 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointSt3R: Point Tracking through 3D Grounded Correspondence
Oct 30, 2025
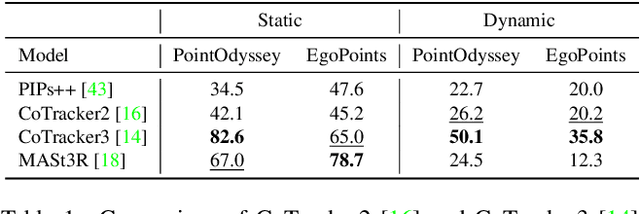
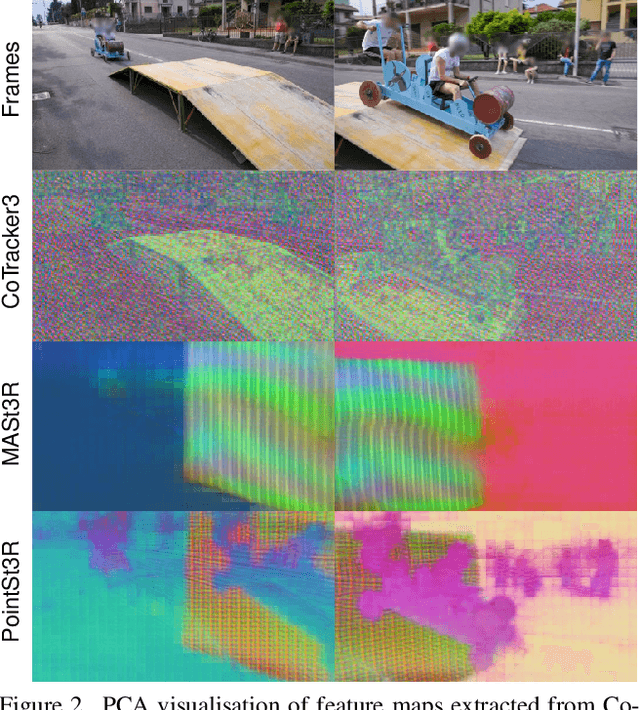
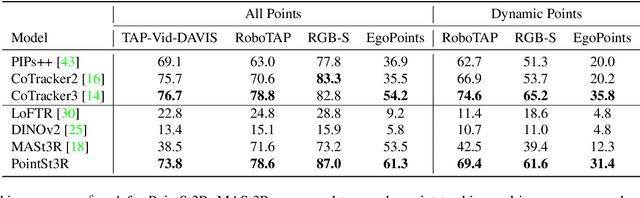
Recent advances in foundational 3D reconstruction models, such as DUSt3R and MASt3R, have shown great potential in 2D and 3D correspondence in static scenes. In this paper, we propose to adapt them for the task of point tracking through 3D grounded correspondence. We first demonstrate that these models are competitive point trackers when focusing on static points, present in current point tracking benchmarks ($+33.5\%$ on EgoPoints vs. CoTracker2). We propose to combine the reconstruction loss with training for dynamic correspondence along with a visibility head, and fine-tuning MASt3R for point tracking using a relatively small amount of synthetic data. Importantly, we only train and evaluate on pairs of frames where one contains the query point, effectively removing any temporal context. Using a mix of dynamic and static point correspondences, we achieve competitive or superior point tracking results on four datasets (e.g. competitive on TAP-Vid-DAVIS 73.8 $\delta_{avg}$ / 85.8\% occlusion acc. for PointSt3R compared to 75.7 / 88.3\% for CoTracker2; and significantly outperform CoTracker3 on EgoPoints 61.3 vs 54.2 and RGB-S 87.0 vs 82.8). We also present results on 3D point tracking along with several ablations on training datasets and percentage of dynamic correspondences.
LookOut: Real-World Humanoid Egocentric Navigation
Aug 20, 2025The ability to predict collision-free future trajectories from egocentric observations is crucial in applications such as humanoid robotics, VR / AR, and assistive navigation. In this work, we introduce the challenging problem of predicting a sequence of future 6D head poses from an egocentric video. In particular, we predict both head translations and rotations to learn the active information-gathering behavior expressed through head-turning events. To solve this task, we propose a framework that reasons over temporally aggregated 3D latent features, which models the geometric and semantic constraints for both the static and dynamic parts of the environment. Motivated by the lack of training data in this space, we further contribute a data collection pipeline using the Project Aria glasses, and present a dataset collected through this approach. Our dataset, dubbed Aria Navigation Dataset (AND), consists of 4 hours of recording of users navigating in real-world scenarios. It includes diverse situations and navigation behaviors, providing a valuable resource for learning real-world egocentric navigation policies. Extensive experiments show that our model learns human-like navigation behaviors such as waiting / slowing down, rerouting, and looking around for traffic while generalizing to unseen environments. Check out our project webpage at https://sites.google.com/stanford.edu/lookout.
