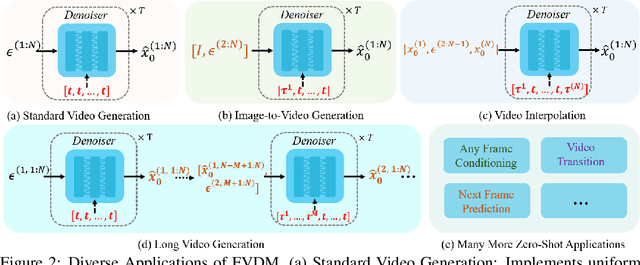
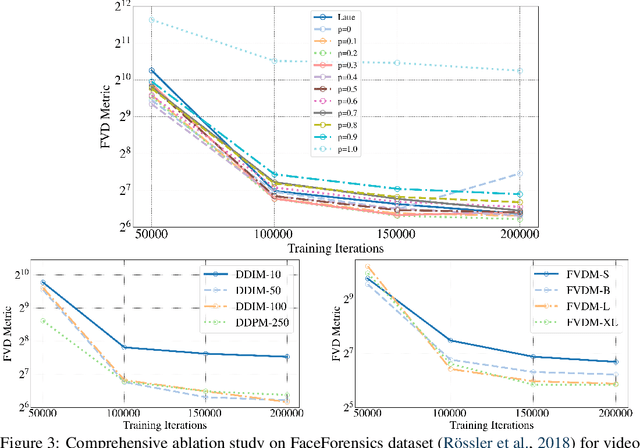

Diffusion models have revolutionized image generation, and their extension to video generation has shown promise. However, current video diffusion models~(VDMs) rely on a scalar timestep variable applied at the clip level, which limits their ability to model complex temporal dependencies needed for various tasks like image-to-video generation. To address this limitation, we propose a frame-aware video diffusion model~(FVDM), which introduces a novel vectorized timestep variable~(VTV). Unlike conventional VDMs, our approach allows each frame to follow an independent noise schedule, enhancing the model's capacity to capture fine-grained temporal dependencies. FVDM's flexibility is demonstrated across multiple tasks, including standard video generation, image-to-video generation, video interpolation, and long video synthesis. Through a diverse set of VTV configurations, we achieve superior quality in generated videos, overcoming challenges such as catastrophic forgetting during fine-tuning and limited generalizability in zero-shot methods.Our empirical evaluations show that FVDM outperforms state-of-the-art methods in video generation quality, while also excelling in extended tasks. By addressing fundamental shortcomings in existing VDMs, FVDM sets a new paradigm in video synthesis, offering a robust framework with significant implications for generative modeling and multimedia applications.
Superpixel-based and Spatially-regularized Diffusion Learning for Unsupervised Hyperspectral Image Clustering
Dec 24, 2023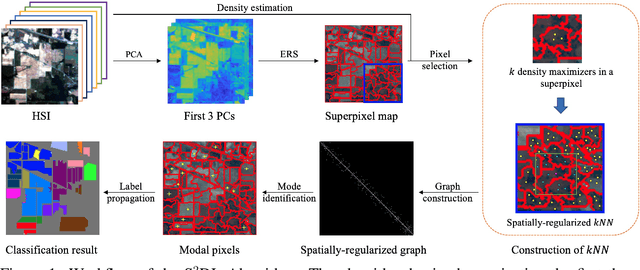
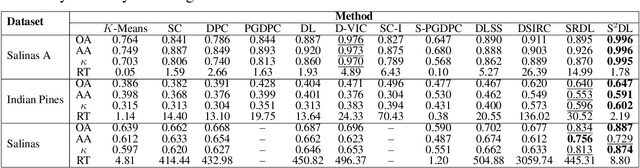

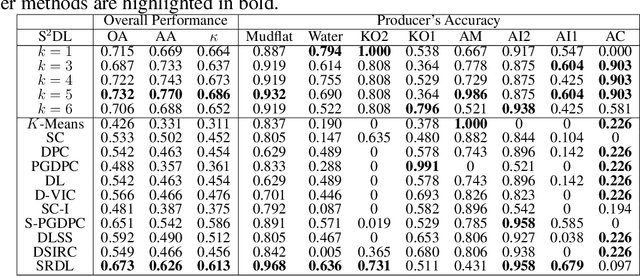
Hyperspectral images (HSIs) provide exceptional spatial and spectral resolution of a scene, crucial for various remote sensing applications. However, the high dimensionality, presence of noise and outliers, and the need for precise labels of HSIs present significant challenges to HSIs analysis, motivating the development of performant HSI clustering algorithms. This paper introduces a novel unsupervised HSI clustering algorithm, Superpixel-based and Spatially-regularized Diffusion Learning (S2DL), which addresses these challenges by incorporating rich spatial information encoded in HSIs into diffusion geometry-based clustering. S2DL employs the Entropy Rate Superpixel (ERS) segmentation technique to partition an image into superpixels, then constructs a spatially-regularized diffusion graph using the most representative high-density pixels. This approach reduces computational burden while preserving accuracy. Cluster modes, serving as exemplars for underlying cluster structure, are identified as the highest-density pixels farthest in diffusion distance from other highest-density pixels. These modes guide the labeling of the remaining representative pixels from ERS superpixels. Finally, majority voting is applied to the labels assigned within each superpixel to propagate labels to the rest of the image. This spatial-spectral approach simultaneously simplifies graph construction, reduces computational cost, and improves clustering performance. S2DL's performance is illustrated with extensive experiments on three publicly available, real-world HSIs: Indian Pines, Salinas, and Salinas A. Additionally, we apply S2DL to landscape-scale, unsupervised mangrove species mapping in the Mai Po Nature Reserve, Hong Kong, using a Gaofen-5 HSI. The success of S2DL in these diverse numerical experiments indicates its efficacy on a wide range of important unsupervised remote sensing analysis tasks.
Single-Shot Plug-and-Play Methods for Inverse Problems
Nov 22, 2023



The utilisation of Plug-and-Play (PnP) priors in inverse problems has become increasingly prominent in recent years. This preference is based on the mathematical equivalence between the general proximal operator and the regularised denoiser, facilitating the adaptation of various off-the-shelf denoiser priors to a wide range of inverse problems. However, existing PnP models predominantly rely on pre-trained denoisers using large datasets. In this work, we introduce Single-Shot PnP methods (SS-PnP), shifting the focus to solving inverse problems with minimal data. First, we integrate Single-Shot proximal denoisers into iterative methods, enabling training with single instances. Second, we propose implicit neural priors based on a novel function that preserves relevant frequencies to capture fine details while avoiding the issue of vanishing gradients. We demonstrate, through extensive numerical and visual experiments, that our method leads to better approximations.