 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink, Then Verify: A Hypothesis-Verification Multi-Agent Framework for Long Video Understanding
Mar 05, 2026Long video understanding is challenging due to dense visual redundancy, long-range temporal dependencies, and the tendency of chain-of-thought and retrieval-based agents to accumulate semantic drift and correlation-driven errors. We argue that long-video reasoning should begin not with reactive retrieval, but with deliberate task formulation: the model must first articulate what must be true in the video for each candidate answer to hold. This thinking-before-finding principle motivates VideoHV-Agent, a framework that reformulates video question answering as a structured hypothesis-verification process. Based on video summaries, a Thinker rewrites answer candidates into testable hypotheses, a Judge derives a discriminative clue specifying what evidence must be checked, a Verifier grounds and tests the clue using localized, fine-grained video content, and an Answer agent integrates validated evidence to produce the final answer. Experiments on three long-video understanding benchmarks show that VideoHV-Agent achieves state-of-the-art accuracy while providing enhanced interpretability, improved logical soundness, and lower computational cost. We make our code publicly available at: https://github.com/Haorane/VideoHV-Agent.
Is Reasoning Capability Enough for Safety in Long-Context Language Models?
Feb 09, 2026Large language models (LLMs) increasingly combine long-context processing with advanced reasoning, enabling them to retrieve and synthesize information distributed across tens of thousands of tokens. A hypothesis is that stronger reasoning capability should improve safety by helping models recognize harmful intent even when it is not stated explicitly. We test this hypothesis in long-context settings where harmful intent is implicit and must be inferred through reasoning, and find that it does not hold. We introduce compositional reasoning attacks, a new threat model in which a harmful query is decomposed into incomplete fragments that scattered throughout a long context. The model is then prompted with a neutral reasoning query that induces retrieval and synthesis, causing the harmful intent to emerge only after composition. Evaluating 14 frontier LLMs on contexts up to 64k tokens, we uncover three findings: (1) models with stronger general reasoning capability are not more robust to compositional reasoning attacks, often assembling the intent yet failing to refuse; (2) safety alignment consistently degrades as context length increases; and (3) inference-time reasoning effort is a key mitigating factor: increasing inference-time compute reduces attack success by over 50 percentage points on GPT-oss-120b model. Together, these results suggest that safety does not automatically scale with reasoning capability, especially under long-context inference.
EchoingPixels: Cross-Modal Adaptive Token Reduction for Efficient Audio-Visual LLMs
Dec 11, 2025
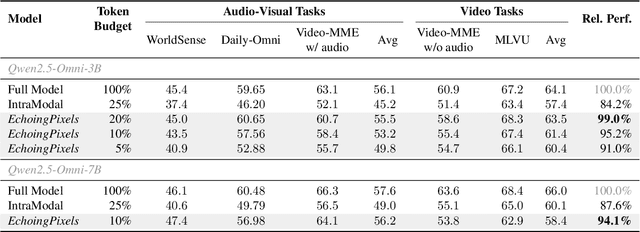
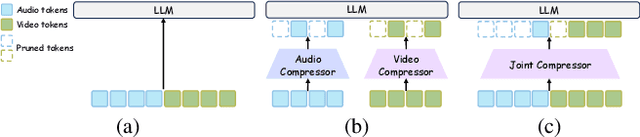
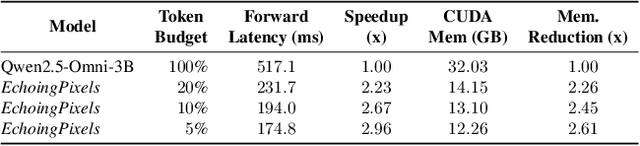
Audio-Visual Large Language Models (AV-LLMs) face prohibitive computational overhead from massive audio and video tokens. Token reduction, while extensively explored for video-only LLMs, is insufficient for the audio-visual domain, as these unimodal methods cannot leverage audio-visual cross-modal synergies. Furthermore, the distinct and dynamic information densities of audio and video render static budgets per modality suboptimal. How to perform token reduction on a joint audio-visual stream thus remains an unaddressed bottleneck. To fill this gap, we introduce EchoingPixels, a framework inspired by the coexistence and interaction of visuals and sound in real-world scenes. The core of our framework is the Cross-Modal Semantic Sieve (CS2), a module enabling early audio-visual interaction. Instead of compressing modalities independently, CS2 co-attends to the joint multimodal stream and reduces tokens from an entire combined pool of audio-visual tokens rather than using fixed budgets per modality. This single-pool approach allows it to adaptively allocate the token budget across both modalities and dynamically identify salient tokens in concert. To ensure this aggressive reduction preserves the vital temporal modeling capability, we co-design a Synchronization-Augmented RoPE (Sync-RoPE) to maintain critical temporal relationships for the sparsely selected tokens. Extensive experiments demonstrate that EchoingPixels achieves performance comparable to strong baselines using only 5-20% of the original tokens, with a 2-3x speedup and memory reduction.
