 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-informed Deep Mixture-of-Koopmans Vehicle Dynamics Model with Dual-branch Encoder for Distributed Electric-drive Trucks
Mar 18, 2026Advanced autonomous driving systems require accurate vehicle dynamics modeling. However, identifying a precise dynamics model remains challenging due to strong nonlinearities and the coupled longitudinal and lateral dynamic characteristics. Previous research has employed physics-based analytical models or neural networks to construct vehicle dynamics representations. Nevertheless, these approaches often struggle to simultaneously achieve satisfactory performance in terms of system identification efficiency, modeling accuracy, and compatibility with linear control strategies. In this paper, we propose a fully data-driven dynamics modeling method tailored for complex distributed electric-drive trucks (DETs), leveraging Koopman operator theory to represent highly nonlinear dynamics in a lifted linear embedding space. To achieve high-precision modeling, we first propose a novel dual-branch encoder which encodes dynamic states and provides a powerful basis for the proposed Koopman-based methods entitled KODE. A physics-informed supervision mechanism, grounded in the geometric consistency of temporal vehicle motion, is incorporated into the training process to facilitate effective learning of both the encoder and the Koopman operator. Furthermore, to accommodate the diverse driving patterns of DETs, we extend the vanilla Koopman operator to a mixture-of-Koopman operator framework, enhancing modeling capability. Simulations conducted in a high-fidelity TruckSim environment and real-world experiments demonstrate that the proposed approach achieves state-of-the-art performance in long-term dynamics state estimation.
Instructions are all you need: Self-supervised Reinforcement Learning for Instruction Following
Oct 16, 2025Language models often struggle to follow multi-constraint instructions that are crucial for real-world applications. Existing reinforcement learning (RL) approaches suffer from dependency on external supervision and sparse reward signals from multi-constraint tasks. We propose a label-free self-supervised RL framework that eliminates dependency on external supervision by deriving reward signals directly from instructions and generating pseudo-labels for reward model training. Our approach introduces constraint decomposition strategies and efficient constraint-wise binary classification to address sparse reward challenges while maintaining computational efficiency. Experiments show that our approach generalizes well, achieving strong improvements across 3 in-domain and 5 out-of-domain datasets, including challenging agentic and multi-turn instruction following. The data and code are publicly available at https://github.com/Rainier-rq/verl-if
A Lightweight Convolution and Vision Transformer integrated model with Multi-scale Self-attention Mechanism
Aug 23, 2025Vision Transformer (ViT) has prevailed in computer vision tasks due to its strong long-range dependency modelling ability. However, its large model size with high computational cost and weak local feature modeling ability hinder its application in real scenarios. To balance computation efficiency and performance, we propose SAEViT (Sparse-Attention-Efficient-ViT), a lightweight ViT based model with convolution blocks, in this paper to achieve efficient downstream vision tasks. Specifically, SAEViT introduces a Sparsely Aggregated Attention (SAA) module that performs adaptive sparse sampling based on image redundancy and recovers the feature map via deconvolution operation, which significantly reduces the computational complexity of attention operations. In addition, a Channel-Interactive Feed-Forward Network (CIFFN) layer is developed to enhance inter-channel information exchange through feature decomposition and redistribution, mitigating redundancy in traditional feed-forward networks (FNN). Finally, a hierarchical pyramid structure with embedded depth-wise separable convolutional blocks (DWSConv) is devised to further strengthen convolutional features. Extensive experiments on mainstream datasets show that SAEViT achieves Top-1 accuracies of 76.3\% and 79.6\% on the ImageNet-1K classification task with only 0.8 GFLOPs and 1.3 GFLOPs, respectively, demonstrating a lightweight solution for various fundamental vision tasks.
