 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttacking Video Recognition Models with Bullet-Screen Comments
Paper and Code
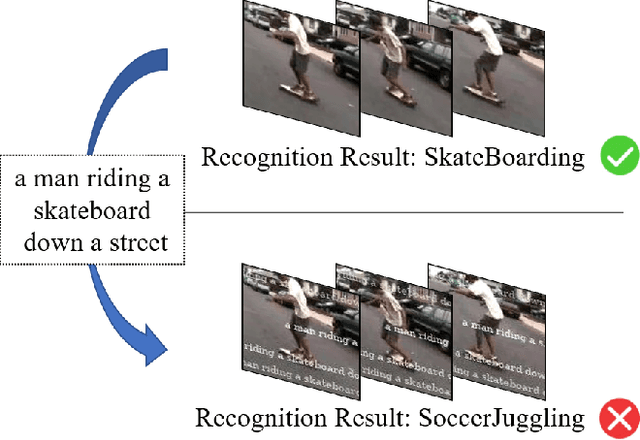

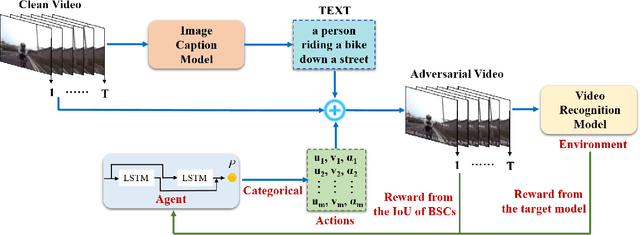
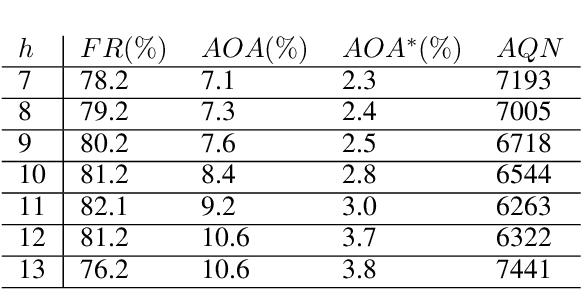
Recent research has demonstrated that Deep Neural Networks (DNNs) are vulnerable to adversarial patches which introducing perceptible but localized changes to the input. Nevertheless, existing approaches have focused on generating adversarial patches on images, their counterparts in videos have been less explored. Compared with images, attacking videos is much more challenging as it needs to consider not only spatial cues but also temporal cues. To close this gap, we introduce a novel adversarial attack in this paper, the bullet-screen comment (BSC) attack, which attacks video recognition models with BSCs. Specifically, adversarial BSCs are generated with a Reinforcement Learning (RL) framework, where the environment is set as the target model and the agent plays the role of selecting the position and transparency of each BSC. By continuously querying the target models and receiving feedback, the agent gradually adjusts its selection strategies in order to achieve a high fooling rate with non-overlapping BSCs. As BSCs can be regarded as a kind of meaningful patch, adding it to a clean video will not affect people' s understanding of the video content, nor will arouse people' s suspicion. We conduct extensive experiments to verify the effectiveness of the proposed method. On both UCF-101 and HMDB-51 datasets, our BSC attack method can achieve about 90\% fooling rate when attack three mainstream video recognition models, while only occluding \textless 8\% areas in the video.