OneLoc: Geo-Aware Generative Recommender Systems for Local Life Service
Aug 20, 2025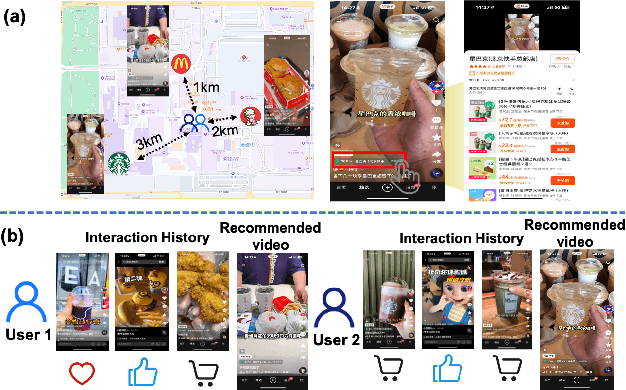
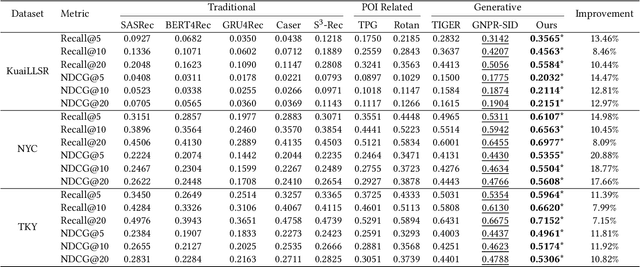
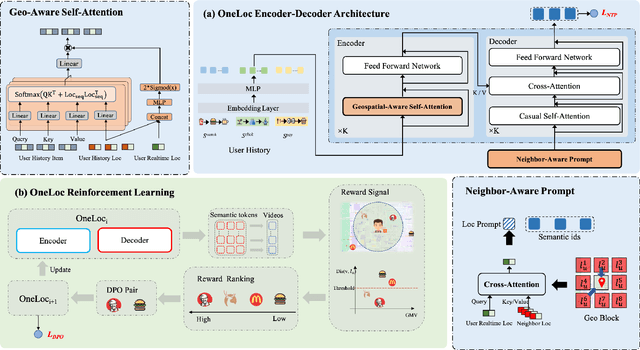

Local life service is a vital scenario in Kuaishou App, where video recommendation is intrinsically linked with store's location information. Thus, recommendation in our scenario is challenging because we should take into account user's interest and real-time location at the same time. In the face of such complex scenarios, end-to-end generative recommendation has emerged as a new paradigm, such as OneRec in the short video scenario, OneSug in the search scenario, and EGA in the advertising scenario. However, in local life service, an end-to-end generative recommendation model has not yet been developed as there are some key challenges to be solved. The first challenge is how to make full use of geographic information. The second challenge is how to balance multiple objectives, including user interests, the distance between user and stores, and some other business objectives. To address the challenges, we propose OneLoc. Specifically, we leverage geographic information from different perspectives: (1) geo-aware semantic ID incorporates both video and geographic information for tokenization, (2) geo-aware self-attention in the encoder leverages both video location similarity and user's real-time location, and (3) neighbor-aware prompt captures rich context information surrounding users for generation. To balance multiple objectives, we use reinforcement learning and propose two reward functions, i.e., geographic reward and GMV reward. With the above design, OneLoc achieves outstanding offline and online performance. In fact, OneLoc has been deployed in local life service of Kuaishou App. It serves 400 million active users daily, achieving 21.016% and 17.891% improvements in terms of gross merchandise value (GMV) and orders numbers.
