 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFPO: Scaling Value Modeling via Distributional Flow towards Robust and Generalizable LLM Post-Training
Feb 05, 2026Training reinforcement learning (RL) systems in real-world environments remains challenging due to noisy supervision and poor out-of-domain (OOD) generalization, especially in LLM post-training. Recent distributional RL methods improve robustness by modeling values with multiple quantile points, but they still learn each quantile independently as a scalar. This results in rough-grained value representations that lack fine-grained conditioning on state information, struggling under complex and OOD conditions. We propose DFPO (Distributional Value Flow Policy Optimization with Conditional Risk and Consistency Control), a robust distributional RL framework that models values as continuous flows across time steps. By scaling value modeling through learning of a value flow field instead of isolated quantile predictions, DFPO captures richer state information for more accurate advantage estimation. To stabilize training under noisy feedback, DFPO further integrates conditional risk control and consistency constraints along value flow trajectories. Experiments on dialogue, math reasoning, and scientific tasks show that DFPO outperforms PPO, FlowRL, and other robust baselines under noisy supervision, achieving improved training stability and generalization.
ABC-Bench: Benchmarking Agentic Backend Coding in Real-World Development
Jan 16, 2026The evolution of Large Language Models (LLMs) into autonomous agents has expanded the scope of AI coding from localized code generation to complex, repository-level, and execution-driven problem solving. However, current benchmarks predominantly evaluate code logic in static contexts, neglecting the dynamic, full-process requirements of real-world engineering, particularly in backend development which demands rigorous environment configuration and service deployment. To address this gap, we introduce ABC-Bench, a benchmark explicitly designed to evaluate agentic backend coding within a realistic, executable workflow. Using a scalable automated pipeline, we curated 224 practical tasks spanning 8 languages and 19 frameworks from open-source repositories. Distinct from previous evaluations, ABC-Bench require the agents to manage the entire development lifecycle from repository exploration to instantiating containerized services and pass the external end-to-end API tests. Our extensive evaluation reveals that even state-of-the-art models struggle to deliver reliable performance on these holistic tasks, highlighting a substantial disparity between current model capabilities and the demands of practical backend engineering. Our code is available at https://github.com/OpenMOSS/ABC-Bench.
OctoBench: Benchmarking Scaffold-Aware Instruction Following in Repository-Grounded Agentic Coding
Jan 16, 2026Modern coding scaffolds turn LLMs into capable software agents, but their ability to follow scaffold-specified instructions remains under-examined, especially when constraints are heterogeneous and persist across interactions. To fill this gap, we introduce OctoBench, which benchmarks scaffold-aware instruction following in repository-grounded agentic coding. OctoBench includes 34 environments and 217 tasks instantiated under three scaffold types, and is paired with 7,098 objective checklist items. To disentangle solving the task from following the rules, we provide an automated observation-and-scoring toolkit that captures full trajectories and performs fine-grained checks. Experiments on eight representative models reveal a systematic gap between task-solving and scaffold-aware compliance, underscoring the need for training and evaluation that explicitly targets heterogeneous instruction following. We release the benchmark to support reproducible benchmarking and to accelerate the development of more scaffold-aware coding agents.
Memory in the Age of AI Agents
Dec 15, 2025Memory has emerged, and will continue to remain, a core capability of foundation model-based agents. As research on agent memory rapidly expands and attracts unprecedented attention, the field has also become increasingly fragmented. Existing works that fall under the umbrella of agent memory often differ substantially in their motivations, implementations, and evaluation protocols, while the proliferation of loosely defined memory terminologies has further obscured conceptual clarity. Traditional taxonomies such as long/short-term memory have proven insufficient to capture the diversity of contemporary agent memory systems. This work aims to provide an up-to-date landscape of current agent memory research. We begin by clearly delineating the scope of agent memory and distinguishing it from related concepts such as LLM memory, retrieval augmented generation (RAG), and context engineering. We then examine agent memory through the unified lenses of forms, functions, and dynamics. From the perspective of forms, we identify three dominant realizations of agent memory, namely token-level, parametric, and latent memory. From the perspective of functions, we propose a finer-grained taxonomy that distinguishes factual, experiential, and working memory. From the perspective of dynamics, we analyze how memory is formed, evolved, and retrieved over time. To support practical development, we compile a comprehensive summary of memory benchmarks and open-source frameworks. Beyond consolidation, we articulate a forward-looking perspective on emerging research frontiers, including memory automation, reinforcement learning integration, multimodal memory, multi-agent memory, and trustworthiness issues. We hope this survey serves not only as a reference for existing work, but also as a conceptual foundation for rethinking memory as a first-class primitive in the design of future agentic intelligence.
