 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQL-ASTRA: Alleviating Sparse Feedback in Agentic SQL via Column-Set Matching and Trajectory Aggregation
Mar 17, 2026Agentic Reinforcement Learning (RL) shows promise for complex tasks, but Text-to-SQL remains mostly restricted to single-turn paradigms. A primary bottleneck is the credit assignment problem. In traditional paradigms, rewards are determined solely by the final-turn feedback, which ignores the intermediate process and leads to ambiguous credit evaluation. To address this, we propose Agentic SQL, a framework featuring a universal two-tiered reward mechanism designed to provide effective trajectory-level evaluation and dense step-level signals. First, we introduce Aggregated Trajectory Reward (ATR) to resolve multi-turn credit assignment. Using an asymmetric transition matrix, ATR aggregates process-oriented scores to incentivize continuous improvement. Leveraging Lyapunov stability theory, we prove ATR acts as an energy dissipation operator, guaranteeing a cycle-free policy and monotonic convergence. Second, Column-Set Matching Reward (CSMR) provides immediate step-level rewards to mitigate sparsity. By executing queries at each turn, CSMR converts binary (0/1) feedback into dense [0, 1] signals based on partial correctness. Evaluations on BIRD show a 5% gain over binary-reward GRPO. Notably, our approach outperforms SOTA Arctic-Text2SQL-R1-7B on BIRD and Spider 2.0 using identical models, propelling Text-to-SQL toward a robust multi-turn agent paradigm.
DyJR: Preserving Diversity in Reinforcement Learning with Verifiable Rewards via Dynamic Jensen-Shannon Replay
Mar 17, 2026While Reinforcement Learning (RL) enhances Large Language Model reasoning, on-policy algorithms like GRPO are sample-inefficient as they discard past rollouts. Existing experience replay methods address this by reusing accurate samples for direct policy updates, but this often incurs high computational costs and causes mode collapse via overfitting. We argue that historical data should prioritize sustaining diversity rather than simply reinforcing accuracy. To this end, we propose Dynamic Jensen-Shannon Replay (DyJR), a simple yet effective regularization framework using a dynamic reference distribution from recent trajectories. DyJR introduces two innovations: (1) A Time-Sensitive Dynamic Buffer that uses FIFO and adaptive sizing to retain only temporally proximal samples, synchronizing with model evolution; and (2) Jensen-Shannon Divergence Regularization, which replaces direct gradient updates with a distributional constraint to prevent diversity collapse. Experiments on mathematical reasoning and Text-to-SQL benchmarks demonstrate that DyJR significantly outperforms GRPO as well as baselines such as RLEP and Ex-GRPO, while maintaining training efficiency comparable to the original GRPO. Furthermore, from the perspective of Rank-$k$ token probability evolution, we show that DyJR enhances diversity and mitigates over-reliance on Rank-1 tokens, elucidating how specific sub-modules of DyJR influence the training dynamics.
Equivariant Asynchronous Diffusion: An Adaptive Denoising Schedule for Accelerated Molecular Conformation Generation
Mar 10, 2026Recent 3D molecular generation methods primarily use asynchronous auto-regressive or synchronous diffusion models. While auto-regressive models build molecules sequentially, they're limited by a short horizon and a discrepancy between training and inference. Conversely, synchronous diffusion models denoise all atoms at once, offering a molecule-level horizon but failing to capture the causal relationships inherent in hierarchical molecular structures. We introduce Equivariant Asynchronous Diffusion (EAD) to overcome these limitations. EAD is a novel diffusion model that combines the strengths of both approaches: it uses an asynchronous denoising schedule to better capture molecular hierarchy while maintaining a molecule-level horizon. Since these relationships are often complex, we propose a dynamic scheduling mechanism to adaptively determine the denoising timestep. Experimental results show that EAD achieves state-of-the-art performance in 3D molecular generation.