Scalable Multi-Task Reinforcement Learning for Generalizable Spatial Intelligence in Visuomotor Agents
Jul 31, 2025While Reinforcement Learning (RL) has achieved remarkable success in language modeling, its triumph hasn't yet fully translated to visuomotor agents. A primary challenge in RL models is their tendency to overfit specific tasks or environments, thereby hindering the acquisition of generalizable behaviors across diverse settings. This paper provides a preliminary answer to this challenge by demonstrating that RL-finetuned visuomotor agents in Minecraft can achieve zero-shot generalization to unseen worlds. Specifically, we explore RL's potential to enhance generalizable spatial reasoning and interaction capabilities in 3D worlds. To address challenges in multi-task RL representation, we analyze and establish cross-view goal specification as a unified multi-task goal space for visuomotor policies. Furthermore, to overcome the significant bottleneck of manual task design, we propose automated task synthesis within the highly customizable Minecraft environment for large-scale multi-task RL training, and we construct an efficient distributed RL framework to support this. Experimental results show RL significantly boosts interaction success rates by $4\times$ and enables zero-shot generalization of spatial reasoning across diverse environments, including real-world settings. Our findings underscore the immense potential of RL training in 3D simulated environments, especially those amenable to large-scale task generation, for significantly advancing visuomotor agents' spatial reasoning.
ChemHAS: Hierarchical Agent Stacking for Enhancing Chemistry Tools
May 27, 2025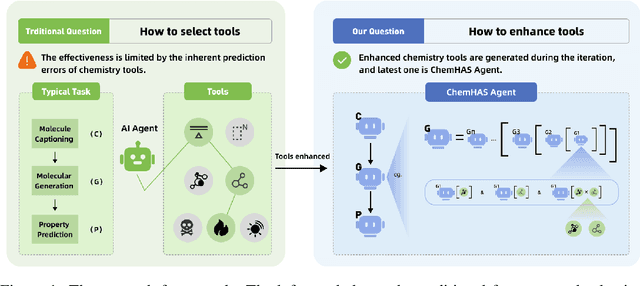
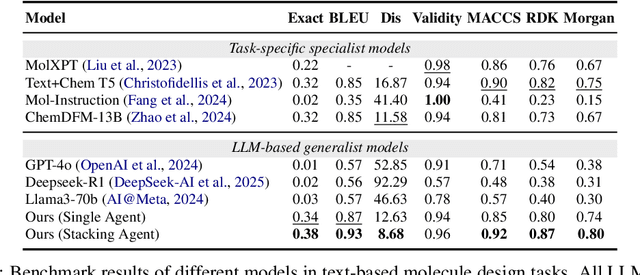
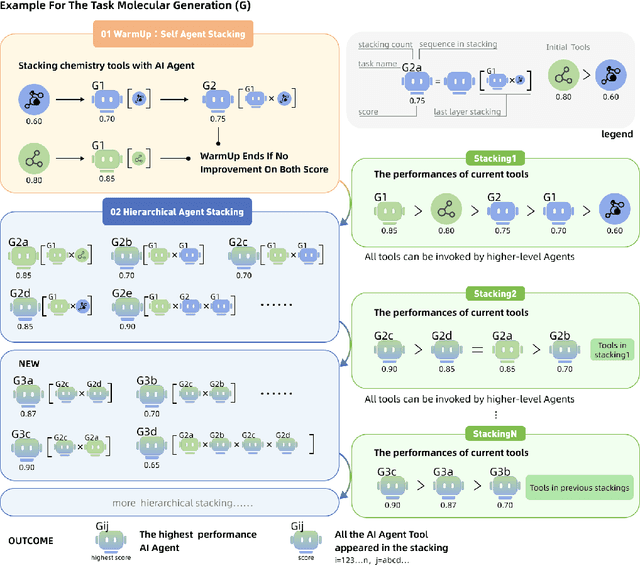
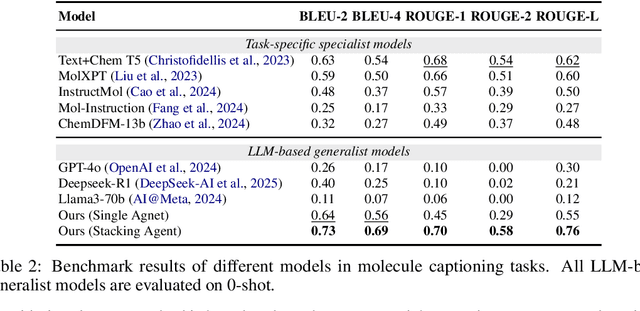
Large Language Model (LLM)-based agents have demonstrated the ability to improve performance in chemistry-related tasks by selecting appropriate tools. However, their effectiveness remains limited by the inherent prediction errors of chemistry tools. In this paper, we take a step further by exploring how LLMbased agents can, in turn, be leveraged to reduce prediction errors of the tools. To this end, we propose ChemHAS (Chemical Hierarchical Agent Stacking), a simple yet effective method that enhances chemistry tools through optimizing agent-stacking structures from limited data. ChemHAS achieves state-of-the-art performance across four fundamental chemistry tasks, demonstrating that our method can effectively compensate for prediction errors of the tools. Furthermore, we identify and characterize four distinct agent-stacking behaviors, potentially improving interpretability and revealing new possibilities for AI agent applications in scientific research. Our code and dataset are publicly available at https: //anonymous.4open.science/r/ChemHAS-01E4/README.md.