LLMEval-3: A Large-Scale Longitudinal Study on Robust and Fair Evaluation of Large Language Models
Aug 07, 2025Existing evaluation of Large Language Models (LLMs) on static benchmarks is vulnerable to data contamination and leaderboard overfitting, critical issues that obscure true model capabilities. To address this, we introduce LLMEval-3, a framework for dynamic evaluation of LLMs. LLMEval-3 is built on a proprietary bank of 220k graduate-level questions, from which it dynamically samples unseen test sets for each evaluation run. Its automated pipeline ensures integrity via contamination-resistant data curation, a novel anti-cheating architecture, and a calibrated LLM-as-a-judge process achieving 90% agreement with human experts, complemented by a relative ranking system for fair comparison. An 20-month longitudinal study of nearly 50 leading models reveals a performance ceiling on knowledge memorization and exposes data contamination vulnerabilities undetectable by static benchmarks. The framework demonstrates exceptional robustness in ranking stability and consistency, providing strong empirical validation for the dynamic evaluation paradigm. LLMEval-3 offers a robust and credible methodology for assessing the true capabilities of LLMs beyond leaderboard scores, promoting the development of more trustworthy evaluation standards.
LLMEval-Med: A Real-world Clinical Benchmark for Medical LLMs with Physician Validation
Jun 04, 2025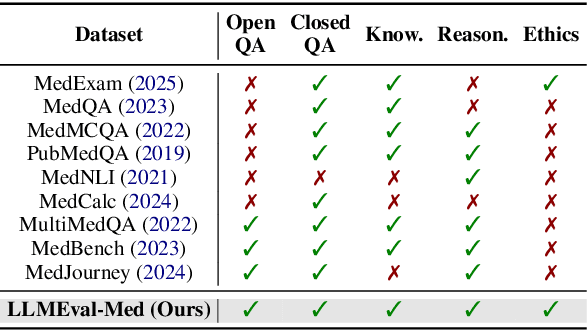
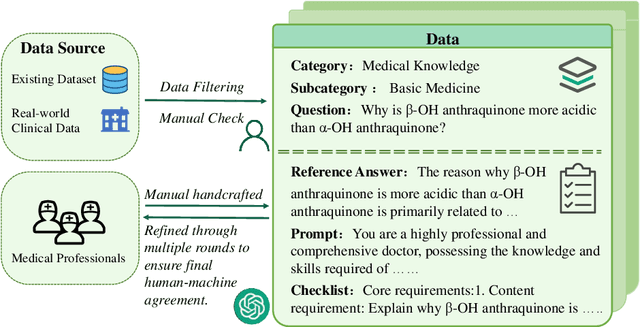
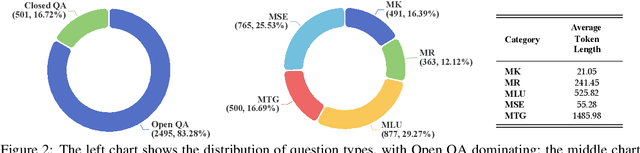
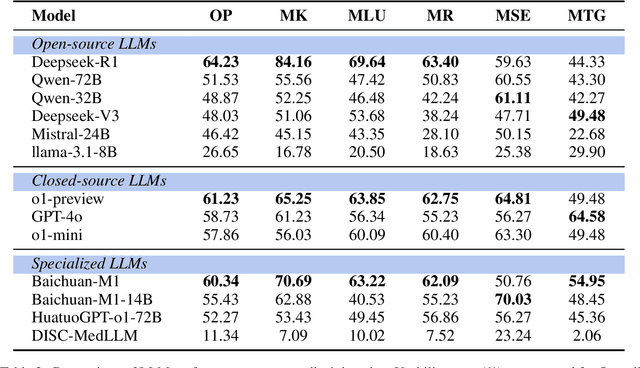
Evaluating large language models (LLMs) in medicine is crucial because medical applications require high accuracy with little room for error. Current medical benchmarks have three main types: medical exam-based, comprehensive medical, and specialized assessments. However, these benchmarks have limitations in question design (mostly multiple-choice), data sources (often not derived from real clinical scenarios), and evaluation methods (poor assessment of complex reasoning). To address these issues, we present LLMEval-Med, a new benchmark covering five core medical areas, including 2,996 questions created from real-world electronic health records and expert-designed clinical scenarios. We also design an automated evaluation pipeline, incorporating expert-developed checklists into our LLM-as-Judge framework. Furthermore, our methodology validates machine scoring through human-machine agreement analysis, dynamically refining checklists and prompts based on expert feedback to ensure reliability. We evaluate 13 LLMs across three categories (specialized medical models, open-source models, and closed-source models) on LLMEval-Med, providing valuable insights for the safe and effective deployment of LLMs in medical domains. The dataset is released in https://github.com/llmeval/LLMEval-Med.
