 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlphaFace: High Fidelity and Real-time Face Swapper Robust to Facial Pose
Jan 23, 2026Existing face-swapping methods often deliver competitive results in constrained settings but exhibit substantial quality degradation when handling extreme facial poses. To improve facial pose robustness, explicit geometric features are applied, but this approach remains problematic since it introduces additional dependencies and increases computational cost. Diffusion-based methods have achieved remarkable results; however, they are impractical for real-time processing. We introduce AlphaFace, which leverages an open-source vision-language model and CLIP image and text embeddings to apply novel visual and textual semantic contrastive losses. AlphaFace enables stronger identity representation and more precise attribute preservation, all while maintaining real-time performance. Comprehensive experiments across FF++, MPIE, and LPFF demonstrate that AlphaFace surpasses state-of-the-art methods in pose-challenging cases. The project is publicly available on `https://github.com/andrewyu90/Alphaface_Official.git'.
Deep Spectral Prior
May 26, 2025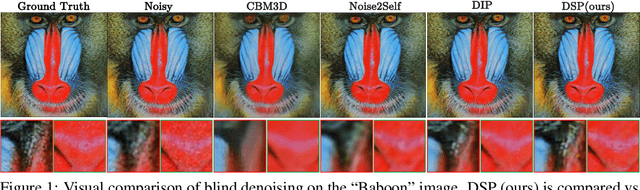
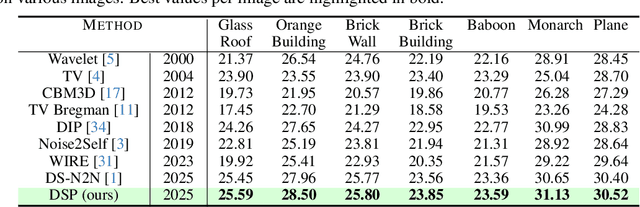


We introduce Deep Spectral Prior (DSP), a new formulation of Deep Image Prior (DIP) that redefines image reconstruction as a frequency-domain alignment problem. Unlike traditional DIP, which relies on pixel-wise loss and early stopping to mitigate overfitting, DSP directly matches Fourier coefficients between the network output and observed measurements. This shift introduces an explicit inductive bias towards spectral coherence, aligning with the known frequency structure of images and the spectral bias of convolutional neural networks. We provide a rigorous theoretical framework demonstrating that DSP acts as an implicit spectral regulariser, suppressing high-frequency noise by design and eliminating the need for early stopping. Our analysis spans four core dimensions establishing smooth convergence dynamics, local stability, and favourable bias-variance tradeoffs. We further show that DSP naturally projects reconstructions onto a frequency-consistent manifold, enhancing interpretability and robustness. These theoretical guarantees are supported by empirical results across denoising, inpainting, and super-resolution tasks, where DSP consistently outperforms classical DIP and other unsupervised baselines.
D2SA: Dual-Stage Distribution and Slice Adaptation for Efficient Test-Time Adaptation in MRI Reconstruction
Mar 25, 2025Variations in Magnetic resonance imaging (MRI) scanners and acquisition protocols cause distribution shifts that degrade reconstruction performance on unseen data. Test-time adaptation (TTA) offers a promising solution to address this discrepancies. However, previous single-shot TTA approaches are inefficient due to repeated training and suboptimal distributional models. Self-supervised learning methods are also limited by scarce date scenarios. To address these challenges, we propose a novel Dual-Stage Distribution and Slice Adaptation (D2SA) via MRI implicit neural representation (MR-INR) to improve MRI reconstruction performance and efficiency, which features two stages. In the first stage, an MR-INR branch performs patient-wise distribution adaptation by learning shared representations across slices and modelling patient-specific shifts with mean and variance adjustments. In the second stage, single-slice adaptation refines the output from frozen convolutional layers with a learnable anisotropic diffusion module, preventing over-smoothing and reducing computation. Experiments across four MRI distribution shifts demonstrate that our method can integrate well with various self-supervised learning (SSL) framework, improving performance and accelerating convergence under diverse conditions.
