 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni-ViGU: Towards Unified Video Generation and Understanding via A Diffusion-Based Video Generator
Apr 09, 2026Unified multimodal models integrating visual understanding and generation face a fundamental challenge: visual generation incurs substantially higher computational costs than understanding, particularly for video. This imbalance motivates us to invert the conventional paradigm: rather than extending understanding-centric MLLMs to support generation, we propose Uni-ViGU, a framework that unifies video generation and understanding by extending a video generator as the foundation. We introduce a unified flow method that performs continuous flow matching for video and discrete flow matching for text within a single process, enabling coherent multimodal generation. We further propose a modality-driven MoE-based framework that augments Transformer blocks with lightweight layers for text generation while preserving generative priors. To repurpose generation knowledge for understanding, we design a bidirectional training mechanism with two stages: Knowledge Recall reconstructs input prompts to leverage learned text-video correspondences, while Capability Refinement fine-tunes on detailed captions to establish discriminative shared representations. Experiments demonstrate that Uni-ViGU achieves competitive performance on both video generation and understanding, validating generation-centric architectures as a scalable path toward unified multimodal intelligence. Project Page and Code: https://fr0zencrane.github.io/uni-vigu-page/.
DiverseDiT: Towards Diverse Representation Learning in Diffusion Transformers
Mar 04, 2026Recent breakthroughs in Diffusion Transformers (DiTs) have revolutionized the field of visual synthesis due to their superior scalability. To facilitate DiTs' capability of capturing meaningful internal representations, recent works such as REPA incorporate external pretrained encoders for representation alignment. However, the underlying mechanisms governing representation learning within DiTs are not well understood. To this end, we first systematically investigate the representation dynamics of DiTs. Through analyzing the evolution and influence of internal representations under various settings, we reveal that representation diversity across blocks is a crucial factor for effective learning. Based on this key insight, we propose DiverseDiT, a novel framework that explicitly promotes representation diversity. DiverseDiT incorporates long residual connections to diversify input representations across blocks and a representation diversity loss to encourage blocks to learn distinct features. Extensive experiments on ImageNet 256x256 and 512x512 demonstrate that our DiverseDiT yields consistent performance gains and convergence acceleration when applied to different backbones with various sizes, even when tested on the challenging one-step generation setting. Furthermore, we show that DiverseDiT is complementary to existing representation learning techniques, leading to further performance gains. Our work provides valuable insights into the representation learning dynamics of DiTs and offers a practical approach for enhancing their performance.
Diff-Aid: Inference-time Adaptive Interaction Denoising for Rectified Text-to-Image Generation
Feb 14, 2026Recent text-to-image (T2I) diffusion models have achieved remarkable advancement, yet faithfully following complex textual descriptions remains challenging due to insufficient interactions between textual and visual features. Prior approaches enhance such interactions via architectural design or handcrafted textual condition weighting, but lack flexibility and overlook the dynamic interactions across different blocks and denoising stages. To provide a more flexible and efficient solution to this problem, we propose Diff-Aid, a lightweight inference-time method that adaptively adjusts per-token text and image interactions across transformer blocks and denoising timesteps. Beyond improving generation quality, Diff-Aid yields interpretable modulation patterns that reveal how different blocks, timesteps, and textual tokens contribute to semantic alignment during denoising. As a plug-and-play module, Diff-Aid can be seamlessly integrated into downstream applications for further improvement, including style LoRAs, controllable generation, and zero-shot editing. Experiments on strong baselines (SD 3.5 and FLUX) demonstrate consistent improvements in prompt adherence, visual quality, and human preference across various metrics. Our code and models will be released.
