 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing LLM Reasoning via Critique Models with Test-Time and Training-Time Supervision
Nov 25, 2024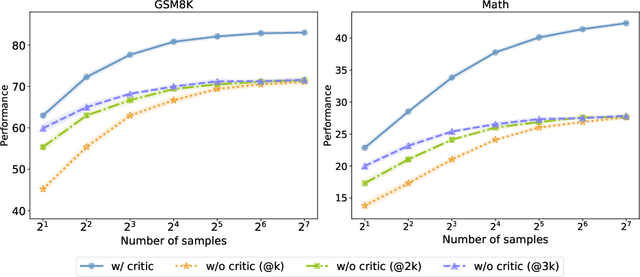

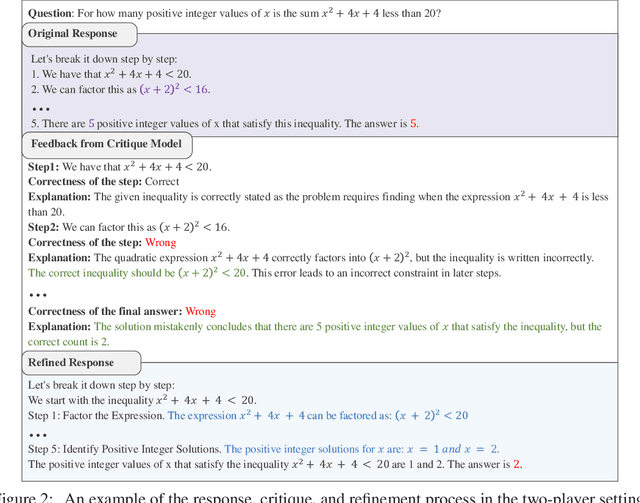

Training large language models (LLMs) to spend more time thinking and reflection before responding is crucial for effectively solving complex reasoning tasks in fields such as science, coding, and mathematics. However, the effectiveness of mechanisms like self-reflection and self-correction depends on the model's capacity to accurately assess its own performance, which can be limited by factors such as initial accuracy, question difficulty, and the lack of external feedback. In this paper, we delve into a two-player paradigm that separates the roles of reasoning and critique models, where the critique model provides step-level feedback to supervise the reasoning (actor) model during both test-time and train-time. We first propose AutoMathCritique, an automated and scalable framework for collecting critique data, resulting in a dataset of $76,321$ responses paired with step-level feedback. Fine-tuning language models with this dataset enables them to generate natural language feedback for mathematical reasoning. We demonstrate that the critique models consistently improve the actor's performance on difficult queries at test-time, especially when scaling up inference-time computation. Motivated by these findings, we introduce the critique-based supervision to the actor's self-training process, and propose a critique-in-the-loop self-improvement method. Experiments show that the method improves the actor's exploration efficiency and solution diversity, especially on challenging queries, leading to a stronger reasoning model. Lastly, we take the preliminary step to explore training self-talk reasoning models via critique supervision and showcase its potential. Our code and datasets are at \href{https://mathcritique.github.io/}{https://mathcritique.github.io/}.
Multi-Programming Language Sandbox for LLMs
Oct 30, 2024



