 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCL-bench: A Benchmark for Context Learning
Feb 03, 2026Current language models (LMs) excel at reasoning over prompts using pre-trained knowledge. However, real-world tasks are far more complex and context-dependent: models must learn from task-specific context and leverage new knowledge beyond what is learned during pre-training to reason and resolve tasks. We term this capability context learning, a crucial ability that humans naturally possess but has been largely overlooked. To this end, we introduce CL-bench, a real-world benchmark consisting of 500 complex contexts, 1,899 tasks, and 31,607 verification rubrics, all crafted by experienced domain experts. Each task is designed such that the new content required to resolve it is contained within the corresponding context. Resolving tasks in CL-bench requires models to learn from the context, ranging from new domain-specific knowledge, rule systems, and complex procedures to laws derived from empirical data, all of which are absent from pre-training. This goes far beyond long-context tasks that primarily test retrieval or reading comprehension, and in-context learning tasks, where models learn simple task patterns via instructions and demonstrations. Our evaluations of ten frontier LMs find that models solve only 17.2% of tasks on average. Even the best-performing model, GPT-5.1, solves only 23.7%, revealing that LMs have yet to achieve effective context learning, which poses a critical bottleneck for tackling real-world, complex context-dependent tasks. CL-bench represents a step towards building LMs with this fundamental capability, making them more intelligent and advancing their deployment in real-world scenarios.
CARE-Bench: A Benchmark of Diverse Client Simulations Guided by Expert Principles for Evaluating LLMs in Psychological Counseling
Nov 12, 2025The mismatch between the growing demand for psychological counseling and the limited availability of services has motivated research into the application of Large Language Models (LLMs) in this domain. Consequently, there is a need for a robust and unified benchmark to assess the counseling competence of various LLMs. Existing works, however, are limited by unprofessional client simulation, static question-and-answer evaluation formats, and unidimensional metrics. These limitations hinder their effectiveness in assessing a model's comprehensive ability to handle diverse and complex clients. To address this gap, we introduce \textbf{CARE-Bench}, a dynamic and interactive automated benchmark. It is built upon diverse client profiles derived from real-world counseling cases and simulated according to expert guidelines. CARE-Bench provides a multidimensional performance evaluation grounded in established psychological scales. Using CARE-Bench, we evaluate several general-purpose LLMs and specialized counseling models, revealing their current limitations. In collaboration with psychologists, we conduct a detailed analysis of the reasons for LLMs' failures when interacting with clients of different types, which provides directions for developing more comprehensive, universal, and effective counseling models.
Learn More, Forget Less: A Gradient-Aware Data Selection Approach for LLM
Nov 07, 2025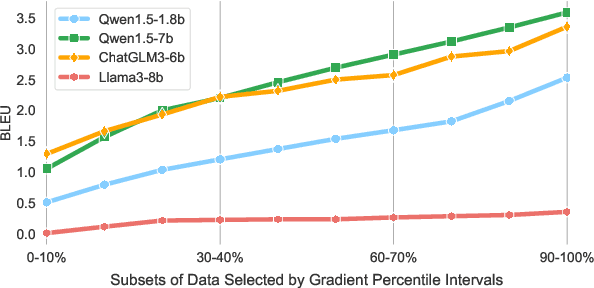
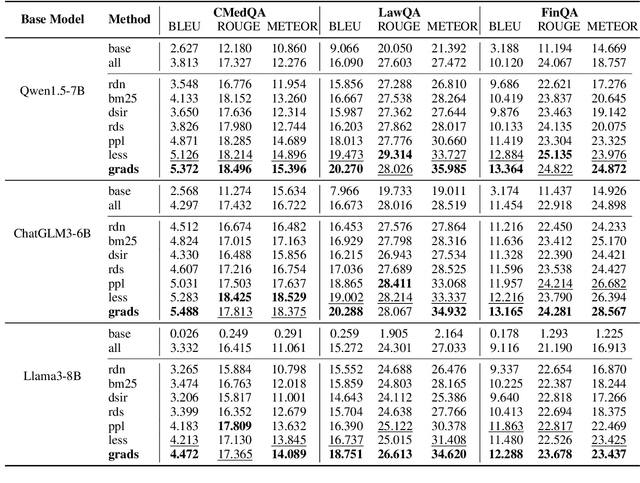
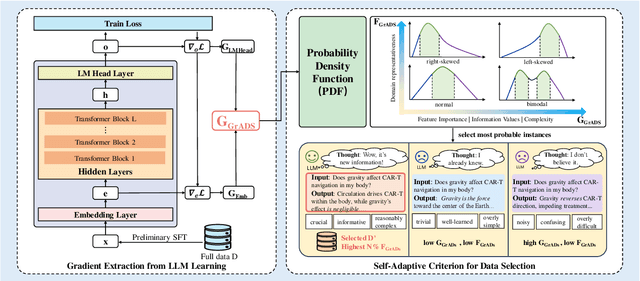
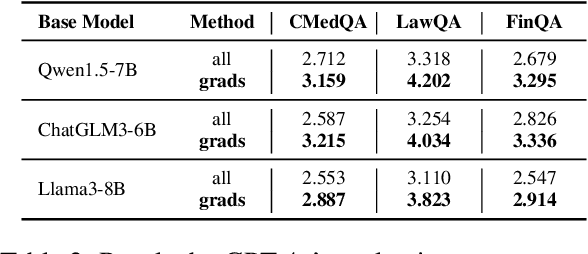
Despite large language models (LLMs) have achieved impressive achievements across numerous tasks, supervised fine-tuning (SFT) remains essential for adapting these models to specialized domains. However, SFT for domain specialization can be resource-intensive and sometimes leads to a deterioration in performance over general capabilities due to catastrophic forgetting (CF). To address these issues, we propose a self-adaptive gradient-aware data selection approach (GrADS) for supervised fine-tuning of LLMs, which identifies effective subsets of training data by analyzing gradients obtained from a preliminary training phase. Specifically, we design self-guided criteria that leverage the magnitude and statistical distribution of gradients to prioritize examples that contribute the most to the model's learning process. This approach enables the acquisition of representative samples that enhance LLMs understanding of domain-specific tasks. Through extensive experimentation with various LLMs across diverse domains such as medicine, law, and finance, GrADS has demonstrated significant efficiency and cost-effectiveness. Remarkably, utilizing merely 5% of the selected GrADS data, LLMs already surpass the performance of those fine-tuned on the entire dataset, and increasing to 50% of the data results in significant improvements! With catastrophic forgetting substantially mitigated simultaneously. We will release our code for GrADS later.