Omni-Video 2: Scaling MLLM-Conditioned Diffusion for Unified Video Generation and Editing
Feb 09, 2026We present Omni-Video 2, a scalable and computationally efficient model that connects pretrained multimodal large-language models (MLLMs) with video diffusion models for unified video generation and editing. Our key idea is to exploit the understanding and reasoning capabilities of MLLMs to produce explicit target captions to interpret user instructions. In this way, the rich contextual representations from the understanding model are directly used to guide the generative process, thereby improving performance on complex and compositional editing. Moreover, a lightweight adapter is developed to inject multimodal conditional tokens into pretrained text-to-video diffusion models, allowing maximum reuse of their powerful generative priors in a parameter-efficient manner. Benefiting from these designs, we scale up Omni-Video 2 to a 14B video diffusion model on meticulously curated training data with quality, supporting high quality text-to-video generation and various video editing tasks such as object removal, addition, background change, complex motion editing, \emph{etc.} We evaluate the performance of Omni-Video 2 on the FiVE benchmark for fine-grained video editing and the VBench benchmark for text-to-video generation. The results demonstrate its superior ability to follow complex compositional instructions in video editing, while also achieving competitive or superior quality in video generation tasks.
Unraveling MMDiT Blocks: Training-free Analysis and Enhancement of Text-conditioned Diffusion
Jan 05, 2026Recent breakthroughs of transformer-based diffusion models, particularly with Multimodal Diffusion Transformers (MMDiT) driven models like FLUX and Qwen Image, have facilitated thrilling experiences in text-to-image generation and editing. To understand the internal mechanism of MMDiT-based models, existing methods tried to analyze the effect of specific components like positional encoding and attention layers. Yet, a comprehensive understanding of how different blocks and their interactions with textual conditions contribute to the synthesis process remains elusive. In this paper, we first develop a systematic pipeline to comprehensively investigate each block's functionality by removing, disabling and enhancing textual hidden-states at corresponding blocks. Our analysis reveals that 1) semantic information appears in earlier blocks and finer details are rendered in later blocks, 2) removing specific blocks is usually less disruptive than disabling text conditions, and 3) enhancing textual conditions in selective blocks improves semantic attributes. Building on these observations, we further propose novel training-free strategies for improved text alignment, precise editing, and acceleration. Extensive experiments demonstrated that our method outperforms various baselines and remains flexible across text-to-image generation, image editing, and inference acceleration. Our method improves T2I-Combench++ from 56.92% to 63.00% and GenEval from 66.42% to 71.63% on SD3.5, without sacrificing synthesis quality. These results advance understanding of MMDiT models and provide valuable insights to unlock new possibilities for further improvements.
A unified multimodal understanding and generation model for cross-disciplinary scientific research
Jan 04, 2026Scientific discovery increasingly relies on integrating heterogeneous, high-dimensional data across disciplines nowadays. While AI models have achieved notable success across various scientific domains, they typically remain domain-specific or lack the capability of simultaneously understanding and generating multimodal scientific data, particularly for high-dimensional data. Yet, many pressing global challenges and scientific problems are inherently cross-disciplinary and require coordinated progress across multiple fields. Here, we present FuXi-Uni, a native unified multimodal model for scientific understanding and high-fidelity generation across scientific domains within a single architecture. Specifically, FuXi-Uni aligns cross-disciplinary scientific tokens within natural language tokens and employs science decoder to reconstruct scientific tokens, thereby supporting both natural language conversation and scientific numerical prediction. Empirically, we validate FuXi-Uni in Earth science and Biomedicine. In Earth system modeling, the model supports global weather forecasting, tropical cyclone (TC) forecast editing, and spatial downscaling driven by only language instructions. FuXi-Uni generates 10-day global forecasts at 0.25° resolution that outperform the SOTA physical forecasting system. It shows superior performance for both TC track and intensity prediction relative to the SOTA physical model, and generates high-resolution regional weather fields that surpass standard interpolation baselines. Regarding biomedicine, FuXi-Uni outperforms leading multimodal large language models on multiple biomedical visual question answering benchmarks. By unifying heterogeneous scientific modalities within a native shared latent space while maintaining strong domain-specific performance, FuXi-Uni provides a step forward more general-purpose, multimodal scientific models.
