 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImageAttributionBench: How Far Are We from Generalizable Attribution?
May 13, 2026The rapid advancement of generative AI has enabled the creation of highly realistic and diverse synthetic images, posing critical challenges for image provenance and misinformation detection. This underscores the urgent need for effective image attribution. However, existing attribution datasets are constrained by limited scale, outdated generation methods, and insufficient semantic diversity - hindering the development of robust and generalizable attribution models. To address these limitations, we introduce ImageAttributionBench, a comprehensive dataset comprising images synthesized by a wide array of advanced generative models with state-of-the-art (SOTA) architectures. Covering multiple real-world semantic domains, the dataset offers rich diversity and scale to support and accelerate progress in image attribution research. To simulate real-world attribution scenarios, we evaluate several SOTA attribution methods on ImageAttributionBench under two challenging settings: (1) training on a standard balanced split and testing on degraded images, and (2) training and testing on semantically disjoint splits. In both cases, current methods exhibit consistently poor performance, revealing significant limitations in their robustness and generalization to unseen semantic content. Our work provides a rigorous benchmark to facilitate the development and evaluation of future image attribution methods.
FreeInpaint: Tuning-free Prompt Alignment and Visual Rationality Enhancement in Image Inpainting
Dec 24, 2025Text-guided image inpainting endeavors to generate new content within specified regions of images using textual prompts from users. The primary challenge is to accurately align the inpainted areas with the user-provided prompts while maintaining a high degree of visual fidelity. While existing inpainting methods have produced visually convincing results by leveraging the pre-trained text-to-image diffusion models, they still struggle to uphold both prompt alignment and visual rationality simultaneously. In this work, we introduce FreeInpaint, a plug-and-play tuning-free approach that directly optimizes the diffusion latents on the fly during inference to improve the faithfulness of the generated images. Technically, we introduce a prior-guided noise optimization method that steers model attention towards valid inpainting regions by optimizing the initial noise. Furthermore, we meticulously design a composite guidance objective tailored specifically for the inpainting task. This objective efficiently directs the denoising process, enhancing prompt alignment and visual rationality by optimizing intermediate latents at each step. Through extensive experiments involving various inpainting diffusion models and evaluation metrics, we demonstrate the effectiveness and robustness of our proposed FreeInpaint.
EchoingPixels: Cross-Modal Adaptive Token Reduction for Efficient Audio-Visual LLMs
Dec 11, 2025
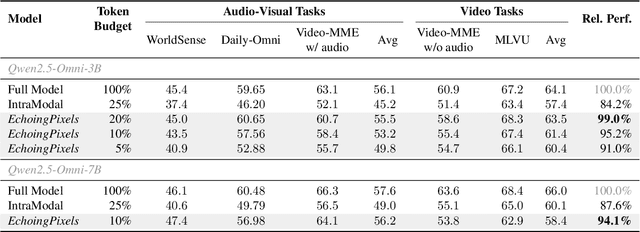
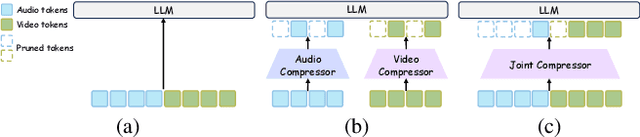
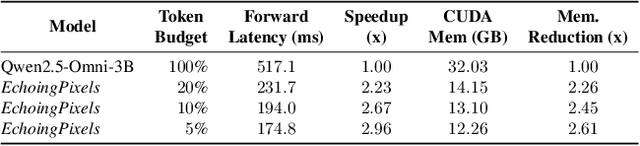
Audio-Visual Large Language Models (AV-LLMs) face prohibitive computational overhead from massive audio and video tokens. Token reduction, while extensively explored for video-only LLMs, is insufficient for the audio-visual domain, as these unimodal methods cannot leverage audio-visual cross-modal synergies. Furthermore, the distinct and dynamic information densities of audio and video render static budgets per modality suboptimal. How to perform token reduction on a joint audio-visual stream thus remains an unaddressed bottleneck. To fill this gap, we introduce EchoingPixels, a framework inspired by the coexistence and interaction of visuals and sound in real-world scenes. The core of our framework is the Cross-Modal Semantic Sieve (CS2), a module enabling early audio-visual interaction. Instead of compressing modalities independently, CS2 co-attends to the joint multimodal stream and reduces tokens from an entire combined pool of audio-visual tokens rather than using fixed budgets per modality. This single-pool approach allows it to adaptively allocate the token budget across both modalities and dynamically identify salient tokens in concert. To ensure this aggressive reduction preserves the vital temporal modeling capability, we co-design a Synchronization-Augmented RoPE (Sync-RoPE) to maintain critical temporal relationships for the sparsely selected tokens. Extensive experiments demonstrate that EchoingPixels achieves performance comparable to strong baselines using only 5-20% of the original tokens, with a 2-3x speedup and memory reduction.
