 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Capability Analysis of GPT-3 and GPT-3.5 Series Models
Mar 18, 2023
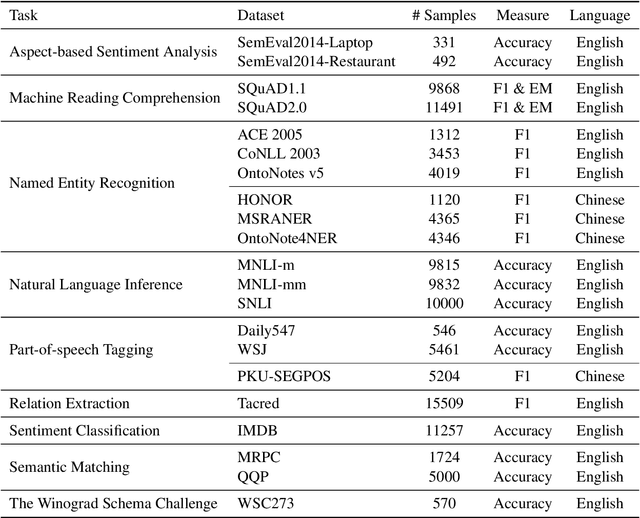
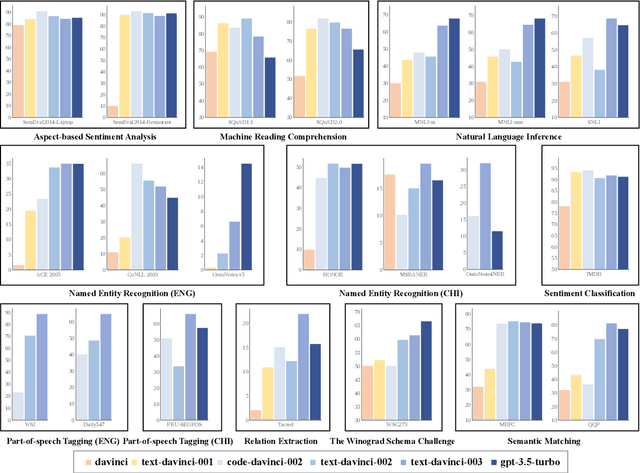
GPT series models, such as GPT-3, CodeX, InstructGPT, ChatGPT, and so on, have gained considerable attention due to their exceptional natural language processing capabilities. However, despite the abundance of research on the difference in capabilities between GPT series models and fine-tuned models, there has been limited attention given to the evolution of GPT series models' capabilities over time. To conduct a comprehensive analysis of the capabilities of GPT series models, we select six representative models, comprising two GPT-3 series models (i.e., davinci and text-davinci-001) and four GPT-3.5 series models (i.e., code-davinci-002, text-davinci-002, text-davinci-003, and gpt-3.5-turbo). We evaluate their performance on nine natural language understanding (NLU) tasks using 21 datasets. In particular, we compare the performance and robustness of different models for each task under zero-shot and few-shot scenarios. Our extensive experiments reveal that the overall ability of GPT series models on NLU tasks does not increase gradually as the models evolve, especially with the introduction of the RLHF training strategy. While this strategy enhances the models' ability to generate human-like responses, it also compromises their ability to solve some tasks. Furthermore, our findings indicate that there is still room for improvement in areas such as model robustness.