Multi-Programming Language Sandbox for LLMs
Oct 30, 2024



We introduce MPLSandbox, an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for Large Language Models (LLMs). It can automatically identify the programming language of the code, compiling and executing it within an isolated sub-sandbox to ensure safety and stability. In addition, MPLSandbox also integrates both traditional and LLM-based code analysis tools, providing a comprehensive analysis of generated code. MPLSandbox can be effortlessly integrated into the training and deployment of LLMs to improve the quality and correctness of their generated code. It also helps researchers streamline their workflows for various LLM-based code-related tasks, reducing the development cost. To validate the effectiveness of MPLSandbox, we integrate it into training and deployment approaches, and also employ it to optimize workflows for a wide range of real-world code-related tasks. Our goal is to enhance researcher productivity on LLM-based code-related tasks by simplifying and automating workflows through delegation to MPLSandbox.
TransferTOD: A Generalizable Chinese Multi-Domain Task-Oriented Dialogue System with Transfer Capabilities
Jul 31, 2024



Task-oriented dialogue (TOD) systems aim to efficiently handle task-oriented conversations, including information gathering. How to utilize ToD accurately, efficiently and effectively for information gathering has always been a critical and challenging task. Recent studies have demonstrated that Large Language Models (LLMs) excel in dialogue, instruction generation, and reasoning, and can significantly enhance the performance of TOD through fine-tuning. However, current datasets primarily cater to user-led systems and are limited to predefined specific scenarios and slots, thereby necessitating improvements in the proactiveness, diversity, and capabilities of TOD. In this study, we present a detailed multi-domain task-oriented data construction process for conversations, and a Chinese dialogue dataset generated based on this process, \textbf{TransferTOD}, which authentically simulates human-machine dialogues in 30 popular life service scenarios. Leveraging this dataset, we trained a \textbf{TransferTOD-7B} model using full-parameter fine-tuning, showcasing notable abilities in slot filling and questioning. Our work has demonstrated its strong generalization capabilities in various downstream scenarios, significantly enhancing both data utilization efficiency and system performance. The data is released in https://github.com/KongLongGeFDU/TransferTOD.
Self-Demos: Eliciting Out-of-Demonstration Generalizability in Large Language Models
Apr 01, 2024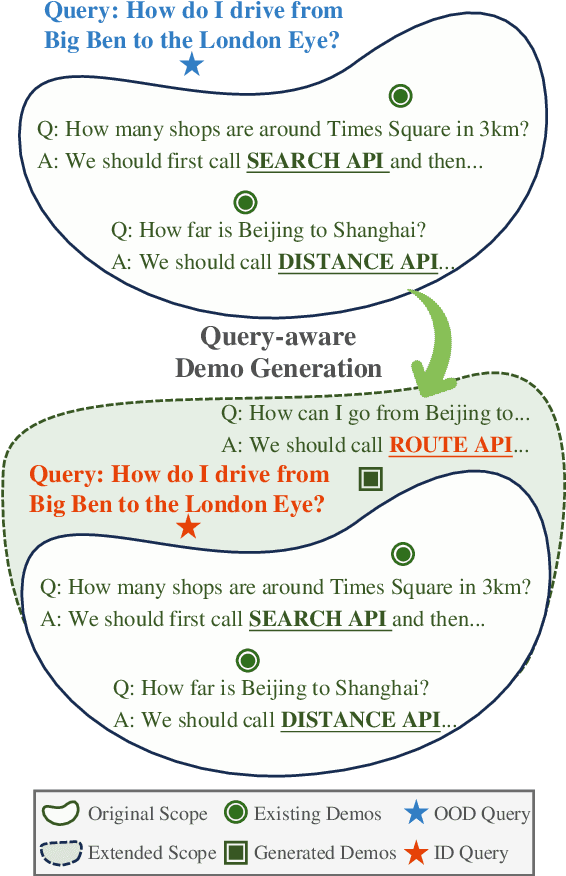