DuMo: Dual Encoder Modulation Network for Precise Concept Erasure
Jan 02, 2025



The exceptional generative capability of text-to-image models has raised substantial safety concerns regarding the generation of Not-Safe-For-Work (NSFW) content and potential copyright infringement. To address these concerns, previous methods safeguard the models by eliminating inappropriate concepts. Nonetheless, these models alter the parameters of the backbone network and exert considerable influences on the structural (low-frequency) components of the image, which undermines the model's ability to retain non-target concepts. In this work, we propose our Dual encoder Modulation network (DuMo), which achieves precise erasure of inappropriate target concepts with minimum impairment to non-target concepts. In contrast to previous methods, DuMo employs the Eraser with PRior Knowledge (EPR) module which modifies the skip connection features of the U-NET and primarily achieves concept erasure on details (high-frequency) components of the image. To minimize the damage to non-target concepts during erasure, the parameters of the backbone U-NET are frozen and the prior knowledge from the original skip connection features is introduced to the erasure process. Meanwhile, the phenomenon is observed that distinct erasing preferences for the image structure and details are demonstrated by the EPR at different timesteps and layers. Therefore, we adopt a novel Time-Layer MOdulation process (TLMO) that adjusts the erasure scale of EPR module's outputs across different layers and timesteps, automatically balancing the erasure effects and model's generative ability. Our method achieves state-of-the-art performance on Explicit Content Erasure, Cartoon Concept Removal and Artistic Style Erasure, clearly outperforming alternative methods. Code is available at https://github.com/Maplebb/DuMo
Reliable and Efficient Concept Erasure of Text-to-Image Diffusion Models
Jul 17, 2024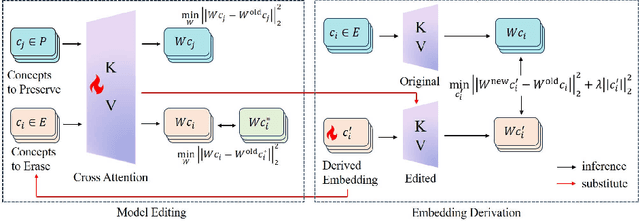
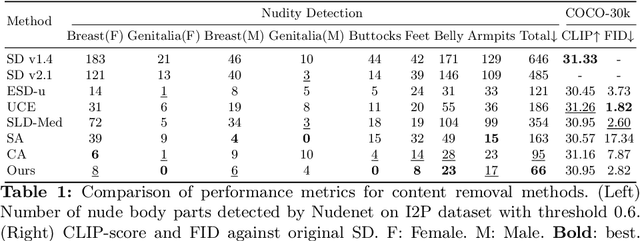

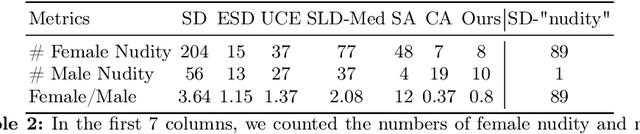
Text-to-image models encounter safety issues, including concerns related to copyright and Not-Safe-For-Work (NSFW) content. Despite several methods have been proposed for erasing inappropriate concepts from diffusion models, they often exhibit incomplete erasure, consume a lot of computing resources, and inadvertently damage generation ability. In this work, we introduce Reliable and Efficient Concept Erasure (RECE), a novel approach that modifies the model in 3 seconds without necessitating additional fine-tuning. Specifically, RECE efficiently leverages a closed-form solution to derive new target embeddings, which are capable of regenerating erased concepts within the unlearned model. To mitigate inappropriate content potentially represented by derived embeddings, RECE further aligns them with harmless concepts in cross-attention layers. The derivation and erasure of new representation embeddings are conducted iteratively to achieve a thorough erasure of inappropriate concepts. Besides, to preserve the model's generation ability, RECE introduces an additional regularization term during the derivation process, resulting in minimizing the impact on unrelated concepts during the erasure process. All the processes above are in closed-form, guaranteeing extremely efficient erasure in only 3 seconds. Benchmarking against previous approaches, our method achieves more efficient and thorough erasure with minor damage to original generation ability and demonstrates enhanced robustness against red-teaming tools. Code is available at \url{https://github.com/CharlesGong12/RECE}.