We introduce MPLSandbox, an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for Large Language Models (LLMs). It can automatically identify the programming language of the code, compiling and executing it within an isolated sub-sandbox to ensure safety and stability. In addition, MPLSandbox also integrates both traditional and LLM-based code analysis tools, providing a comprehensive analysis of generated code. MPLSandbox can be effortlessly integrated into the training and deployment of LLMs to improve the quality and correctness of their generated code. It also helps researchers streamline their workflows for various LLM-based code-related tasks, reducing the development cost. To validate the effectiveness of MPLSandbox, we integrate it into training and deployment approaches, and also employ it to optimize workflows for a wide range of real-world code-related tasks. Our goal is to enhance researcher productivity on LLM-based code-related tasks by simplifying and automating workflows through delegation to MPLSandbox.
Loose lips sink ships: Mitigating Length Bias in Reinforcement Learning from Human Feedback
Oct 19, 2023Reinforcement learning from human feedback serves as a crucial bridge, aligning large language models with human and societal values. This alignment requires a vast corpus of human feedback to learn a reward model, which is subsequently used to finetune language models. However, we have identified that the reward model often finds shortcuts to bypass its intended objectives, misleadingly assuming that humans prefer longer responses. The emergence of length bias often induces the model to favor longer outputs, yet it doesn't equate to an increase in helpful information within these outputs. In this paper, we propose an innovative solution, applying the Product-of-Experts (PoE) technique to separate reward modeling from the influence of sequence length. In our framework, the main expert concentrates on understanding human intents, while the biased expert targets the identification and capture of length bias. To further enhance the learning of bias, we introduce perturbations into the bias-focused expert, disrupting the flow of semantic information. Experimental results validate the effectiveness of our approach, indicating that language model performance is improved, irrespective of sequence length.
RE-Matching: A Fine-Grained Semantic Matching Method for Zero-Shot Relation Extraction
Jun 08, 2023Semantic matching is a mainstream paradigm of zero-shot relation extraction, which matches a given input with a corresponding label description. The entities in the input should exactly match their hypernyms in the description, while the irrelevant contexts should be ignored when matching. However, general matching methods lack explicit modeling of the above matching pattern. In this work, we propose a fine-grained semantic matching method tailored for zero-shot relation extraction. Following the above matching pattern, we decompose the sentence-level similarity score into entity and context matching scores. Due to the lack of explicit annotations of the redundant components, we design a feature distillation module to adaptively identify the relation-irrelevant features and reduce their negative impact on context matching. Experimental results show that our method achieves higher matching $F_1$ score and has an inference speed 10 times faster, when compared with the state-of-the-art methods.
Open Set Relation Extraction via Unknown-Aware Training
Jun 08, 2023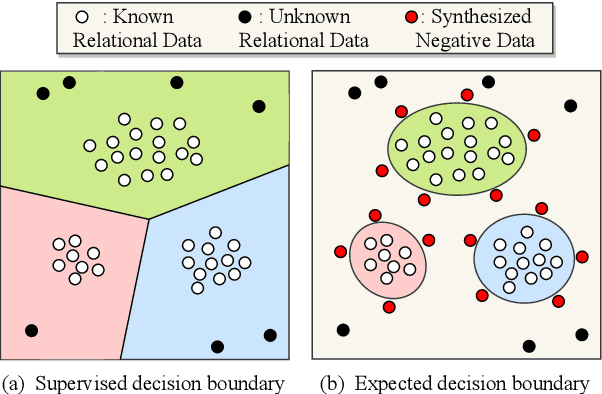
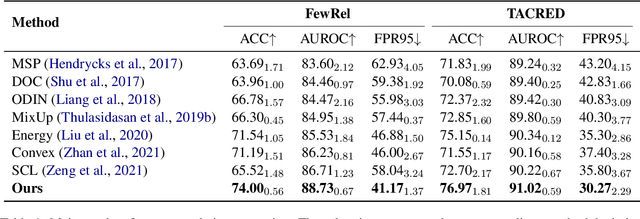
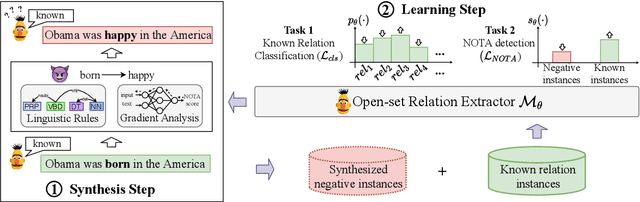
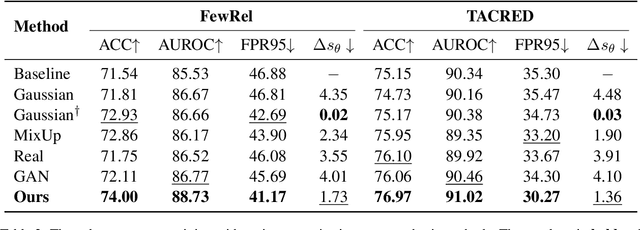
The existing supervised relation extraction methods have achieved impressive performance in a closed-set setting, where the relations during both training and testing remain the same. In a more realistic open-set setting, unknown relations may appear in the test set. Due to the lack of supervision signals from unknown relations, a well-performing closed-set relation extractor can still confidently misclassify them into known relations. In this paper, we propose an unknown-aware training method, regularizing the model by dynamically synthesizing negative instances. To facilitate a compact decision boundary, ``difficult'' negative instances are necessary. Inspired by text adversarial attacks, we adaptively apply small but critical perturbations to original training instances and thus synthesizing negative instances that are more likely to be mistaken by the model as known relations. Experimental results show that this method achieves SOTA unknown relation detection without compromising the classification of known relations.