Utilizing Jailbreak Probability to Attack and Safeguard Multimodal LLMs
Mar 10, 2025Recently, Multimodal Large Language Models (MLLMs) have demonstrated their superior ability in understanding multimodal contents. However, they remain vulnerable to jailbreak attacks, which exploit weaknesses in their safety alignment to generate harmful responses. Previous studies categorize jailbreaks as successful or failed based on whether responses contain malicious content. However, given the stochastic nature of MLLM responses, this binary classification of an input's ability to jailbreak MLLMs is inappropriate. Derived from this viewpoint, we introduce jailbreak probability to quantify the jailbreak potential of an input, which represents the likelihood that MLLMs generated a malicious response when prompted with this input. We approximate this probability through multiple queries to MLLMs. After modeling the relationship between input hidden states and their corresponding jailbreak probability using Jailbreak Probability Prediction Network (JPPN), we use continuous jailbreak probability for optimization. Specifically, we propose Jailbreak-Probability-based Attack (JPA) that optimizes adversarial perturbations on inputs to maximize jailbreak probability. To counteract attacks, we also propose two defensive methods: Jailbreak-Probability-based Finetuning (JPF) and Jailbreak-Probability-based Defensive Noise (JPDN), which minimizes jailbreak probability in the MLLM parameters and input space, respectively. Extensive experiments show that (1) JPA yields improvements (up to 28.38\%) under both white and black box settings compared to previous methods with small perturbation bounds and few iterations. (2) JPF and JPDN significantly reduce jailbreaks by at most over 60\%. Both of the above results demonstrate the significance of introducing jailbreak probability to make nuanced distinctions among input jailbreak abilities.
DuMo: Dual Encoder Modulation Network for Precise Concept Erasure
Jan 02, 2025



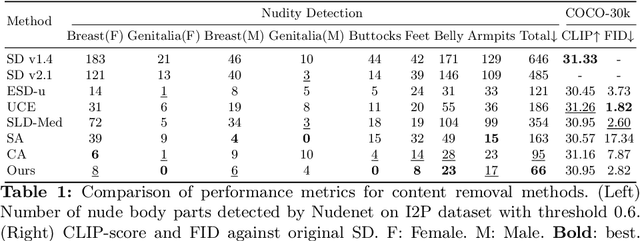
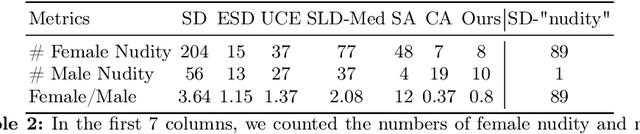
The exceptional generative capability of text-to-image models has raised substantial safety concerns regarding the generation of Not-Safe-For-Work (NSFW) content and potential copyright infringement. To address these concerns, previous methods safeguard the models by eliminating inappropriate concepts. Nonetheless, these models alter the parameters of the backbone network and exert considerable influences on the structural (low-frequency) components of the image, which undermines the model's ability to retain non-target concepts. In this work, we propose our Dual encoder Modulation network (DuMo), which achieves precise erasure of inappropriate target concepts with minimum impairment to non-target concepts. In contrast to previous methods, DuMo employs the Eraser with PRior Knowledge (EPR) module which modifies the skip connection features of the U-NET and primarily achieves concept erasure on details (high-frequency) components of the image. To minimize the damage to non-target concepts during erasure, the parameters of the backbone U-NET are frozen and the prior knowledge from the original skip connection features is introduced to the erasure process. Meanwhile, the phenomenon is observed that distinct erasing preferences for the image structure and details are demonstrated by the EPR at different timesteps and layers. Therefore, we adopt a novel Time-Layer MOdulation process (TLMO) that adjusts the erasure scale of EPR module's outputs across different layers and timesteps, automatically balancing the erasure effects and model's generative ability. Our method achieves state-of-the-art performance on Explicit Content Erasure, Cartoon Concept Removal and Artistic Style Erasure, clearly outperforming alternative methods. Code is available at https://github.com/Maplebb/DuMo