Large language models (LLMs) have shown promising abilities of in-context learning (ICL), adapting swiftly to new tasks with only few-shot demonstrations. However, current few-shot methods heavily depend on high-quality, query-specific demos, which are often lacking. When faced with out-of-demonstration (OOD) queries, methods that rely on hand-crafted demos or external retrievers might fail. To bridge the gap between limited demos and OOD queries, we propose Self-Demos, a novel prompting method that elicits the inherent generalizability in LLMs by query-aware demo generation. The generated demos strategically interpolate between existing demos and the given query, transforming the query from OOD to ID. To evaluate the effectiveness of our approach, we manually constructed OOD-Toolset, a dataset in the tool-using scenario with over 300 real-world APIs and 1000 instances, each consisting of three tool-use cases as demos and an OOD query. Thorough experiments on our dataset and two public math benchmarks have shown that our method can outperform state-of-the-art baselines in the OOD setting. Moreover, we conduct a range of analyses to validate Self-Demos's generalization and provide more insights.
Training Large Language Models for Reasoning through Reverse Curriculum Reinforcement Learning
Feb 08, 2024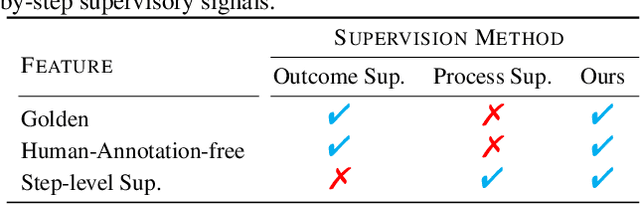
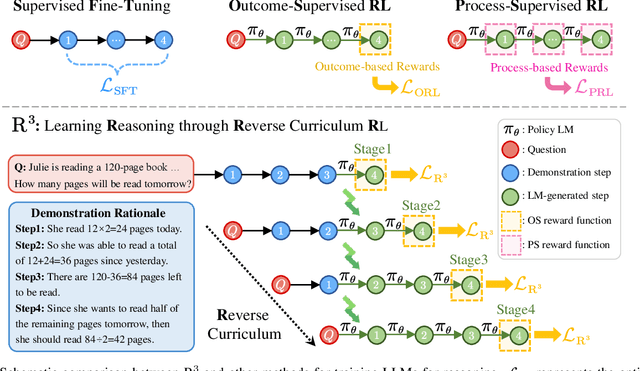
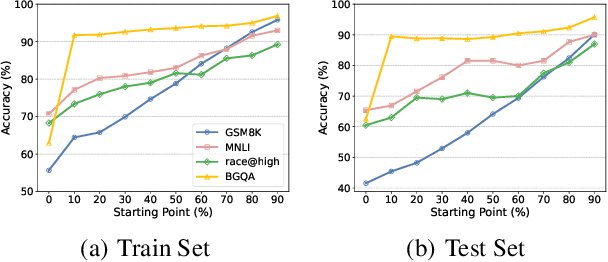

In this paper, we propose R$^3$: Learning Reasoning through Reverse Curriculum Reinforcement Learning (RL), a novel method that employs only outcome supervision to achieve the benefits of process supervision for large language models. The core challenge in applying RL to complex reasoning is to identify a sequence of actions that result in positive rewards and provide appropriate supervision for optimization. Outcome supervision provides sparse rewards for final results without identifying error locations, whereas process supervision offers step-wise rewards but requires extensive manual annotation. R$^3$ overcomes these limitations by learning from correct demonstrations. Specifically, R$^3$ progressively slides the start state of reasoning from a demonstration's end to its beginning, facilitating easier model exploration at all stages. Thus, R$^3$ establishes a step-wise curriculum, allowing outcome supervision to offer step-level signals and precisely pinpoint errors. Using Llama2-7B, our method surpasses RL baseline on eight reasoning tasks by $4.1$ points on average. Notebaly, in program-based reasoning on GSM8K, it exceeds the baseline by $4.2$ points across three backbone models, and without any extra data, Codellama-7B + R$^3$ performs comparable to larger models or closed-source models.