 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerbalValue: A Socially Intelligent Virtual Host for Sales-Driven Live Commerce
May 14, 2026A skilled live-commerce host is not merely a narrator, but a sales agent who converts viewer curiosity into purchase intent through expert product knowledge, emotionally intelligent response tactics, and entertainment that serves as a vehicle for product exposure. Yet no existing AI system replicates this: conversational recommenders treat recommendation as a terminal act, while general-purpose LLMs hallucinate product claims and default to generic promotional templates that fail to engage or persuade. We present VerbalValue, a sales-conversion-oriented virtual host that turns exceptional verbal ability into real commercial value, built on three contributions. First, we construct a domain knowledge base of product specifications and a curated sales terminology lexicon that anchor product-related responses in verified expertise. Second, we collect and annotate 1,475 live-commerce interactions spanning diverse viewer intents. Third, we fine-tune a large language model on this data to deliver empathetic, commercially oriented responses, adapting to viewer intent through empathetic amplification, evidence-backed rebuttal, and humor-mediated deflection. Experiments against GPT-5.4, Claude Sonnet 4.6, Gemini 3.1 Pro, and other baselines demonstrate gains of 23% on informativeness and 18% on factual correctness, with consistent advantages in tactfulness and viewer engagement.
Enhancing Multimodal In-Context Learning via Inductive-Deductive Reasoning
May 04, 2026In-context learning (ICL) allows large models to adapt to tasks using a few examples, yet its extension to vision-language models (VLMs) remains fragile. Our analysis reveals that the fundamental limitation lies in an inductive gap, models often produce correct answers from flawed reasoning, while struggling to extract consistent rules across demonstrations. This gap is further exacerbated by two visual-level obstacles: an overwhelming proportion of redundant visual tokens that obscure textual cues, and a skewed attention distribution that favors the initial image at the expense of subsequent context. To address these issues, we introduce a framework that restructures multimodal ICL as a principled inductive-deductive process. The framework incorporates a similarity-based visual token compression module to filter out redundant patches, a dynamic attention rebalancing mechanism to distribute focus equitably across all images, and a chain-of-thought paradigm that explicitly guides the model to analyze individual examples, derive a generalizable rule, and then apply it to the query. An auxiliary learning pipeline combines supervised fine-tuning with reinforcement learning using verifiable rewards to reinforce faithful citation and noise filtering. Evaluations across eight benchmarks covering visual perception, logical reasoning, STEM problems, and sarcasm detection demonstrate consistent and significant improvements over standard ICL baselines for multiple open-source VLMs, highlighting the potential of equipping models with genuine inductive capabilities in multimodal settings.
Tracking Phenological Status and Ecological Interactions in a Hawaiian Cloud Forest Understory using Low-Cost Camera Traps and Visual Foundation Models
Mar 08, 2026Plant phenology, the study of cyclical events such as leafing out, flowering, or fruiting, has wide ecological impacts but is broadly understudied, especially in the tropics. Image analysis has greatly enhanced remote phenological monitoring, yet capturing phenology at the individual level remains challenging. In this project, we deployed low-cost, animal-triggered camera traps at the Pu'u Maka'ala Natural Area Reserve in Hawaii to simultaneously document shifts in plant phenology and flora-faunal interactions. Using a combination of foundation vision models and traditional computer vision methods, we measure phenological trends from images comparable to on-the-ground observations without relying on supervised learning techniques. These temporally fine-grained phenology measurements from camera-trap images uncover trends that coarser traditional sampling fails to detect. When combined with detailed visitation data detected from images, these trends can begin to elucidate drivers of both plant phenology and animal ecology.
Why Did Apple Fall To The Ground: Evaluating Curiosity In Large Language Model
Oct 23, 2025Curiosity serves as a pivotal conduit for human beings to discover and learn new knowledge. Recent advancements of large language models (LLMs) in natural language processing have sparked discussions regarding whether these models possess capability of curiosity-driven learning akin to humans. In this paper, starting from the human curiosity assessment questionnaire Five-Dimensional Curiosity scale Revised (5DCR), we design a comprehensive evaluation framework that covers dimensions such as Information Seeking, Thrill Seeking, and Social Curiosity to assess the extent of curiosity exhibited by LLMs. The results demonstrate that LLMs exhibit a stronger thirst for knowledge than humans but still tend to make conservative choices when faced with uncertain environments. We further investigated the relationship between curiosity and thinking of LLMs, confirming that curious behaviors can enhance the model's reasoning and active learning abilities. These findings suggest that LLMs have the potential to exhibit curiosity similar to that of humans, providing experimental support for the future development of learning capabilities and innovative research in LLMs.