Youtu-Agent: Scaling Agent Productivity with Automated Generation and Hybrid Policy Optimization
Dec 31, 2025Existing Large Language Model (LLM) agent frameworks face two significant challenges: high configuration costs and static capabilities. Building a high-quality agent often requires extensive manual effort in tool integration and prompt engineering, while deployed agents struggle to adapt to dynamic environments without expensive fine-tuning. To address these issues, we propose \textbf{Youtu-Agent}, a modular framework designed for the automated generation and continuous evolution of LLM agents. Youtu-Agent features a structured configuration system that decouples execution environments, toolkits, and context management, enabling flexible reuse and automated synthesis. We introduce two generation paradigms: a \textbf{Workflow} mode for standard tasks and a \textbf{Meta-Agent} mode for complex, non-standard requirements, capable of automatically generating tool code, prompts, and configurations. Furthermore, Youtu-Agent establishes a hybrid policy optimization system: (1) an \textbf{Agent Practice} module that enables agents to accumulate experience and improve performance through in-context optimization without parameter updates; and (2) an \textbf{Agent RL} module that integrates with distributed training frameworks to enable scalable and stable reinforcement learning of any Youtu-Agents in an end-to-end, large-scale manner. Experiments demonstrate that Youtu-Agent achieves state-of-the-art performance on WebWalkerQA (71.47\%) and GAIA (72.8\%) using open-weight models. Our automated generation pipeline achieves over 81\% tool synthesis success rate, while the Practice module improves performance on AIME 2024/2025 by +2.7\% and +5.4\% respectively. Moreover, our Agent RL training achieves 40\% speedup with steady performance improvement on 7B LLMs, enhancing coding/reasoning and searching capabilities respectively up to 35\% and 21\% on Maths and general/multi-hop QA benchmarks.
The Choice of Divergence: A Neglected Key to Mitigating Diversity Collapse in Reinforcement Learning with Verifiable Reward
Sep 09, 2025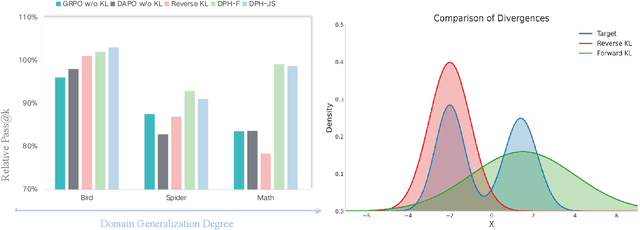

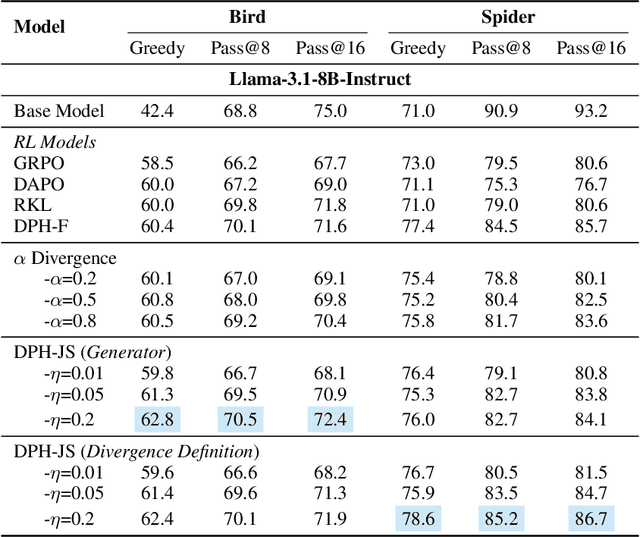
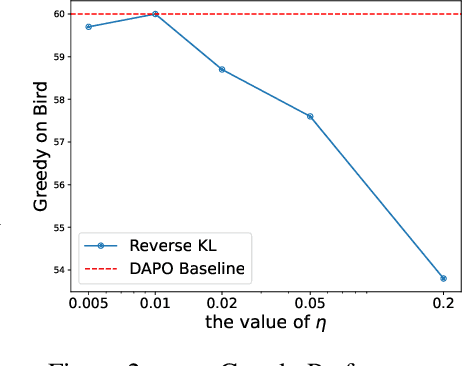
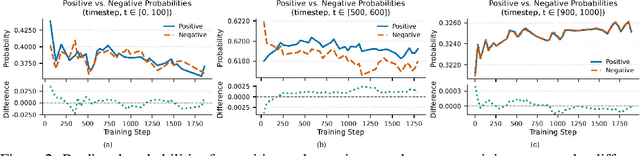
A central paradox in fine-tuning Large Language Models (LLMs) with Reinforcement Learning with Verifiable Reward (RLVR) is the frequent degradation of multi-attempt performance (Pass@k) despite improvements in single-attempt accuracy (Pass@1). This is often accompanied by catastrophic forgetting, where models lose previously acquired skills. While various methods have been proposed, the choice and function of the divergence term have been surprisingly unexamined as a proactive solution. We argue that standard RLVR objectives -- both those using the mode-seeking reverse KL-divergence and