TAPIP3D: Tracking Any Point in Persistent 3D Geometry
Apr 20, 2025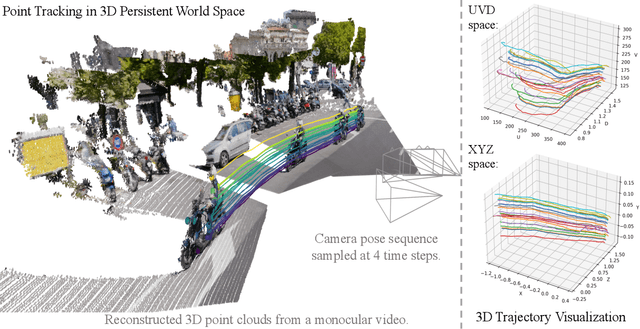



We introduce TAPIP3D, a novel approach for long-term 3D point tracking in monocular RGB and RGB-D videos. TAPIP3D represents videos as camera-stabilized spatio-temporal feature clouds, leveraging depth and camera motion information to lift 2D video features into a 3D world space where camera motion is effectively canceled. TAPIP3D iteratively refines multi-frame 3D motion estimates within this stabilized representation, enabling robust tracking over extended periods. To manage the inherent irregularities of 3D point distributions, we propose a Local Pair Attention mechanism. This 3D contextualization strategy effectively exploits spatial relationships in 3D, forming informative feature neighborhoods for precise 3D trajectory estimation. Our 3D-centric approach significantly outperforms existing 3D point tracking methods and even enhances 2D tracking accuracy compared to conventional 2D pixel trackers when accurate depth is available. It supports inference in both camera coordinates (i.e., unstabilized) and world coordinates, and our results demonstrate that compensating for camera motion improves tracking performance. Our approach replaces the conventional 2D square correlation neighborhoods used in prior 2D and 3D trackers, leading to more robust and accurate results across various 3D point tracking benchmarks. Project Page: https://tapip3d.github.io
Residual Learning towards High-fidelity Vehicle Dynamics Modeling with Transformer
Feb 17, 2025The vehicle dynamics model serves as a vital component of autonomous driving systems, as it describes the temporal changes in vehicle state. In a long period, researchers have made significant endeavors to accurately model vehicle dynamics. Traditional physics-based methods employ mathematical formulae to model vehicle dynamics, but they are unable to adequately describe complex vehicle systems due to the simplifications they entail. Recent advancements in deep learning-based methods have addressed this limitation by directly regressing vehicle dynamics. However, the performance and generalization capabilities still require further enhancement. In this letter, we address these problems by proposing a vehicle dynamics correction system that leverages deep neural networks to correct the state residuals of a physical model instead of directly estimating the states. This system greatly reduces the difficulty of network learning and thus improves the estimation accuracy of vehicle dynamics. Furthermore, we have developed a novel Transformer-based dynamics residual correction network, DyTR. This network implicitly represents state residuals as high-dimensional queries, and iteratively updates the estimated residuals by interacting with dynamics state features. The experiments in simulations demonstrate the proposed system works much better than physics model, and our proposed DyTR model achieves the best performances on dynamics state residual correction task, reducing the state prediction errors of a simple 3 DoF vehicle model by an average of 92.3% and 59.9% in two dataset, respectively.