Implicit U-KAN2.0: Dynamic, Efficient and Interpretable Medical Image Segmentation
Mar 05, 2025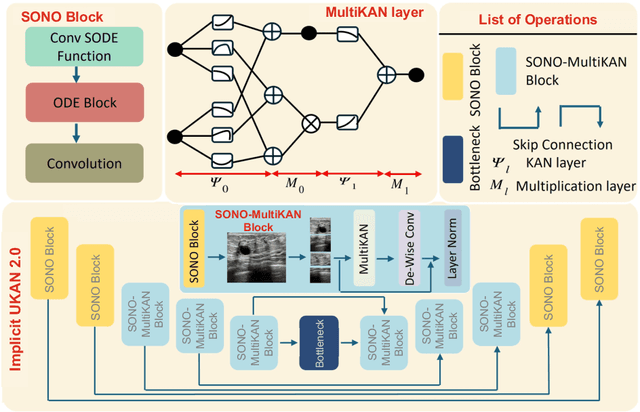
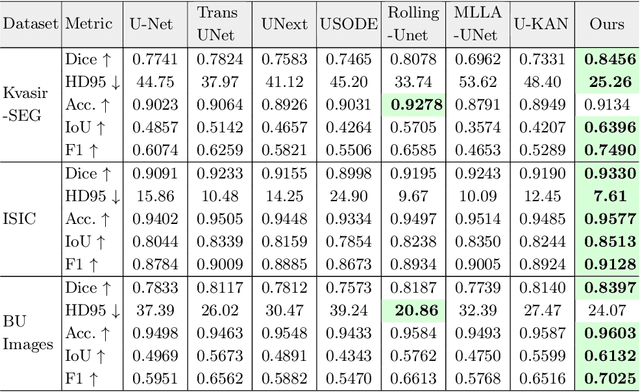
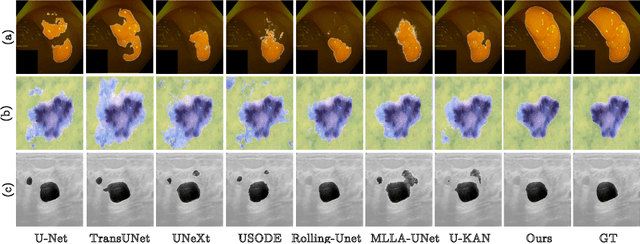

Image segmentation is a fundamental task in both image analysis and medical applications. State-of-the-art methods predominantly rely on encoder-decoder architectures with a U-shaped design, commonly referred to as U-Net. Recent advancements integrating transformers and MLPs improve performance but still face key limitations, such as poor interpretability, difficulty handling intrinsic noise, and constrained expressiveness due to discrete layer structures, often lacking a solid theoretical foundation.In this work, we introduce Implicit U-KAN 2.0, a novel U-Net variant that adopts a two-phase encoder-decoder structure. In the SONO phase, we use a second-order neural ordinary differential equation (NODEs), called the SONO block, for a more efficient, expressive, and theoretically grounded modeling approach. In the SONO-MultiKAN phase, we integrate the second-order NODEs and MultiKAN layer as the core computational block to enhance interpretability and representation power. Our contributions are threefold. First, U-KAN 2.0 is an implicit deep neural network incorporating MultiKAN and second order NODEs, improving interpretability and performance while reducing computational costs. Second, we provide a theoretical analysis demonstrating that the approximation ability of the MultiKAN block is independent of the input dimension. Third, we conduct extensive experiments on a variety of 2D and a single 3D dataset, demonstrating that our model consistently outperforms existing segmentation networks.