Uni-cot: Towards Unified Chain-of-Thought Reasoning Across Text and Vision
Aug 07, 2025
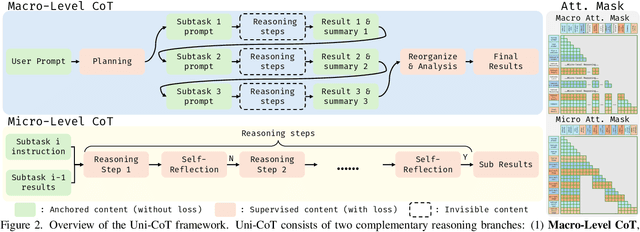

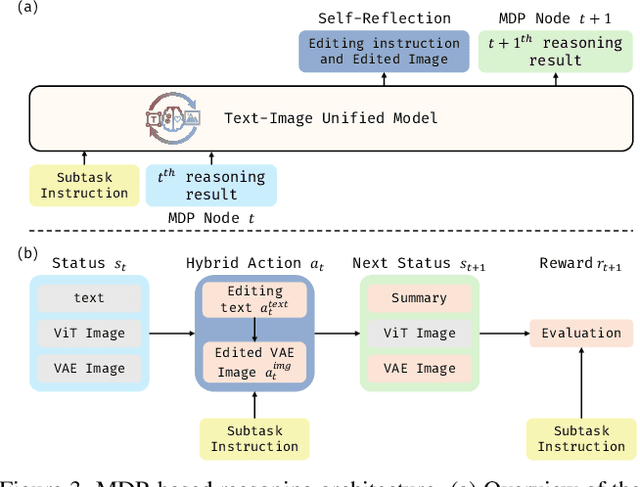
Chain-of-Thought (CoT) reasoning has been widely adopted to enhance Large Language Models (LLMs) by decomposing complex tasks into simpler, sequential subtasks. However, extending CoT to vision-language reasoning tasks remains challenging, as it often requires interpreting transitions of visual states to support reasoning. Existing methods often struggle with this due to limited capacity of modeling visual state transitions or incoherent visual trajectories caused by fragmented architectures. To overcome these limitations, we propose Uni-CoT, a Unified Chain-of-Thought framework that enables coherent and grounded multimodal reasoning within a single unified model. The key idea is to leverage a model capable of both image understanding and generation to reason over visual content and model evolving visual states. However, empowering a unified model to achieve that is non-trivial, given the high computational cost and the burden of training. To address this, Uni-CoT introduces a novel two-level reasoning paradigm: A Macro-Level CoT for high-level task planning and A Micro-Level CoT for subtask execution. This design significantly reduces the computational overhead. Furthermore, we introduce a structured training paradigm that combines interleaved image-text supervision for macro-level CoT with multi-task objectives for micro-level CoT. Together, these innovations allow Uni-CoT to perform scalable and coherent multi-modal reasoning. Furthermore, thanks to our design, all experiments can be efficiently completed using only 8 A100 GPUs with 80GB VRAM each. Experimental results on reasoning-driven image generation benchmark (WISE) and editing benchmarks (RISE and KRIS) indicates that Uni-CoT demonstrates SOTA performance and strong generalization, establishing Uni-CoT as a promising solution for multi-modal reasoning. Project Page and Code: https://sais-fuxi.github.io/projects/uni-cot/
Omni-Video: Democratizing Unified Video Understanding and Generation
Jul 09, 2025Notable breakthroughs in unified understanding and generation modeling have led to remarkable advancements in image understanding, reasoning, production and editing, yet current foundational models predominantly focus on processing images, creating a gap in the development of unified models for video understanding and generation. This report presents Omni-Video, an efficient and effective unified framework for video understanding, generation, as well as instruction-based editing. Our key insight is to teach existing multimodal large language models (MLLMs) to produce continuous visual clues that are used as the input of diffusion decoders, which produce high-quality videos conditioned on these visual clues. To fully unlock the potential of our system for unified video modeling, we integrate several technical improvements: 1) a lightweight architectural design that respectively attaches a vision head on the top of MLLMs and a adapter before the input of diffusion decoders, the former produce visual tokens for the latter, which adapts these visual tokens to the conditional space of diffusion decoders; and 2) an efficient multi-stage training scheme that facilitates a fast connection between MLLMs and diffusion decoders with limited data and computational resources. We empirically demonstrate that our model exhibits satisfactory generalization abilities across video generation, editing and understanding tasks.