those forgoing a divergence term entirely -- lack a crucial mechanism for knowledge retention. The reverse-KL actively accelerates this decay by narrowing the policy, while its absence provides no safeguard against the model drifting from its diverse knowledge base. We propose a fundamental shift in perspective: using the divergence term itself as the solution. Our framework, Diversity-Preserving Hybrid RL (DPH-RL), leverages mass-covering f-divergences (like forward-KL and JS-divergence) to function as a rehearsal mechanism. By continuously referencing the initial policy, this approach forces the model to maintain broad solution coverage. Extensive experiments on math and SQL generation demonstrate that DPH-RL not only resolves the Pass@k degradation but improves both Pass@1 and Pass@k in- and out-of-domain. Additionally, DPH-RL is more training-efficient because it computes f-divergence using generator functions, requiring only sampling from the initial policy and no online reference model. Our work highlights a crucial, overlooked axis for improving RLVR, demonstrating that the proper selection of a divergence measure is a powerful tool for building more general and diverse reasoning models.
SDPO: Importance-Sampled Direct Preference Optimization for Stable Diffusion Training
May 28, 2025
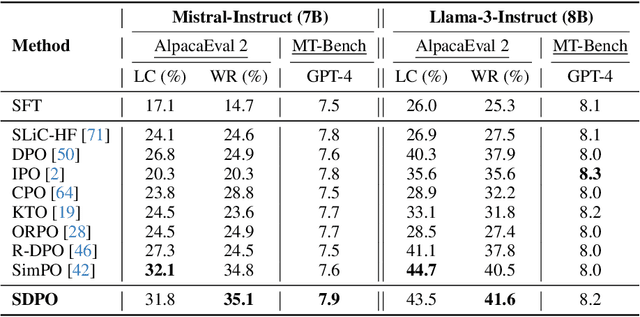
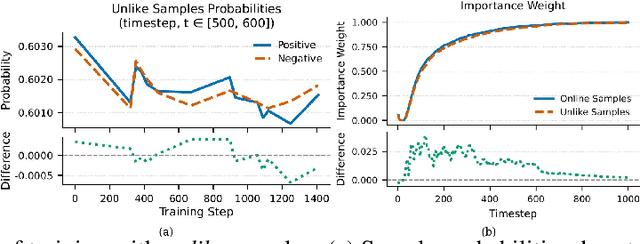
Preference learning has become a central technique for aligning generative models with human expectations. Recently, it has been extended to diffusion models through methods like Direct Preference Optimization (DPO). However, existing approaches such as Diffusion-DPO suffer from two key challenges: timestep-dependent instability, caused by a mismatch between the reverse and forward diffusion processes and by high gradient variance in early noisy timesteps, and off-policy bias arising from the mismatch between optimization and data collection policies. We begin by analyzing the reverse diffusion trajectory and observe that instability primarily occurs at early timesteps with low importance weights. To address these issues, we first propose DPO-C\&M, a practical strategy that improves stability by clipping and masking uninformative timesteps while partially mitigating off-policy bias. Building on this, we introduce SDPO (Importance-Sampled Direct Preference Optimization), a principled framework that incorporates importance sampling into the objective to fully correct for off-policy bias and emphasize informative updates during the diffusion process. Experiments on CogVideoX-2B, CogVideoX-5B, and Wan2.1-1.3B demonstrate that both methods outperform standard Diffusion-DPO, with SDPO achieving superior VBench scores, human preference alignment, and training robustness. These results highlight the importance of timestep-aware, distribution-corrected optimization in diffusion-based preference learning.