AllTracker: Efficient Dense Point Tracking at High Resolution
Jun 08, 2025We introduce AllTracker: a model that estimates long-range point tracks by way of estimating the flow field between a query frame and every other frame of a video. Unlike existing point tracking methods, our approach delivers high-resolution and dense (all-pixel) correspondence fields, which can be visualized as flow maps. Unlike existing optical flow methods, our approach corresponds one frame to hundreds of subsequent frames, rather than just the next frame. We develop a new architecture for this task, blending techniques from existing work in optical flow and point tracking: the model performs iterative inference on low-resolution grids of correspondence estimates, propagating information spatially via 2D convolution layers, and propagating information temporally via pixel-aligned attention layers. The model is fast and parameter-efficient (16 million parameters), and delivers state-of-the-art point tracking accuracy at high resolution (i.e., tracking 768x1024 pixels, on a 40G GPU). A benefit of our design is that we can train on a wider set of datasets, and we find that doing so is crucial for top performance. We provide an extensive ablation study on our architecture details and training recipe, making it clear which details matter most. Our code and model weights are available at https://alltracker.github.io .
Animal Pose Labeling Using General-Purpose Point Trackers
Jun 04, 2025Automatically estimating animal poses from videos is important for studying animal behaviors. Existing methods do not perform reliably since they are trained on datasets that are not comprehensive enough to capture all necessary animal behaviors. However, it is very challenging to collect such datasets due to the large variations in animal morphology. In this paper, we propose an animal pose labeling pipeline that follows a different strategy, i.e. test time optimization. Given a video, we fine-tune a lightweight appearance embedding inside a pre-trained general-purpose point tracker on a sparse set of annotated frames. These annotations can be obtained from human labelers or off-the-shelf pose detectors. The fine-tuned model is then applied to the rest of the frames for automatic labeling. Our method achieves state-of-the-art performance at a reasonable annotation cost. We believe our pipeline offers a valuable tool for the automatic quantification of animal behavior. Visit our project webpage at https://zhuoyang-pan.github.io/animal-labeling.
TAPIP3D: Tracking Any Point in Persistent 3D Geometry
Apr 20, 2025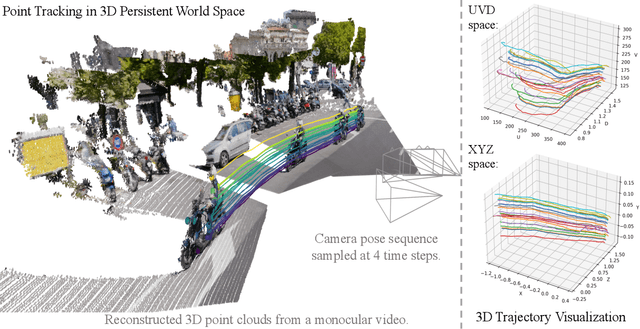



We introduce TAPIP3D, a novel approach for long-term 3D point tracking in monocular RGB and RGB-D videos. TAPIP3D represents videos as camera-stabilized spatio-temporal feature clouds, leveraging depth and camera motion information to lift 2D video features into a 3D world space where camera motion is effectively canceled. TAPIP3D iteratively refines multi-frame 3D motion estimates within this stabilized representation, enabling robust tracking over extended periods. To manage the inherent irregularities of 3D point distributions, we propose a Local Pair Attention mechanism. This 3D contextualization strategy effectively exploits spatial relationships in 3D, forming informative feature neighborhoods for precise 3D trajectory estimation. Our 3D-centric approach significantly outperforms existing 3D point tracking methods and even enhances 2D tracking accuracy compared to conventional 2D pixel trackers when accurate depth is available. It supports inference in both camera coordinates (i.e., unstabilized) and world coordinates, and our results demonstrate that compensating for camera motion improves tracking performance. Our approach replaces the conventional 2D square correlation neighborhoods used in prior 2D and 3D trackers, leading to more robust and accurate results across various 3D point tracking benchmarks. Project Page: https://tapip3d.github.io
EgoPoints: Advancing Point Tracking for Egocentric Videos
Dec 05, 2024



We introduce EgoPoints, a benchmark for point tracking in egocentric videos. We annotate 4.7K challenging tracks in egocentric sequences. Compared to the popular TAP-Vid-DAVIS evaluation benchmark, we include 9x more points that go out-of-view and 59x more points that require re-identification (ReID) after returning to view. To measure the performance of models on these challenging points, we introduce evaluation metrics that specifically monitor tracking performance on points in-view, out-of-view, and points that require re-identification. We then propose a pipeline to create semi-real sequences, with automatic ground truth. We generate 11K such sequences by combining dynamic Kubric objects with scene points from EPIC Fields. When fine-tuning point tracking methods on these sequences and evaluating on our annotated EgoPoints sequences, we improve CoTracker across all metrics, including the tracking accuracy $\delta^\star_{\text{avg}}$ by 2.7 percentage points and accuracy on ReID sequences (ReID$\delta_{\text{avg}}$) by 2.4 points. We also improve $\delta^\star_{\text{avg}}$ and ReID$\delta_{\text{avg}}$ of PIPs++ by 0.3 and 2.8 respectively.