SDPO: Importance-Sampled Direct Preference Optimization for Stable Diffusion Training
May 28, 2025
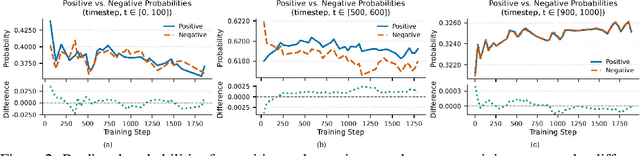
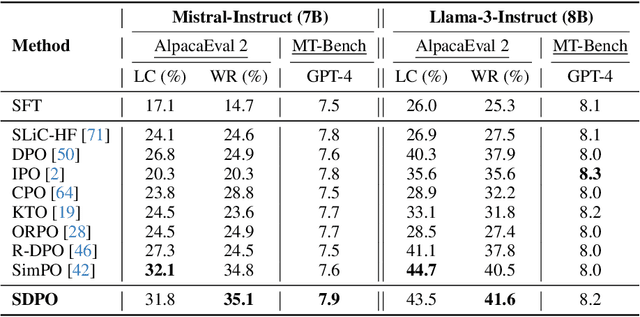
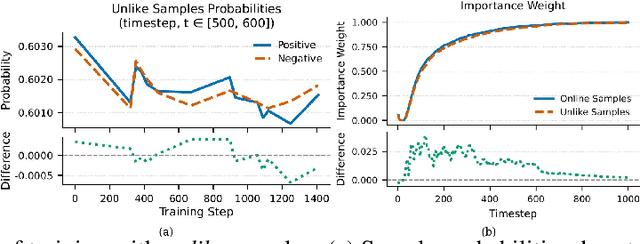
Preference learning has become a central technique for aligning generative models with human expectations. Recently, it has been extended to diffusion models through methods like Direct Preference Optimization (DPO). However, existing approaches such as Diffusion-DPO suffer from two key challenges: timestep-dependent instability, caused by a mismatch between the reverse and forward diffusion processes and by high gradient variance in early noisy timesteps, and off-policy bias arising from the mismatch between optimization and data collection policies. We begin by analyzing the reverse diffusion trajectory and observe that instability primarily occurs at early timesteps with low importance weights. To address these issues, we first propose DPO-C\&M, a practical strategy that improves stability by clipping and masking uninformative timesteps while partially mitigating off-policy bias. Building on this, we introduce SDPO (Importance-Sampled Direct Preference Optimization), a principled framework that incorporates importance sampling into the objective to fully correct for off-policy bias and emphasize informative updates during the diffusion process. Experiments on CogVideoX-2B, CogVideoX-5B, and Wan2.1-1.3B demonstrate that both methods outperform standard Diffusion-DPO, with SDPO achieving superior VBench scores, human preference alignment, and training robustness. These results highlight the importance of timestep-aware, distribution-corrected optimization in diffusion-based preference learning.
Cockatiel: Ensembling Synthetic and Human Preferenced Training for Detailed Video Caption
Mar 12, 2025



Video Detailed Captioning (VDC) is a crucial task for vision-language bridging, enabling fine-grained descriptions of complex video content. In this paper, we first comprehensively benchmark current state-of-the-art approaches and systematically identified two critical limitations: biased capability towards specific captioning aspect and misalignment with human preferences. To address these deficiencies, we propose Cockatiel, a novel three-stage training pipeline that ensembles synthetic and human-aligned training for improving VDC performance. In the first stage, we derive a scorer from a meticulously annotated dataset to select synthetic captions high-performing on certain fine-grained video-caption alignment and human-preferred while disregarding others. Then, we train Cockatiel-13B, using this curated dataset to infuse it with assembled model strengths and human preferences. Finally, we further distill Cockatiel-8B from Cockatiel-13B for the ease of usage. Extensive quantitative and qualitative experiments reflect the effectiveness of our method, as we not only set new state-of-the-art performance on VDCSCORE in a dimension-balanced way but also surpass leading alternatives on human preference by a large margin as depicted by the human evaluation results.