ChemHAS: Hierarchical Agent Stacking for Enhancing Chemistry Tools
May 27, 2025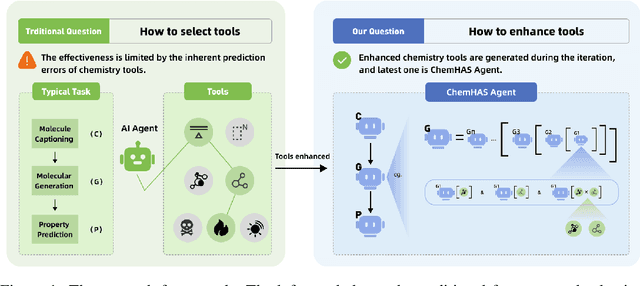
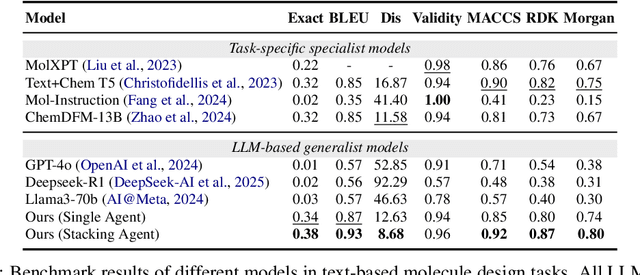
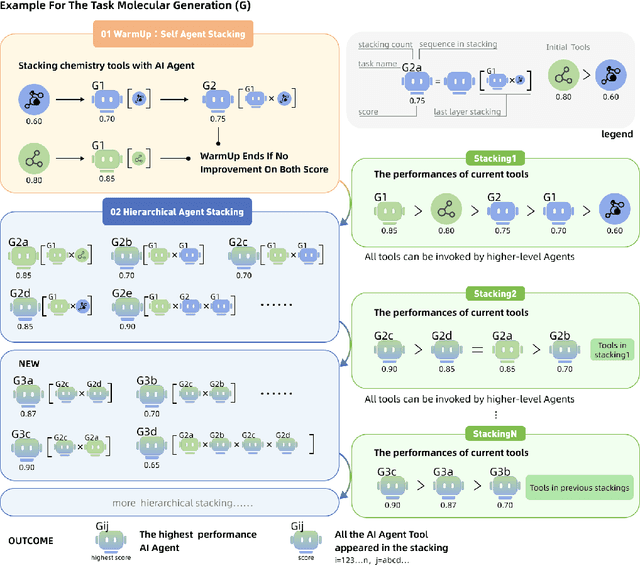
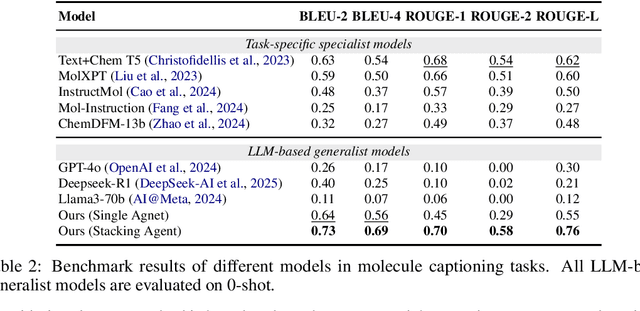
Large Language Model (LLM)-based agents have demonstrated the ability to improve performance in chemistry-related tasks by selecting appropriate tools. However, their effectiveness remains limited by the inherent prediction errors of chemistry tools. In this paper, we take a step further by exploring how LLMbased agents can, in turn, be leveraged to reduce prediction errors of the tools. To this end, we propose ChemHAS (Chemical Hierarchical Agent Stacking), a simple yet effective method that enhances chemistry tools through optimizing agent-stacking structures from limited data. ChemHAS achieves state-of-the-art performance across four fundamental chemistry tasks, demonstrating that our method can effectively compensate for prediction errors of the tools. Furthermore, we identify and characterize four distinct agent-stacking behaviors, potentially improving interpretability and revealing new possibilities for AI agent applications in scientific research. Our code and dataset are publicly available at https: //anonymous.4open.science/r/ChemHAS-01E4/README.md.