LLMEval-3: A Large-Scale Longitudinal Study on Robust and Fair Evaluation of Large Language Models
Aug 07, 2025Existing evaluation of Large Language Models (LLMs) on static benchmarks is vulnerable to data contamination and leaderboard overfitting, critical issues that obscure true model capabilities. To address this, we introduce LLMEval-3, a framework for dynamic evaluation of LLMs. LLMEval-3 is built on a proprietary bank of 220k graduate-level questions, from which it dynamically samples unseen test sets for each evaluation run. Its automated pipeline ensures integrity via contamination-resistant data curation, a novel anti-cheating architecture, and a calibrated LLM-as-a-judge process achieving 90% agreement with human experts, complemented by a relative ranking system for fair comparison. An 20-month longitudinal study of nearly 50 leading models reveals a performance ceiling on knowledge memorization and exposes data contamination vulnerabilities undetectable by static benchmarks. The framework demonstrates exceptional robustness in ranking stability and consistency, providing strong empirical validation for the dynamic evaluation paradigm. LLMEval-3 offers a robust and credible methodology for assessing the true capabilities of LLMs beyond leaderboard scores, promoting the development of more trustworthy evaluation standards.
Psychological Counseling Cannot Be Achieved Overnight: Automated Psychological Counseling Through Multi-Session Conversations
Jun 07, 2025In recent years, Large Language Models (LLMs) have made significant progress in automated psychological counseling. However, current research focuses on single-session counseling, which doesn't represent real-world scenarios. In practice, psychological counseling is a process, not a one-time event, requiring sustained, multi-session engagement to progressively address clients' issues. To overcome this limitation, we introduce a dataset for Multi-Session Psychological Counseling Conversation Dataset (MusPsy-Dataset). Our MusPsy-Dataset is constructed using real client profiles from publicly available psychological case reports. It captures the dynamic arc of counseling, encompassing multiple progressive counseling conversations from the same client across different sessions. Leveraging our dataset, we also developed our MusPsy-Model, which aims to track client progress and adapt its counseling direction over time. Experiments show that our model performs better than baseline models across multiple sessions.
Active Contact Engagement for Aerial Navigation in Unknown Environments with Glass
May 01, 2025Autonomous aerial robots are increasingly being deployed in real-world scenarios, where transparent glass obstacles present significant challenges to reliable navigation. Researchers have investigated the use of non-contact sensors and passive contact-resilient aerial vehicle designs to detect glass surfaces, which are often limited in terms of robustness and efficiency. In this work, we propose a novel approach for robust autonomous aerial navigation in unknown environments with transparent glass obstacles, combining the strengths of both sensor-based and contact-based glass detection. The proposed system begins with the incremental detection and information maintenance about potential glass surfaces using visual sensor measurements. The vehicle then actively engages in touch actions with the visually detected potential glass surfaces using a pair of lightweight contact-sensing modules to confirm or invalidate their presence. Following this, the volumetric map is efficiently updated with the glass surface information and safe trajectories are replanned on the fly to circumvent the glass obstacles. We validate the proposed system through real-world experiments in various scenarios, demonstrating its effectiveness in enabling efficient and robust autonomous aerial navigation in complex real-world environments with glass obstacles.