How Robust is GPT-3.5 to Predecessors? A Comprehensive Study on Language Understanding Tasks
Mar 01, 2023

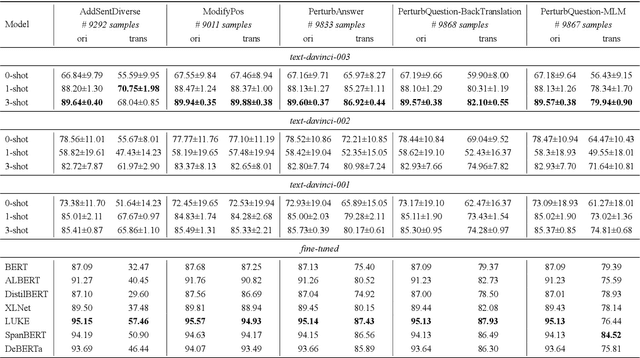

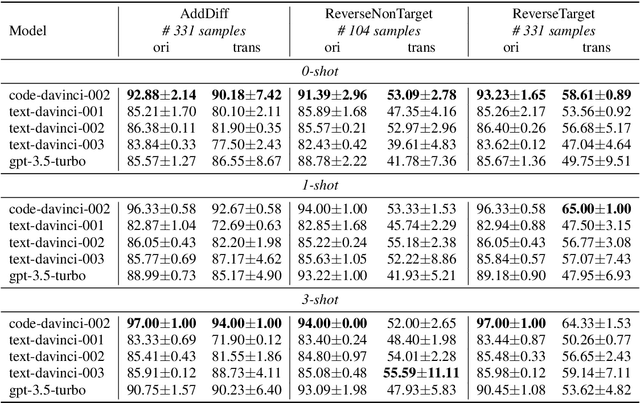
The GPT-3.5 models have demonstrated impressive performance in various Natural Language Processing (NLP) tasks, showcasing their strong understanding and reasoning capabilities. However, their robustness and abilities to handle various complexities of the open world have yet to be explored, which is especially crucial in assessing the stability of models and is a key aspect of trustworthy AI. In this study, we perform a comprehensive experimental analysis of GPT-3.5, exploring its robustness using 21 datasets (about 116K test samples) with 66 text transformations from TextFlint that cover 9 popular Natural Language Understanding (NLU) tasks. Our findings indicate that while GPT-3.5 outperforms existing fine-tuned models on some tasks, it still encounters significant robustness degradation, such as its average performance dropping by up to 35.74\% and 43.59\% in natural language inference and sentiment analysis tasks, respectively. We also show that GPT-3.5 faces some specific robustness challenges, including robustness instability, prompt sensitivity, and number sensitivity. These insights are valuable for understanding its limitations and guiding future research in addressing these challenges to enhance GPT-3.5's overall performance and generalization abilities.
Learning "O" Helps for Learning More: Handling the Concealed Entity Problem for Class-incremental NER
Oct 10, 2022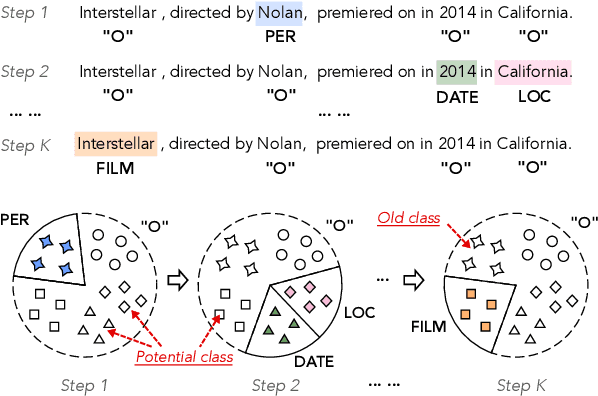
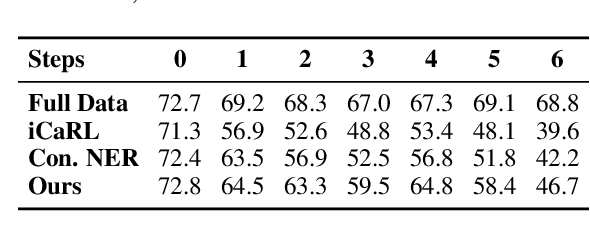
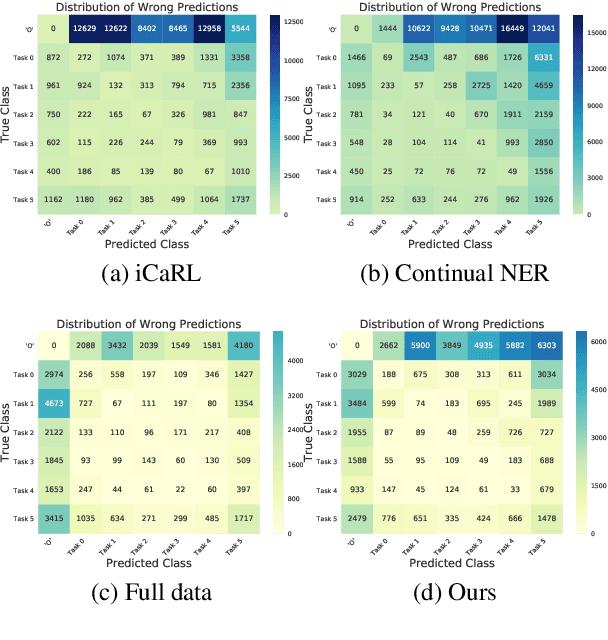
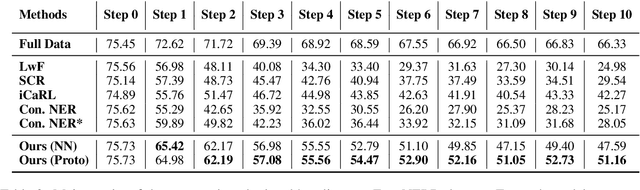
As the categories of named entities rapidly increase in real-world applications, class-incremental learning for NER is in demand, which continually learns new entity classes while maintaining the old knowledge. Due to privacy concerns and storage constraints, the model is required to update without any annotations of the old entity classes. However, in each step on