 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Pre-trained Language Models Understand Chinese Humor?
Jul 04, 2024



Humor understanding is an important and challenging research in natural language processing. As the popularity of pre-trained language models (PLMs), some recent work makes preliminary attempts to adopt PLMs for humor recognition and generation. However, these simple attempts do not substantially answer the question: {\em whether PLMs are capable of humor understanding?} This paper is the first work that systematically investigates the humor understanding ability of PLMs. For this purpose, a comprehensive framework with three evaluation steps and four evaluation tasks is designed. We also construct a comprehensive Chinese humor dataset, which can fully meet all the data requirements of the proposed evaluation framework. Our empirical study on the Chinese humor dataset yields some valuable observations, which are of great guiding value for future optimization of PLMs in humor understanding and generation.
Enhancing Quantitative Reasoning Skills of Large Language Models through Dimension Perception
Dec 29, 2023Quantities are distinct and critical components of texts that characterize the magnitude properties of entities, providing a precise perspective for the understanding of natural language, especially for reasoning tasks. In recent years, there has been a flurry of research on reasoning tasks based on large language models (LLMs), most of which solely focus on numerical values, neglecting the dimensional concept of quantities with units despite its importance. We argue that the concept of dimension is essential for precisely understanding quantities and of great significance for LLMs to perform quantitative reasoning. However, the lack of dimension knowledge and quantity-related benchmarks has resulted in low performance of LLMs. Hence, we present a framework to enhance the quantitative reasoning ability of language models based on dimension perception. We first construct a dimensional unit knowledge base (DimUnitKB) to address the knowledge gap in this area. We propose a benchmark DimEval consisting of seven tasks of three categories to probe and enhance the dimension perception skills of LLMs. To evaluate the effectiveness of our methods, we propose a quantitative reasoning task and conduct experiments. The experimental results show that our dimension perception method dramatically improves accuracy (43.55%->50.67%) on quantitative reasoning tasks compared to GPT-4.
HAUSER: Towards Holistic and Automatic Evaluation of Simile Generation
Jun 13, 2023



Similes play an imperative role in creative writing such as story and dialogue generation. Proper evaluation metrics are like a beacon guiding the research of simile generation (SG). However, it remains under-explored as to what criteria should be considered, how to quantify each criterion into metrics, and whether the metrics are effective for comprehensive, efficient, and reliable SG evaluation. To address the issues, we establish HAUSER, a holistic and automatic evaluation system for the SG task, which consists of five criteria from three perspectives and automatic metrics for each criterion. Through extensive experiments, we verify that our metrics are significantly more correlated with human ratings from each perspective compared with prior automatic metrics.
Open Set Relation Extraction via Unknown-Aware Training
Jun 08, 2023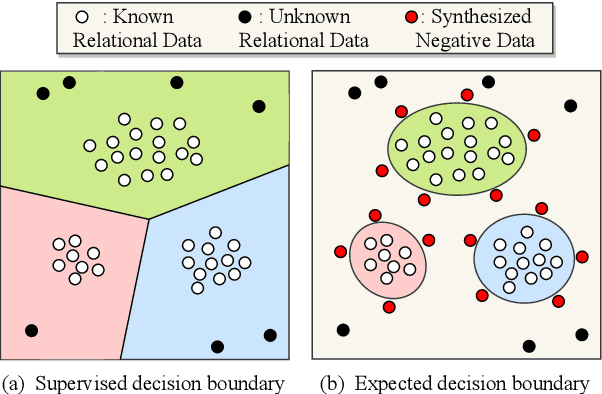
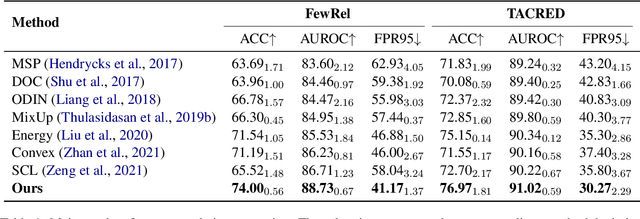
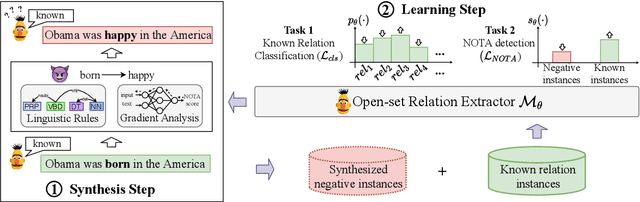
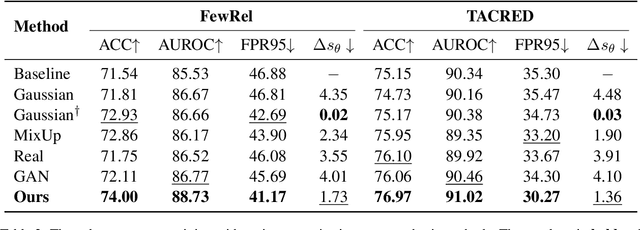
The existing supervised relation extraction methods have achieved impressive performance in a closed-set setting, where the relations during both training and testing remain the same. In a more realistic open-set setting, unknown relations may appear in the test set. Due to the lack of supervision signals from unknown relations, a well-performing closed-set relation extractor can still confidently misclassify them into known relations. In this paper, we propose an unknown-aware training method, regularizing the model by dynamically synthesizing negative instances. To facilitate a compact decision boundary, ``difficult'' negative instances are necessary. Inspired by text adversarial attacks, we adaptively apply small but critical perturbations to original training instances and thus synthesizing negative instances that are more likely to be mistaken by the model as known relations. Experimental results show that this method achieves SOTA unknown relation detection without compromising the classification of known relations.
Farewell to Aimless Large-scale Pretraining: Influential Subset Selection for Language Model
May 22, 2023