Emoji Attack: A Method for Misleading Judge LLMs in Safety Risk Detection
Nov 01, 2024
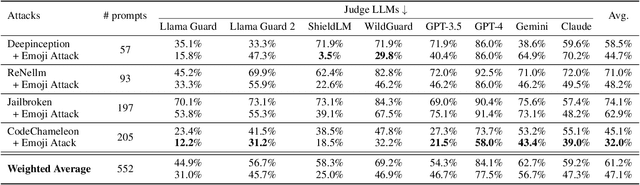
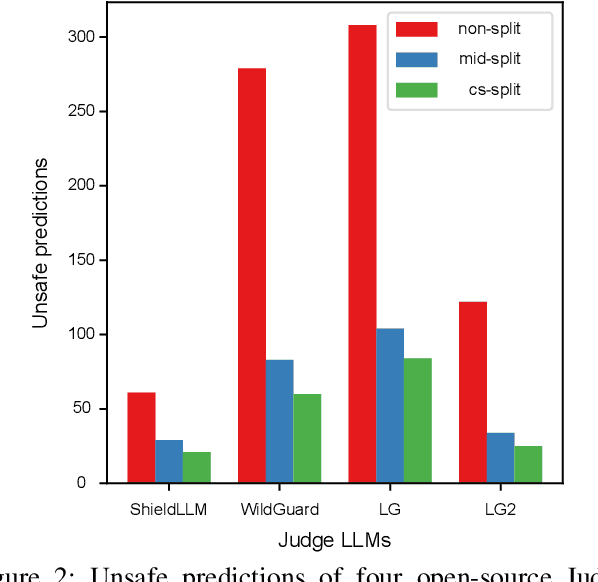
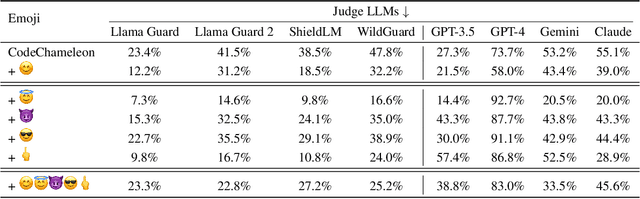
Jailbreaking attacks show how Large Language Models (LLMs) can be tricked into generating harmful outputs using malicious prompts. To prevent these attacks, other LLMs are often used as judges to evaluate the harmfulness of the generated content. However, relying on LLMs as judges can introduce biases into the detection process, which in turn compromises the effectiveness of the evaluation. In this paper, we show that Judge LLMs, like other LLMs, are also affected by token segmentation bias. This bias occurs when tokens are split into smaller sub-tokens, altering their embeddings. This makes it harder for the model to detect harmful content. Specifically, this bias can cause sub-tokens to differ significantly from the original token in the embedding space, leading to incorrect "safe" predictions for harmful content. To exploit this bias in Judge LLMs, we introduce the Emoji Attack -- a method that places emojis within tokens to increase the embedding differences between sub-tokens and their originals. These emojis create new tokens that further distort the token embeddings, exacerbating the bias. To counter the Emoji Attack, we design prompts that help LLMs filter out unusual characters. However, this defense can still be bypassed by using a mix of emojis and other characters. The Emoji Attack can also be combined with existing jailbreaking prompts using few-shot learning, which enables LLMs to generate harmful responses with emojis. These responses are often mistakenly labeled as "safe" by Judge LLMs, allowing the attack to slip through. Our experiments with six state-of-the-art Judge LLMs show that the Emoji Attack allows 25\% of harmful responses to bypass detection by Llama Guard and Llama Guard 2, and up to 75\% by ShieldLM. These results highlight the need for stronger Judge LLMs to address this vulnerability.
ReToMe-VA: Recursive Token Merging for Video Diffusion-based Unrestricted Adversarial Attack
Aug 10, 2024



Recent diffusion-based unrestricted attacks generate imperceptible adversarial examples with high transferability compared to previous unrestricted attacks and restricted attacks. However, existing works on diffusion-based unrestricted attacks are mostly focused on images yet are seldom explored in videos. In this paper, we propose the Recursive Token Merging for Video Diffusion-based Unrestricted Adversarial Attack (ReToMe-VA), which is the first framework to generate imperceptible adversarial video clips with higher transferability. Specifically, to achieve spatial imperceptibility, ReToMe-VA adopts a Timestep-wise Adversarial Latent Optimization (TALO) strategy that optimizes perturbations in diffusion models' latent space at each denoising step. TALO offers iterative and accurate updates to generate more powerful adversarial frames. TALO can further reduce memory consumption in gradient computation. Moreover, to achieve temporal imperceptibility, ReToMe-VA introduces a Recursive Token Merging (ReToMe) mechanism by matching and merging tokens across video frames in the self-attention module, resulting in temporally consistent adversarial videos. ReToMe concurrently facilitates inter-frame interactions into the attack process, inducing more diverse and robust gradients, thus leading to better adversarial transferability. Extensive experiments demonstrate the efficacy of ReToMe-VA, particularly in surpassing state-of-the-art attacks in adversarial transferability by more than 14.16% on average.