Open-Set Recognition of Novel Species in Biodiversity Monitoring
Mar 03, 2025Machine learning is increasingly being applied to facilitate long-term, large-scale biodiversity monitoring. With most species on Earth still undiscovered or poorly documented, species-recognition models are expected to encounter new species during deployment. We introduce Open-Insects, a fine-grained image recognition benchmark dataset for open-set recognition and out-of-distribution detection in biodiversity monitoring. Open-Insects makes it possible to evaluate algorithms for new species detection on several geographical open-set splits with varying difficulty. Furthermore, we present a test set recently collected in the wild with 59 species that are likely new to science. We evaluate a variety of open-set recognition algorithms, including post-hoc methods, training-time regularization, and training with auxiliary data, finding that the simple post-hoc approach of utilizing softmax scores remains a strong baseline. We also demonstrate how to leverage auxiliary data to improve the detection performance when the training dataset is limited. Our results provide timely insights to guide the development of computer vision methods for biodiversity monitoring and species discovery.
Cross-Modal Few-Shot Learning with Second-Order Neural Ordinary Differential Equations
Dec 20, 2024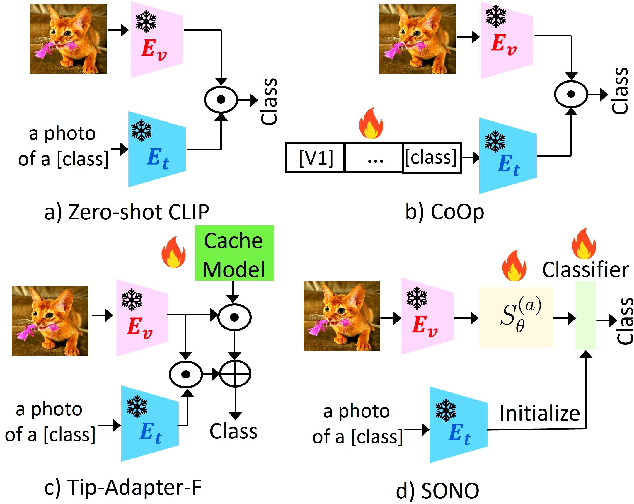
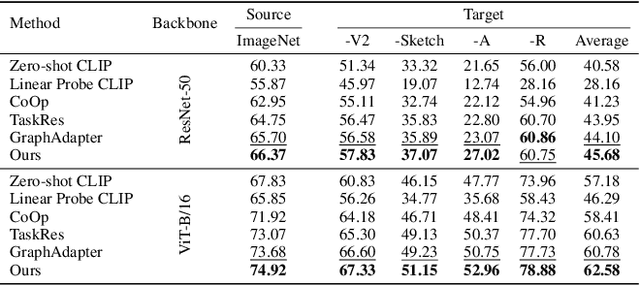
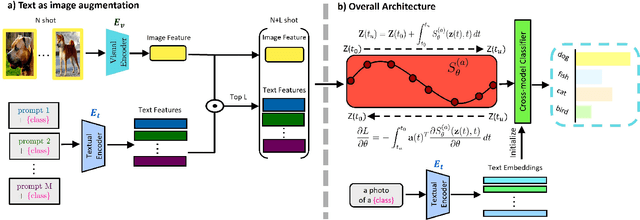
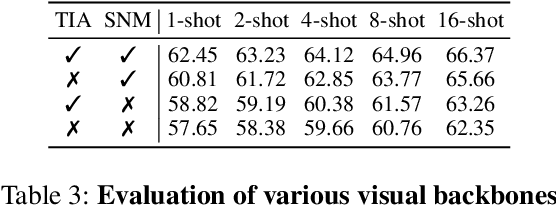
We introduce SONO, a novel method leveraging Second-Order Neural Ordinary Differential Equations (Second-Order NODEs) to enhance cross-modal few-shot learning. By employing a simple yet effective architecture consisting of a Second-Order NODEs model paired with a cross-modal classifier, SONO addresses the significant challenge of overfitting, which is common in few-shot scenarios due to limited training examples. Our second-order approach can approximate a broader class of functions, enhancing the model's expressive power and feature generalization capabilities. We initialize our cross-modal classifier with text embeddings derived from class-relevant prompts, streamlining training efficiency by avoiding the need for frequent text encoder processing. Additionally, we utilize text-based image augmentation, exploiting CLIP's robust image-text correlation to enrich training data significantly. Extensive experiments across multiple datasets demonstrate that SONO outperforms existing state-of-the-art methods in few-shot learning performance.