Cross-Modal Few-Shot Learning with Second-Order Neural Ordinary Differential Equations
Dec 20, 2024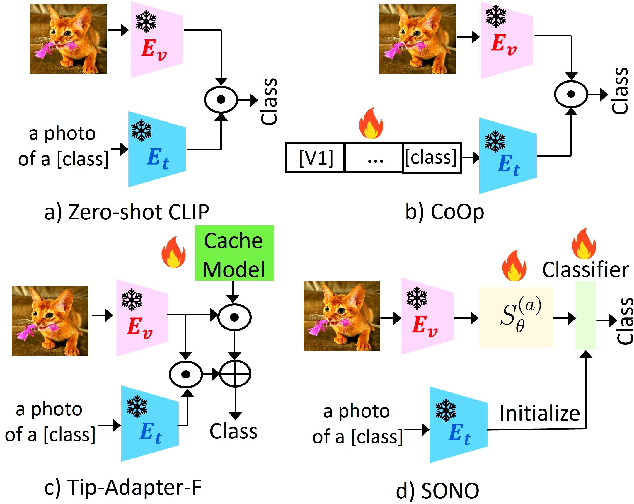
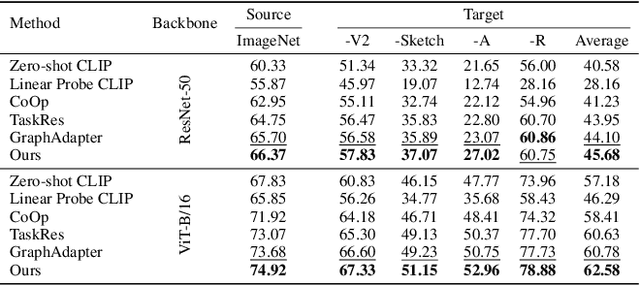
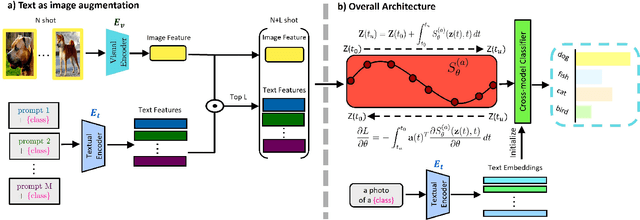
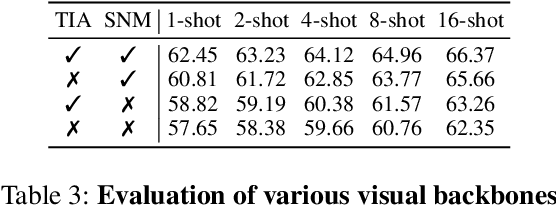
We introduce SONO, a novel method leveraging Second-Order Neural Ordinary Differential Equations (Second-Order NODEs) to enhance cross-modal few-shot learning. By employing a simple yet effective architecture consisting of a Second-Order NODEs model paired with a cross-modal classifier, SONO addresses the significant challenge of overfitting, which is common in few-shot scenarios due to limited training examples. Our second-order approach can approximate a broader class of functions, enhancing the model's expressive power and feature generalization capabilities. We initialize our cross-modal classifier with text embeddings derived from class-relevant prompts, streamlining training efficiency by avoiding the need for frequent text encoder processing. Additionally, we utilize text-based image augmentation, exploiting CLIP's robust image-text correlation to enrich training data significantly. Extensive experiments across multiple datasets demonstrate that SONO outperforms existing state-of-the-art methods in few-shot learning performance.