Vision-Language Model for Object Detection and Segmentation: A Review and Evaluation
Apr 13, 2025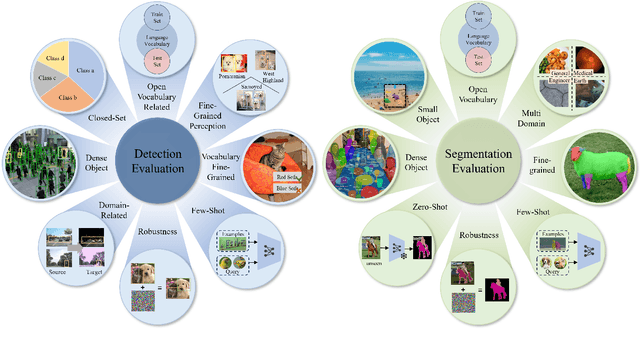
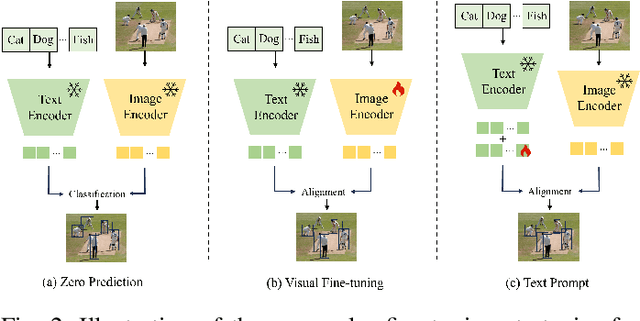
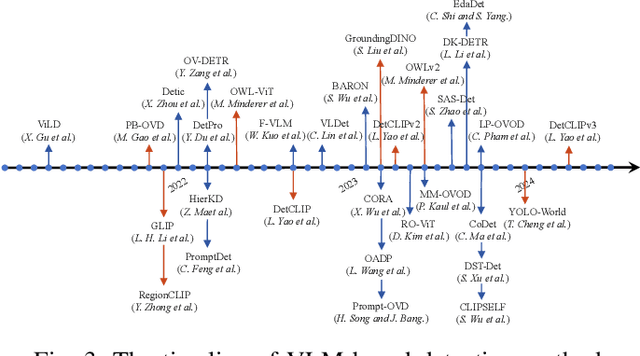
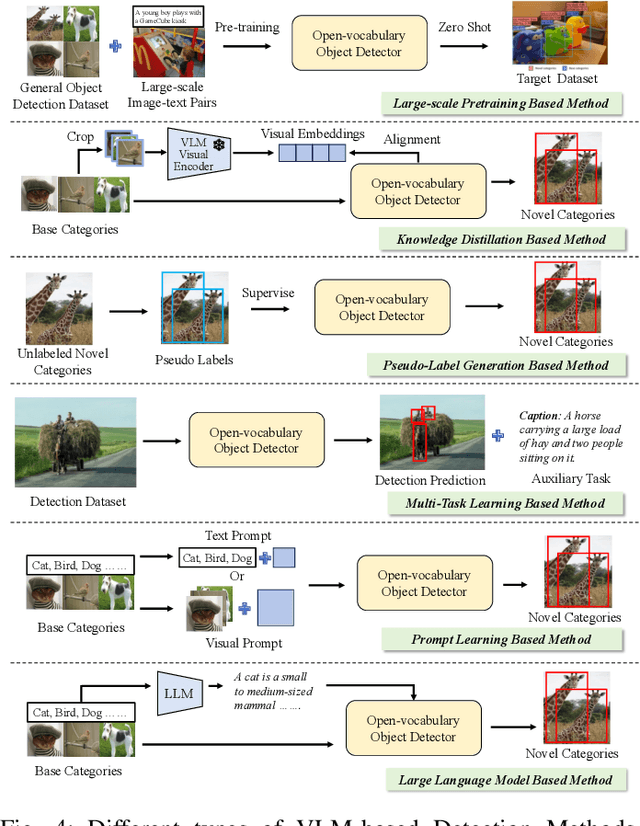
Vision-Language Model (VLM) have gained widespread adoption in Open-Vocabulary (OV) object detection and segmentation tasks. Despite they have shown promise on OV-related tasks, their effectiveness in conventional vision tasks has thus far been unevaluated. In this work, we present the systematic review of VLM-based detection and segmentation, view VLM as the foundational model and conduct comprehensive evaluations across multiple downstream tasks for the first time: 1) The evaluation spans eight detection scenarios (closed-set detection, domain adaptation, crowded objects, etc.) and eight segmentation scenarios (few-shot, open-world, small object, etc.), revealing distinct performance advantages and limitations of various VLM architectures across tasks. 2) As for detection tasks, we evaluate VLMs under three finetuning granularities: \textit{zero prediction}, \textit{visual fine-tuning}, and \textit{text prompt}, and further analyze how different finetuning strategies impact performance under varied task. 3) Based on empirical findings, we provide in-depth analysis of the correlations between task characteristics, model architectures, and training methodologies, offering insights for future VLM design. 4) We believe that this work shall be valuable to the pattern recognition experts working in the fields of computer vision, multimodal learning, and vision foundation models by introducing them to the problem, and familiarizing them with the current status of the progress while providing promising directions for future research. A project associated with this review and evaluation has been created at https://github.com/better-chao/perceptual_abilities_evaluation.