Dr.Academy: A Benchmark for Evaluating Questioning Capability in Education for Large Language Models
Aug 20, 2024



Teachers are important to imparting knowledge and guiding learners, and the role of large language models (LLMs) as potential educators is emerging as an important area of study. Recognizing LLMs' capability to generate educational content can lead to advances in automated and personalized learning. While LLMs have been tested for their comprehension and problem-solving skills, their capability in teaching remains largely unexplored. In teaching, questioning is a key skill that guides students to analyze, evaluate, and synthesize core concepts and principles. Therefore, our research introduces a benchmark to evaluate the questioning capability in education as a teacher of LLMs through evaluating their generated educational questions, utilizing Anderson and Krathwohl's taxonomy across general, monodisciplinary, and interdisciplinary domains. We shift the focus from LLMs as learners to LLMs as educators, assessing their teaching capability through guiding them to generate questions. We apply four metrics, including relevance, coverage, representativeness, and consistency, to evaluate the educational quality of LLMs' outputs. Our results indicate that GPT-4 demonstrates significant potential in teaching general, humanities, and science courses; Claude2 appears more apt as an interdisciplinary teacher. Furthermore, the automatic scores align with human perspectives.
XMeCap: Meme Caption Generation with Sub-Image Adaptability
Jul 24, 2024



Humor, deeply rooted in societal meanings and cultural details, poses a unique challenge for machines. While advances have been made in natural language processing, real-world humor often thrives in a multi-modal context, encapsulated distinctively by memes. This paper poses a particular emphasis on the impact of multi-images on meme captioning. After that, we introduce the \textsc{XMeCap} framework, a novel approach that adopts supervised fine-tuning and reinforcement learning based on an innovative reward model, which factors in both global and local similarities between visuals and text. Our results, benchmarked against contemporary models, manifest a marked improvement in caption generation for both single-image and multi-image memes, as well as different meme categories. \textsc{XMeCap} achieves an average evaluation score of 75.85 for single-image memes and 66.32 for multi-image memes, outperforming the best baseline by 3.71\% and 4.82\%, respectively. This research not only establishes a new frontier in meme-related studies but also underscores the potential of machines in understanding and generating humor in a multi-modal setting.
MAPO: Boosting Large Language Model Performance with Model-Adaptive Prompt Optimization
Jul 04, 2024



Prompt engineering, as an efficient and effective way to leverage Large Language Models (LLM), has drawn a lot of attention from the research community. The existing research primarily emphasizes the importance of adapting prompts to specific tasks, rather than specific LLMs. However, a good prompt is not solely defined by its wording, but also binds to the nature of the LLM in question. In this work, we first quantitatively demonstrate that different prompts should be adapted to different LLMs to enhance their capabilities across various downstream tasks in NLP. Then we novelly propose a model-adaptive prompt optimizer (MAPO) method that optimizes the original prompts for each specific LLM in downstream tasks. Extensive experiments indicate that the proposed method can effectively refine prompts for an LLM, leading to significant improvements over various downstream tasks.
Can Pre-trained Language Models Understand Chinese Humor?
Jul 04, 2024



Humor understanding is an important and challenging research in natural language processing. As the popularity of pre-trained language models (PLMs), some recent work makes preliminary attempts to adopt PLMs for humor recognition and generation. However, these simple attempts do not substantially answer the question: {\em whether PLMs are capable of humor understanding?} This paper is the first work that systematically investigates the humor understanding ability of PLMs. For this purpose, a comprehensive framework with three evaluation steps and four evaluation tasks is designed. We also construct a comprehensive Chinese humor dataset, which can fully meet all the data requirements of the proposed evaluation framework. Our empirical study on the Chinese humor dataset yields some valuable observations, which are of great guiding value for future optimization of PLMs in humor understanding and generation.