 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Transferable Adversarial Attacks from Images to Videos
Paper and Code
Dec 10, 2021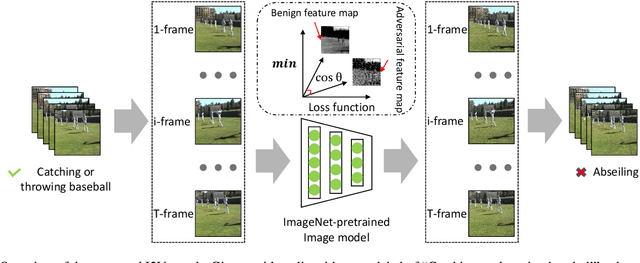
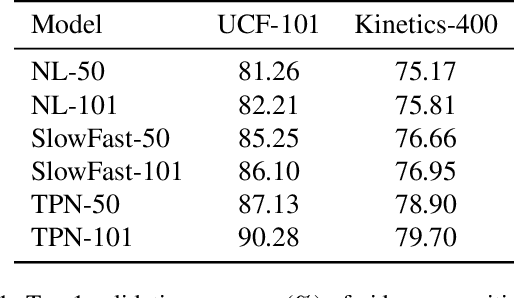
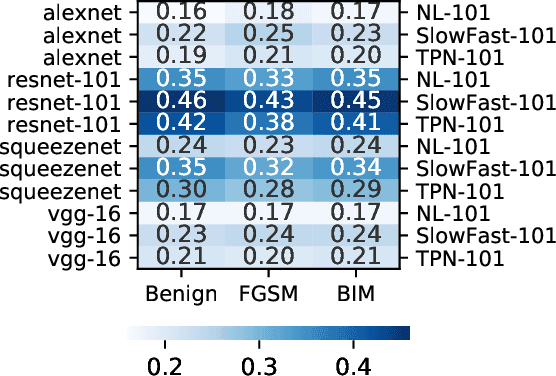

Recent studies have shown that adversarial examples hand-crafted on one white-box model can be used to attack other black-box models. Such cross-model transferability makes it feasible to perform black-box attacks, which has raised security concerns for real-world DNNs applications. Nevertheless, existing works mostly focus on investigating the adversarial transferability across different deep models that share the same modality of input data. The cross-modal transferability of adversarial perturbation has never been explored. This paper investigates the transferability of adversarial perturbation across different modalities, i.e., leveraging adversarial perturbation generated on white-box image models to attack black-box video models. Specifically, motivated by the observation that the low-level feature space between images and video frames are similar, we propose a simple yet effective cross-modal attack method, named as Image To Video (I2V) attack. I2V generates adversarial frames by minimizing the cosine similarity between features of pre-trained image models from adversarial and benign examples, then combines the generated adversarial frames to perform black-box attacks on video recognition models. Extensive experiments demonstrate that I2V can achieve high attack success rates on different black-box video recognition models. On Kinetics-400 and UCF-101, I2V achieves an average attack success rate of 77.88% and 65.68%, respectively, which sheds light on the feasibility of cross-modal adversarial attacks.