You KAN Do It in a Single Shot: Plug-and-Play Methods with Single-Instance Priors
Dec 09, 2024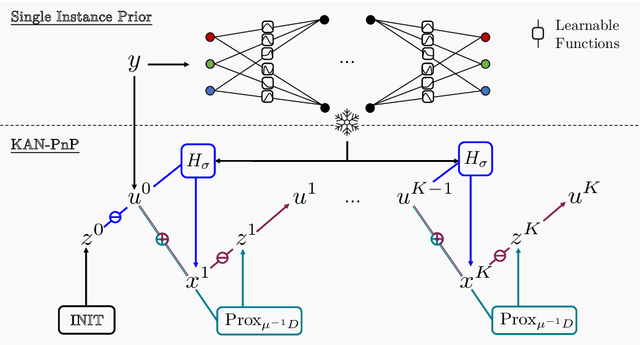
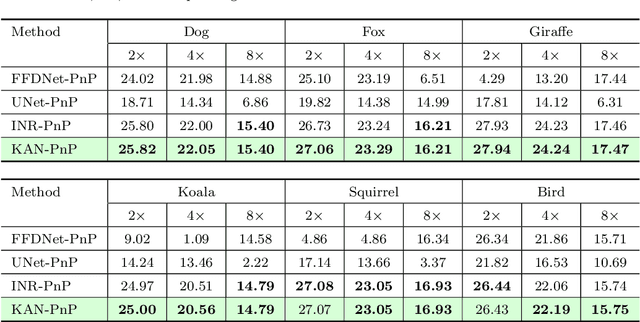

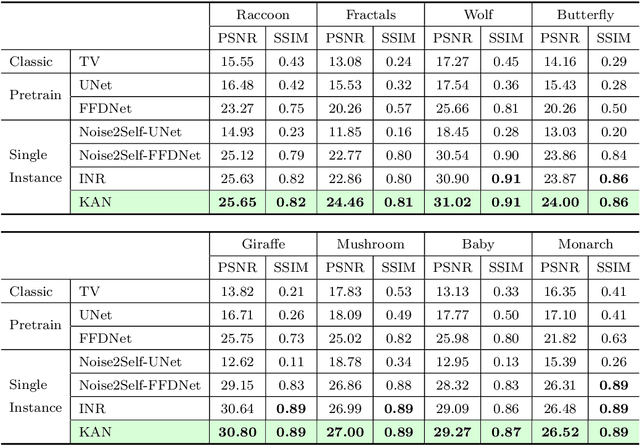
The use of Plug-and-Play (PnP) methods has become a central approach for solving inverse problems, with denoisers serving as regularising priors that guide optimisation towards a clean solution. In this work, we introduce KAN-PnP, an optimisation framework that incorporates Kolmogorov-Arnold Networks (KANs) as denoisers within the Plug-and-Play (PnP) paradigm. KAN-PnP is specifically designed to solve inverse problems with single-instance priors, where only a single noisy observation is available, eliminating the need for large datasets typically required by traditional denoising methods. We show that KANs, based on the Kolmogorov-Arnold representation theorem, serve effectively as priors in such settings, providing a robust approach to denoising. We prove that the KAN denoiser is Lipschitz continuous, ensuring stability and convergence in optimisation algorithms like PnP-ADMM, even in the context of single-shot learning. Additionally, we provide theoretical guarantees for KAN-PnP, demonstrating its convergence under key conditions: the convexity of the data fidelity term, Lipschitz continuity of the denoiser, and boundedness of the regularisation functional. These conditions are crucial for stable and reliable optimisation. Our experimental results show, on super-resolution and joint optimisation, that KAN-PnP outperforms exiting methods, delivering superior performance in single-shot learning with minimal data. The method exhibits strong convergence properties, achieving high accuracy with fewer iterations.
Where Do We Stand with Implicit Neural Representations? A Technical and Performance Survey
Nov 06, 2024



Implicit Neural Representations (INRs) have emerged as a paradigm in knowledge representation, offering exceptional flexibility and performance across a diverse range of applications. INRs leverage multilayer perceptrons (MLPs) to model data as continuous implicit functions, providing critical advantages such as resolution independence, memory efficiency, and generalisation beyond discretised data structures. Their ability to solve complex inverse problems makes them particularly effective for tasks including audio reconstruction, image representation, 3D object reconstruction, and high-dimensional data synthesis. This survey provides a comprehensive review of state-of-the-art INR methods, introducing a clear taxonomy that categorises them into four key areas: activation functions, position encoding, combined strategies, and network structure optimisation. We rigorously analyse their critical properties, such as full differentiability, smoothness, compactness, and adaptability to varying resolutions while also examining their strengths and limitations in addressing locality biases and capturing fine details. Our experimental comparison offers new insights into the trade-offs between different approaches, showcasing the capabilities and challenges of the latest INR techniques across various tasks. In addition to identifying areas where current methods excel, we highlight key limitations and potential avenues for improvement, such as developing more expressive activation functions, enhancing positional encoding mechanisms, and improving scalability for complex, high-dimensional data. This survey serves as a roadmap for researchers, offering practical guidance for future exploration in the field of INRs. We aim to foster new methodologies by outlining promising research directions for INRs and applications.