Monocular Dynamic Gaussian Splatting is Fast and Brittle but Smooth Motion Helps
Dec 05, 2024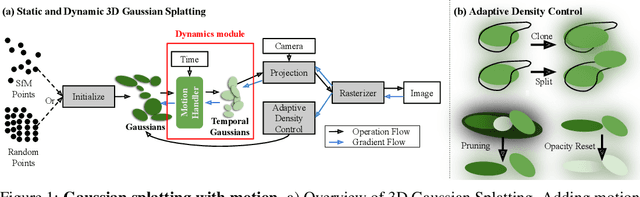

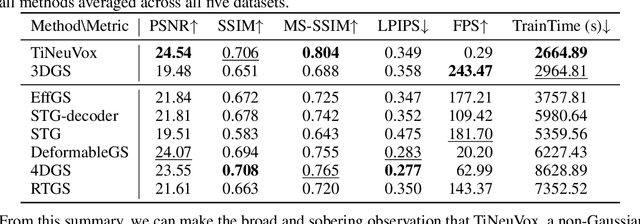
Gaussian splatting methods are emerging as a popular approach for converting multi-view image data into scene representations that allow view synthesis. In particular, there is interest in enabling view synthesis for dynamic scenes using only monocular input data -- an ill-posed and challenging problem. The fast pace of work in this area has produced multiple simultaneous papers that claim to work best, which cannot all be true. In this work, we organize, benchmark, and analyze many Gaussian-splatting-based methods, providing apples-to-apples comparisons that prior works have lacked. We use multiple existing datasets and a new instructive synthetic dataset designed to isolate factors that affect reconstruction quality. We systematically categorize Gaussian splatting methods into specific motion representation types and quantify how their differences impact performance. Empirically, we find that their rank order is well-defined in synthetic data, but the complexity of real-world data currently overwhelms the differences. Furthermore, the fast rendering speed of all Gaussian-based methods comes at the cost of brittleness in optimization. We summarize our experiments into a list of findings that can help to further progress in this lively problem setting. Project Webpage: https://lynl7130.github.io/MonoDyGauBench.github.io/
View-Consistent Hierarchical 3D SegmentationUsing Ultrametric Feature Fields
May 30, 2024Large-scale vision foundation models such as Segment Anything (SAM) demonstrate impressive performance in zero-shot image segmentation at multiple levels of granularity. However, these zero-shot predictions are rarely 3D-consistent. As the camera viewpoint changes in a scene, so do the segmentation predictions, as well as the characterizations of ``coarse" or ``fine" granularity. In this work, we address the challenging task of lifting multi-granular and view-inconsistent image segmentations into a hierarchical and 3D-consistent representation. We learn a novel feature field within a Neural Radiance Field (NeRF) representing a 3D scene, whose segmentation structure can be revealed at different scales by simply using different thresholds on feature distance. Our key idea is to learn an ultrametric feature space, which unlike a Euclidean space, exhibits transitivity in distance-based grouping, naturally leading to a hierarchical clustering. Put together, our method takes view-inconsistent multi-granularity 2D segmentations as input and produces a hierarchy of 3D-consistent segmentations as output. We evaluate our method and several baselines on synthetic datasets with multi-view images and multi-granular segmentation, showcasing improved accuracy and viewpoint-consistency. We additionally provide qualitative examples of our model's 3D hierarchical segmentations in real world scenes.\footnote{The code and dataset are available at:
ODIN: A Single Model for 2D and 3D Perception
Jan 04, 2024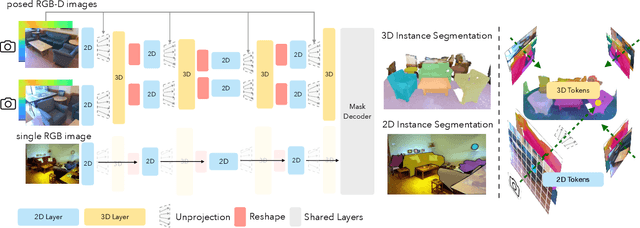
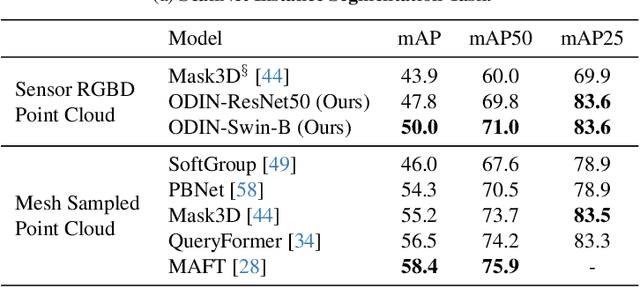
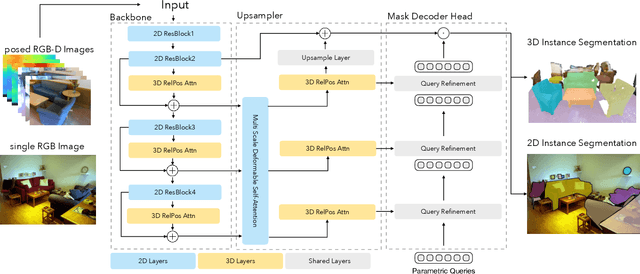
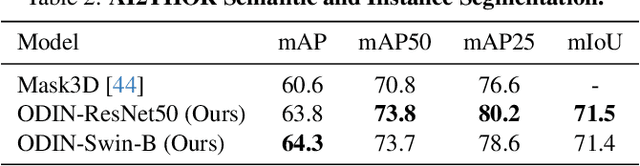