Pretrained language models have achieved remarkable success in various natural language processing tasks. However, pretraining has recently shifted toward larger models and larger data, and this has resulted in significant computational and energy costs. In this paper, we propose Influence Subset Selection (ISS) for language model, which explicitly utilizes end-task knowledge to select a tiny subset of the pretraining corpus. Specifically, the ISS selects the samples that will provide the most positive influence on the performance of the end-task. Furthermore, we design a gradient matching based influence estimation method, which can drastically reduce the computation time of influence. With only 0.45% of the data and a three-orders-of-magnitude lower computational cost, ISS outperformed pretrained models (e.g., RoBERTa) on eight datasets covering four domains.
Context-aware Ensemble of Multifaceted Factorization Models for Recommendation Prediction in Social Networks
May 03, 2021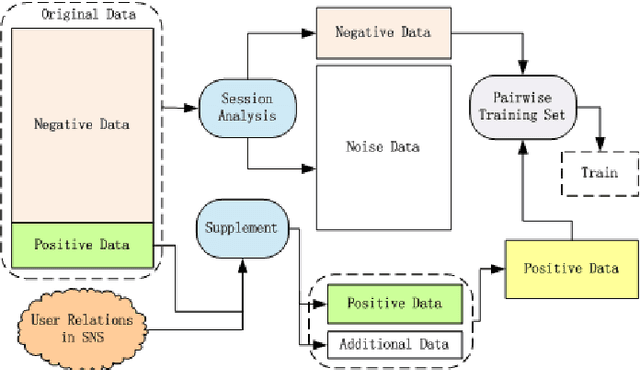
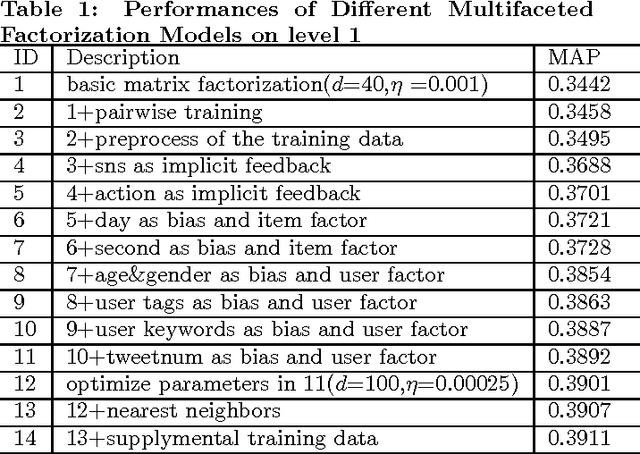
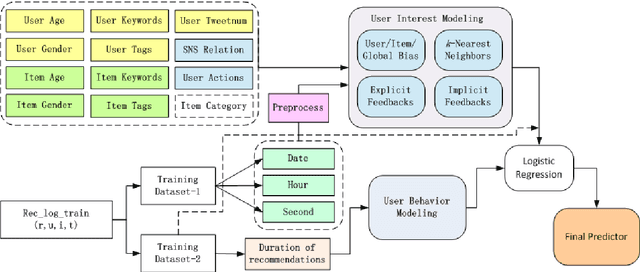

This paper describes the solution of Shanda Innovations team to Task 1 of KDD-Cup 2012. A novel approach called Multifaceted Factorization Models is proposed to incorporate a great variety of features in social networks. Social relationships and actions between users are integrated as implicit feedbacks to improve the recommendation accuracy. Keywords, tags, profiles, time and some other features are also utilized for modeling user interests. In addition, user behaviors are modeled from the durations of recommendation records. A context-aware ensemble framework is then applied to combine multiple predictors and produce final recommendation results. The proposed approach obtained 0.43959 (public score) / 0.41874 (private score) on the testing dataset, which achieved the 2nd place in the KDD-Cup competition.