Semi-Supervised Video Desnowing Network via Temporal Decoupling Experts and Distribution-Driven Contrastive Regularization
Oct 10, 2024



Snow degradations present formidable challenges to the advancement of computer vision tasks by the undesirable corruption in outdoor scenarios. While current deep learning-based desnowing approaches achieve success on synthetic benchmark datasets, they struggle to restore out-of-distribution real-world snowy videos due to the deficiency of paired real-world training data. To address this bottleneck, we devise a new paradigm for video desnowing in a semi-supervised spirit to involve unlabeled real data for the generalizable snow removal. Specifically, we construct a real-world dataset with 85 snowy videos, and then present a Semi-supervised Video Desnowing Network (SemiVDN) equipped by a novel Distribution-driven Contrastive Regularization. The elaborated contrastive regularization mitigates the distribution gap between the synthetic and real data, and consequently maintains the desired snow-invariant background details. Furthermore, based on the atmospheric scattering model, we introduce a Prior-guided Temporal Decoupling Experts module to decompose the physical components that make up a snowy video in a frame-correlated manner. We evaluate our SemiVDN on benchmark datasets and the collected real snowy data. The experimental results demonstrate the superiority of our approach against state-of-the-art image- and video-level desnowing methods.
Mamba Neural Operator: Who Wins? Transformers vs. State-Space Models for PDEs
Oct 03, 2024



Partial differential equations (PDEs) are widely used to model complex physical systems, but solving them efficiently remains a significant challenge. Recently, Transformers have emerged as the preferred architecture for PDEs due to their ability to capture intricate dependencies. However, they struggle with representing continuous dynamics and long-range interactions. To overcome these limitations, we introduce the Mamba Neural Operator (MNO), a novel framework that enhances neural operator-based techniques for solving PDEs. MNO establishes a formal theoretical connection between structured state-space models (SSMs) and neural operators, offering a unified structure that can adapt to diverse architectures, including Transformer-based models. By leveraging the structured design of SSMs, MNO captures long-range dependencies and continuous dynamics more effectively than traditional Transformers. Through extensive analysis, we show that MNO significantly boosts the expressive power and accuracy of neural operators, making it not just a complement but a superior framework for PDE-related tasks, bridging the gap between efficient representation and accurate solution approximation.