MSCViT: A Small-size ViT architecture with Multi-Scale Self-Attention Mechanism for Tiny Datasets
Jan 14, 2025



Vision Transformer (ViT) has demonstrated significant potential in various vision tasks due to its strong ability in modelling long-range dependencies. However, such success is largely fueled by training on massive samples. In real applications, the large-scale datasets are not always available, and ViT performs worse than Convolutional Neural Networks (CNNs) if it is only trained on small scale dataset (called tiny dataset), since it requires large amount of training data to ensure its representational capacity. In this paper, a small-size ViT architecture with multi-scale self-attention mechanism and convolution blocks is presented (dubbed MSCViT) to model different scales of attention at each layer. Firstly, we introduced wavelet convolution, which selectively combines the high-frequency components obtained by frequency division with our convolution channel to extract local features. Then, a lightweight multi-head attention module is developed to reduce the number of tokens and computational costs. Finally, the positional encoding (PE) in the backbone is replaced by a local feature extraction module. Compared with the original ViT, it is parameter-efficient and is particularly suitable for tiny datasets. Extensive experiments have been conducted on tiny datasets, in which our model achieves an accuracy of 84.68% on CIFAR-100 with 14.0M parameters and 2.5 GFLOPs, without pre-training on large datasets.
MineStudio: A Streamlined Package for Minecraft AI Agent Development
Dec 25, 2024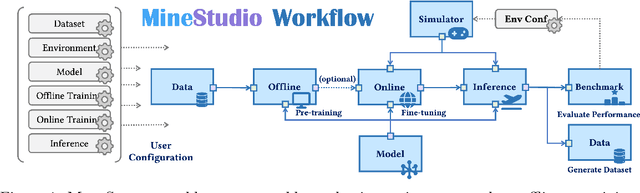
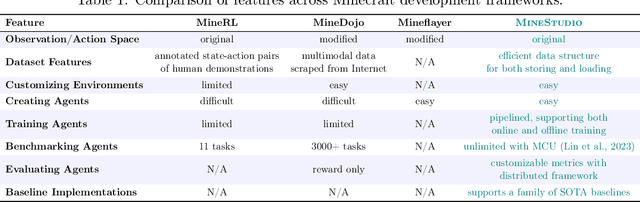
Minecraft has emerged as a valuable testbed for embodied intelligence and sequential decision-making research, yet the development and validation of novel agents remains hindered by significant engineering challenges. This paper presents MineStudio, an open-source software package designed to streamline embodied policy development in Minecraft. MineStudio represents the first comprehensive integration of seven critical engineering components: simulator, data, model, offline pretraining, online finetuning, inference, and benchmark, thereby allowing users to concentrate their efforts on algorithm innovation. We provide a user-friendly API design accompanied by comprehensive documentation and tutorials. The complete codebase is publicly available at https://github.com/CraftJarvis/MineStudio.
MinsStudio: A Streamlined Package for Minecraft AI Agent Development
Dec 24, 2024Minecraft has emerged as a valuable testbed for embodied intelligence and sequential decision-making research, yet the development and validation of novel agents remains hindered by significant engineering challenges. This paper presents MineStudio, an open-source software package designed to streamline embodied policy development in Minecraft. MineStudio represents the first comprehensive integration of seven critical engineering components: simulator, data, model, offline pretraining, online finetuning, inference, and benchmark, thereby allowing users to concentrate their efforts on algorithm innovation. We provide a user-friendly API design accompanied by comprehensive documentation and tutorials. The complete codebase is publicly available at https://github.com/CraftJarvis/MineStudio.