streaming data, the "O" class in each step might contain unlabeled entities from the old classes, or potential entities from the incoming classes. In this work, we first carry out an empirical study to investigate the concealed entity problem in class-incremental NER. We find that training with "O" leads to severe confusion of "O" and concealed entity classes, and harms the separability of potential classes. Based on this discovery, we design a rehearsal-based representation learning approach for appropriately learning the "O" class for both old and potential entity classes. Additionally, we provide a more realistic and challenging benchmark for class-incremental NER which introduces multiple categories in each step. Experimental results verify our findings and show the effectiveness of the proposed method on the new benchmark.
Searching for Optimal Subword Tokenization in Cross-domain NER
Jun 07, 2022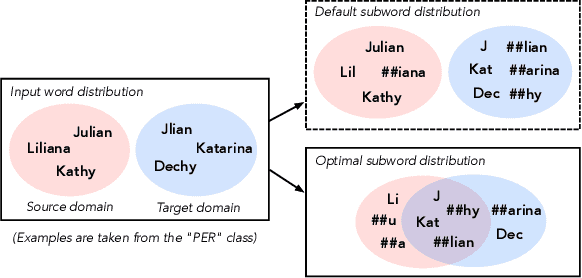

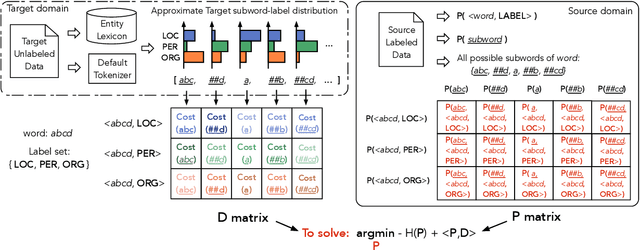
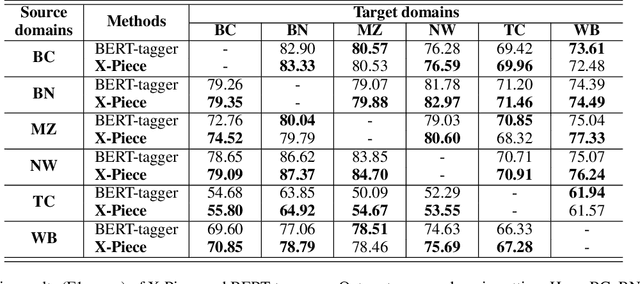
Input distribution shift is one of the vital problems in unsupervised domain adaptation (UDA). The most popular UDA approaches focus on domain-invariant representation learning, trying to align the features from different domains into similar feature distributions. However, these approaches ignore the direct alignment of input word distributions between domains, which is a vital factor in word-level classification tasks such as cross-domain NER. In this work, we shed new light on cross-domain NER by introducing a subword-level solution, X-Piece, for input word-level distribution shift in NER. Specifically, we re-tokenize the input words of the source domain to approach the target subword distribution, which is formulated and solved as an optimal transport problem. As this approach focuses on the input level, it can also be combined with previous DIRL methods for further improvement. Experimental results show the effectiveness of the proposed method based on BERT-tagger on four benchmark NER datasets. Also, the proposed method is proved to benefit DIRL methods such as DANN.