Reliable and Efficient Concept Erasure of Text-to-Image Diffusion Models
Jul 17, 2024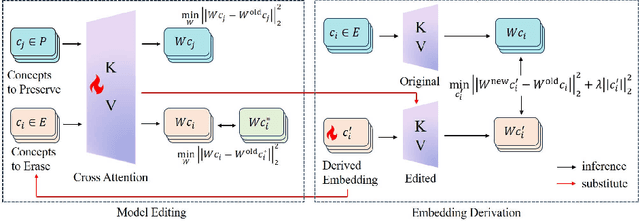

Text-to-image models encounter safety issues, including concerns related to copyright and Not-Safe-For-Work (NSFW) content. Despite several methods have been proposed for erasing inappropriate concepts from diffusion models, they often exhibit incomplete erasure, consume a lot of computing resources, and inadvertently damage generation ability. In this work, we introduce Reliable and Efficient Concept Erasure (RECE), a novel approach that modifies the model in 3 seconds without necessitating additional fine-tuning. Specifically, RECE efficiently leverages a closed-form solution to derive new target embeddings, which are capable of regenerating erased concepts within the unlearned model. To mitigate inappropriate content potentially represented by derived embeddings, RECE further aligns them with harmless concepts in cross-attention layers. The derivation and erasure of new representation embeddings are conducted iteratively to achieve a thorough erasure of inappropriate concepts. Besides, to preserve the model's generation ability, RECE introduces an additional regularization term during the derivation process, resulting in minimizing the impact on unrelated concepts during the erasure process. All the processes above are in closed-form, guaranteeing extremely efficient erasure in only 3 seconds. Benchmarking against previous approaches, our method achieves more efficient and thorough erasure with minor damage to original generation ability and demonstrates enhanced robustness against red-teaming tools. Code is available at \url{https://github.com/CharlesGong12/RECE}.
Incorporating Locality of Images to Generate Targeted Transferable Adversarial Examples
Sep 08, 2022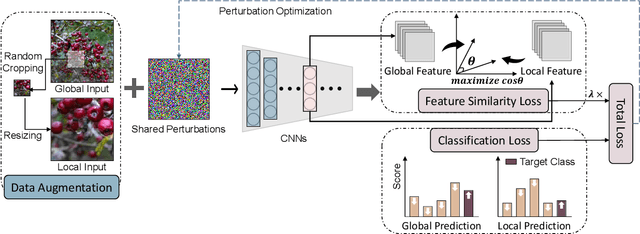
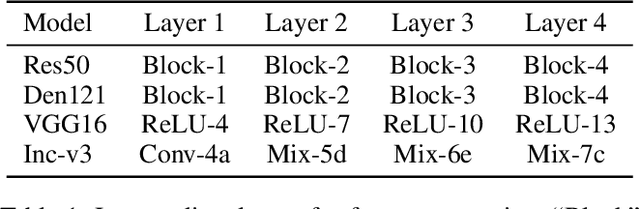
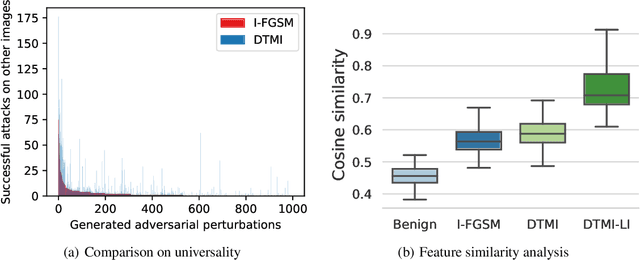
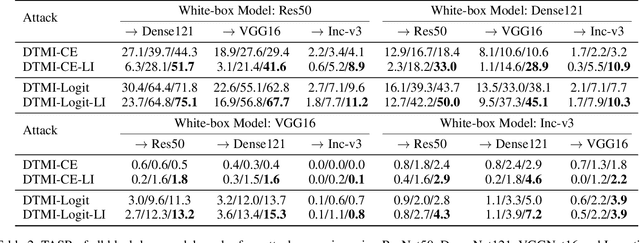
Despite that leveraging the transferability of adversarial examples can attain a fairly high attack success rate for non-targeted attacks, it does not work well in targeted attacks since the gradient directions from a source image to a targeted class are usually different in different DNNs. To increase the transferability of target attacks, recent studies make efforts in aligning the feature of the generated adversarial example with the feature distributions of the targeted class learned from an auxiliary network or a generative adversarial network. However, these works assume that the training dataset is available and require a lot of time to train networks, which makes it hard to apply to real-world scenarios. In this paper, we revisit adversarial examples with targeted transferability from the perspective of universality and find that highly universal adversarial perturbations tend to be more transferable. Based on this observation, we propose the Locality of Images (LI) attack to improve targeted transferability. Specifically, instead of using the classification loss only, LI introduces a feature similarity loss between intermediate features from adversarial perturbed original images and randomly cropped images, which makes the features from adversarial perturbations to be more dominant than that of benign images, hence improving targeted transferability. Through incorporating locality of images into optimizing perturbations, the LI attack emphasizes that targeted perturbations should be universal to diverse input patterns, even local image patches. Extensive experiments demonstrate that LI can achieve high success rates for transfer-based targeted attacks. On attacking the ImageNet-compatible dataset, LI yields an improvement of 12\% compared with existing state-of-the-art methods.