State-of-the-art models on contemporary 3D perception benchmarks like ScanNet consume and label dataset-provided 3D point clouds, obtained through post processing of sensed multiview RGB-D images. They are typically trained in-domain, forego large-scale 2D pre-training and outperform alternatives that featurize the posed RGB-D multiview images instead. The gap in performance between methods that consume posed images versus post-processed 3D point clouds has fueled the belief that 2D and 3D perception require distinct model architectures. In this paper, we challenge this view and propose ODIN (Omni-Dimensional INstance segmentation), a model that can segment and label both 2D RGB images and 3D point clouds, using a transformer architecture that alternates between 2D within-view and 3D cross-view information fusion. Our model differentiates 2D and 3D feature operations through the positional encodings of the tokens involved, which capture pixel coordinates for 2D patch tokens and 3D coordinates for 3D feature tokens. ODIN achieves state-of-the-art performance on ScanNet200, Matterport3D and AI2THOR 3D instance segmentation benchmarks, and competitive performance on ScanNet, S3DIS and COCO. It outperforms all previous works by a wide margin when the sensed 3D point cloud is used in place of the point cloud sampled from 3D mesh. When used as the 3D perception engine in an instructable embodied agent architecture, it sets a new state-of-the-art on the TEACh action-from-dialogue benchmark. Our code and checkpoints can be found at the project website: https://odin-seg.github.io.
Refining Pre-Trained Motion Models
Jan 01, 2024



Given the difficulty of manually annotating motion in video, the current best motion estimation methods are trained with synthetic data, and therefore struggle somewhat due to a train/test gap. Self-supervised methods hold the promise of training directly on real video, but typically perform worse. These include methods trained with warp error (i.e., color constancy) combined with smoothness terms, and methods that encourage cycle-consistency in the estimates (i.e., tracking backwards should yield the opposite trajectory as tracking forwards). In this work, we take on the challenge of improving state-of-the-art supervised models with self-supervised training. We find that when the initialization is supervised weights, most existing self-supervision techniques actually make performance worse instead of better, which suggests that the benefit of seeing the new data is overshadowed by the noise in the training signal. Focusing on obtaining a ``clean'' training signal from real-world unlabelled video, we propose to separate label-making and training into two distinct stages. In the first stage, we use the pre-trained model to estimate motion in a video, and then select the subset of motion estimates which we can verify with cycle-consistency. This produces a sparse but accurate pseudo-labelling of the video. In the second stage, we fine-tune the model to reproduce these outputs, while also applying augmentations on the input. We complement this boot-strapping method with simple techniques that densify and re-balance the pseudo-labels, ensuring that we do not merely train on ``easy'' tracks. We show that our method yields reliable gains over fully-supervised methods in real videos, for both short-term (flow-based) and long-range (multi-frame) pixel tracking.