Learning Task-Specific Sampling Strategy for Sparse-View CT Reconstruction
Sep 03, 2024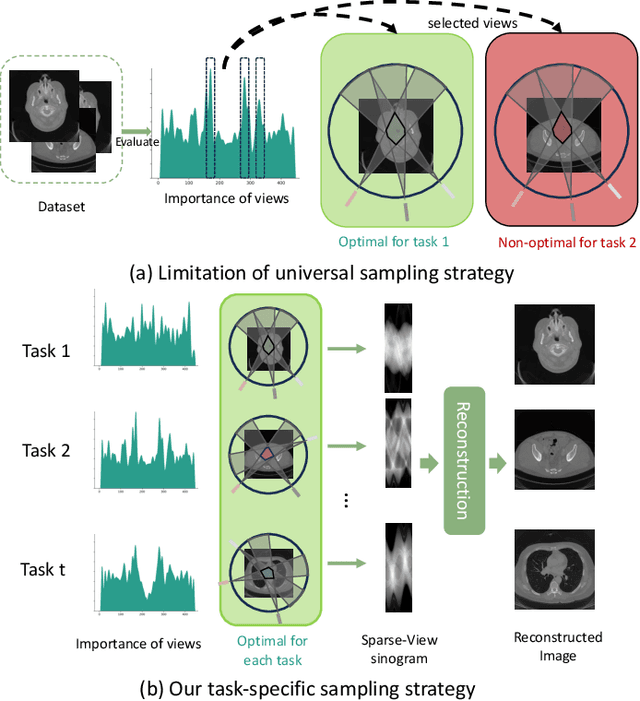
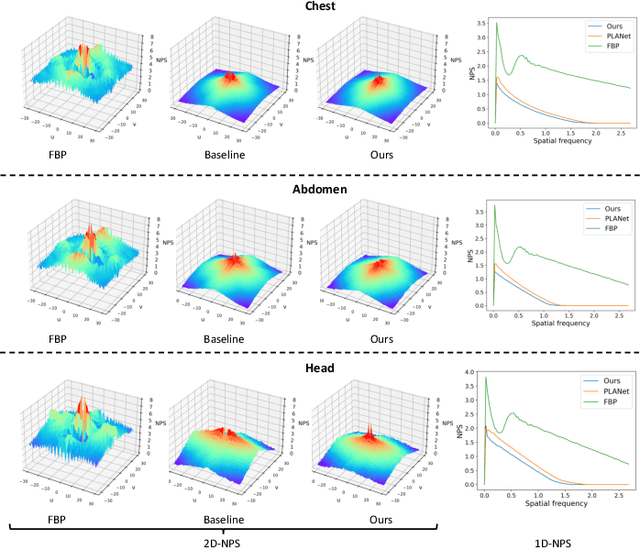

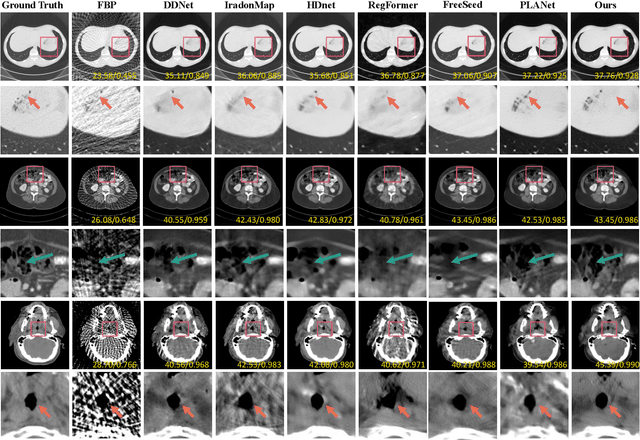
Sparse-View Computed Tomography (SVCT) offers low-dose and fast imaging but suffers from severe artifacts. Optimizing the sampling strategy is an essential approach to improving the imaging quality of SVCT. However, current methods typically optimize a universal sampling strategy for all types of scans, overlooking the fact that the optimal strategy may vary depending on the specific scanning task, whether it involves particular body scans (e.g., chest CT scans) or downstream clinical applications (e.g., disease diagnosis). The optimal strategy for one scanning task may not perform as well when applied to other tasks. To address this problem, we propose a deep learning framework that learns task-specific sampling strategies with a multi-task approach to train a unified reconstruction network while tailoring optimal sampling strategies for each individual task. Thus, a task-specific sampling strategy can be applied for each type of scans to improve the quality of SVCT imaging and further assist in performance of downstream clinical usage. Extensive experiments across different scanning types provide validation for the effectiveness of task-specific sampling strategies in enhancing imaging quality. Experiments involving downstream tasks verify the clinical value of learned sampling strategies, as evidenced by notable improvements in downstream task performance. Furthermore, the utilization of a multi-task framework with a shared reconstruction network facilitates deployment on current imaging devices with switchable task-specific modules, and allows for easily integrate new tasks without retraining the entire model.