A Comprehensive Capability Analysis of GPT-3 and GPT-3.5 Series Models
Mar 18, 2023
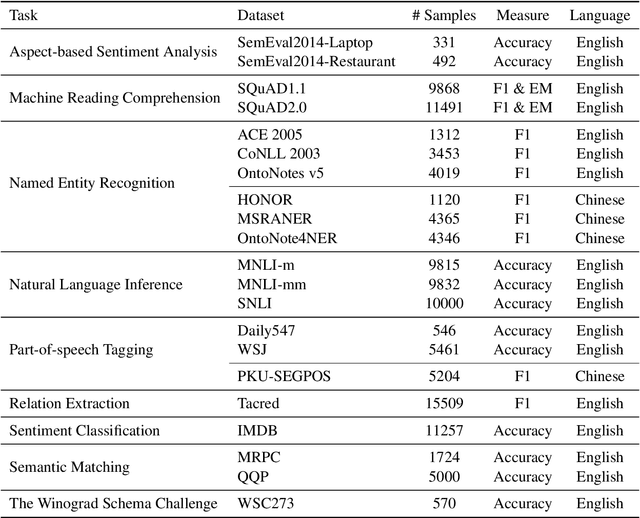
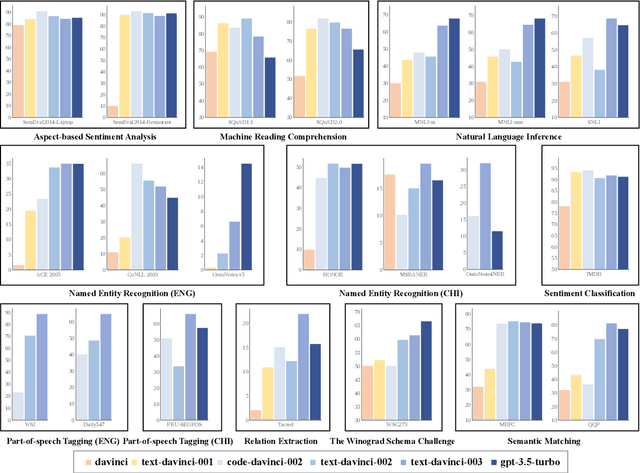
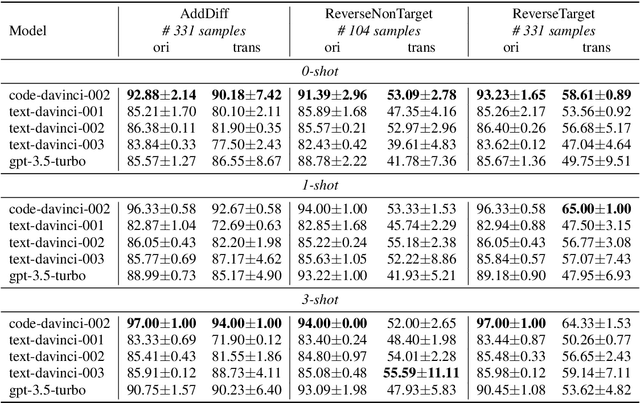
GPT series models, such as GPT-3, CodeX, InstructGPT, ChatGPT, and so on, have gained considerable attention due to their exceptional natural language processing capabilities. However, despite the abundance of research on the difference in capabilities between GPT series models and fine-tuned models, there has been limited attention given to the evolution of GPT series models' capabilities over time. To conduct a comprehensive analysis of the capabilities of GPT series models, we select six representative models, comprising two GPT-3 series models (i.e., davinci and text-davinci-001) and four GPT-3.5 series models (i.e., code-davinci-002, text-davinci-002, text-davinci-003, and gpt-3.5-turbo). We evaluate their performance on nine natural language understanding (NLU) tasks using 21 datasets. In particular, we compare the performance and robustness of different models for each task under zero-shot and few-shot scenarios. Our extensive experiments reveal that the overall ability of GPT series models on NLU tasks does not increase gradually as the models evolve, especially with the introduction of the RLHF training strategy. While this strategy enhances the models' ability to generate human-like responses, it also compromises their ability to solve some tasks. Furthermore, our findings indicate that there is still room for improvement in areas such as model robustness.