Revisit Non-parametric Two-sample Testing as a Semi-supervised Learning Problem
Nov 30, 2024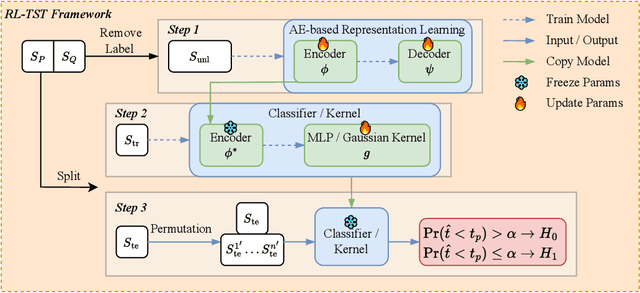

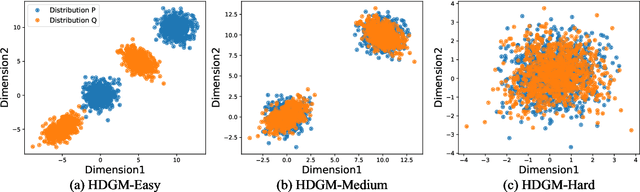
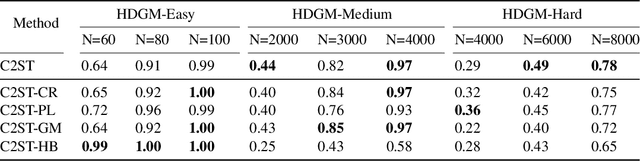
Learning effective data representations is crucial in answering if two samples X and Y are from the same distribution (a.k.a. the non-parametric two-sample testing problem), which can be categorized into: i) learning discriminative representations (DRs) that distinguish between two samples in a supervised-learning paradigm, and ii) learning inherent representations (IRs) focusing on data's inherent features in an unsupervised-learning paradigm. However, both paradigms have issues: learning DRs reduces the data points available for the two-sample testing phase, and learning purely IRs misses discriminative cues. To mitigate both issues, we propose a novel perspective to consider non-parametric two-sample testing as a semi-supervised learning (SSL) problem, introducing the SSL-based Classifier Two-Sample Test (SSL-C2ST) framework. While a straightforward implementation of SSL-C2ST might directly use existing state-of-the-art (SOTA) SSL methods to train a classifier with labeled data (with sample indexes X or Y) and unlabeled data (the remaining ones in the two samples), conventional two-sample testing data often exhibits substantial overlap between samples and violates SSL methods' assumptions, resulting in low test power. Therefore, we propose a two-step approach: first, learn IRs using all data, then fine-tune IRs with only labelled data to learn DRs, which can both utilize information from whole dataset and adapt the discriminative power to the given data. Extensive experiments and theoretical analysis demonstrate that SSL-C2ST outperforms traditional C2ST by effectively leveraging unlabeled data. We also offer a stronger empirically designed test achieving the SOTA performance in many two-sample testing datasets.