PER-DPP Sampling Framework and Its Application in Path Planning
Mar 10, 2025Autonomous navigation in intelligent mobile systems represents a core research focus within artificial intelligence-driven robotics. Contemporary path planning approaches face constraints in dynamic environmental responsiveness and multi-objective task scalability, limiting their capacity to address growing intelligent operation requirements. Decision-centric reinforcement learning frameworks, capitalizing on their unique strengths in adaptive environmental interaction and self-optimization, have gained prominence in advanced control system research. This investigation introduces methodological improvements to address sample homogeneity challenges in reinforcement learning experience replay mechanisms. By incorporating determinant point processes (DPP) for diversity assessment, we develop a dual-criteria sampling framework with adaptive selection protocols. This approach resolves representation bias in conventional prioritized experience replay (PER) systems while preserving algorithmic interoperability, offering improved decision optimization for dynamic operational scenarios. Key contributions comprise: Develop a hybrid sampling paradigm (PER-DPP) combining priority sequencing with diversity maximization.Based on this,create an integrated optimization scheme (PER-DPP-Elastic DQN) merging diversity-aware sampling with adaptive step-size regulation. Comparative simulations in 2D navigation scenarios demonstrate that the elastic step-size component temporarily delays initial convergence speed but synergistically enhances final-stage optimization with PER-DPP integration. The synthesized method generates navigation paths with optimized length efficiency and directional stability.
UniQuad: A Unified and Versatile Quadrotor Platform Series for UAV Research and Application
Jun 30, 2024


As quadrotors take on an increasingly diverse range of roles, researchers often need to develop new hardware platforms tailored for specific tasks, introducing significant engineering overhead. In this article, we introduce the UniQuad series, a unified and versatile quadrotor platform series that offers high flexibility to adapt to a wide range of common tasks, excellent customizability for advanced demands, and easy maintenance in case of crashes. This project is fully open-source at https://hkust-aerial-robotics.github.io/UniQuad.
AgentGym: Evolving Large Language Model-based Agents across Diverse Environments
Jun 06, 2024



Building generalist agents that can handle diverse tasks and evolve themselves across different environments is a long-term goal in the AI community. Large language models (LLMs) are considered a promising foundation to build such agents due to their generalized capabilities. Current approaches either have LLM-based agents imitate expert-provided trajectories step-by-step, requiring human supervision, which is hard to scale and limits environmental exploration; or they let agents explore and learn in isolated environments, resulting in specialist agents with limited generalization. In this paper, we take the first step towards building generally-capable LLM-based agents with self-evolution ability. We identify a trinity of ingredients: 1) diverse environments for agent exploration and learning, 2) a trajectory set to equip agents with basic capabilities and prior knowledge, and 3) an effective and scalable evolution method. We propose AgentGym, a new framework featuring a variety of environments and tasks for broad, real-time, uni-format, and concurrent agent exploration. AgentGym also includes a database with expanded instructions, a benchmark suite, and high-quality trajectories across environments. Next, we propose a novel method, AgentEvol, to investigate the potential of agent self-evolution beyond previously seen data across tasks and environments. Experimental results show that the evolved agents can achieve results comparable to SOTA models. We release the AgentGym suite, including the platform, dataset, benchmark, checkpoints, and algorithm implementations. The AgentGym suite is available on https://github.com/WooooDyy/AgentGym.