 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime of the Flight of the Gaussians: Optimizing Depth Indirectly in Dynamic Radiance Fields
May 08, 2025We present a method to reconstruct dynamic scenes from monocular continuous-wave time-of-flight (C-ToF) cameras using raw sensor samples that achieves similar or better accuracy than neural volumetric approaches and is 100x faster. Quickly achieving high-fidelity dynamic 3D reconstruction from a single viewpoint is a significant challenge in computer vision. In C-ToF radiance field reconstruction, the property of interest-depth-is not directly measured, causing an additional challenge. This problem has a large and underappreciated impact upon the optimization when using a fast primitive-based scene representation like 3D Gaussian splatting, which is commonly used with multi-view data to produce satisfactory results and is brittle in its optimization otherwise. We incorporate two heuristics into the optimization to improve the accuracy of scene geometry represented by Gaussians. Experimental results show that our approach produces accurate reconstructions under constrained C-ToF sensing conditions, including for fast motions like swinging baseball bats. https://visual.cs.brown.edu/gftorf
Monocular Dynamic Gaussian Splatting is Fast and Brittle but Smooth Motion Helps
Dec 05, 2024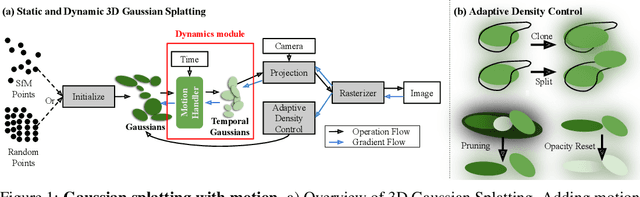
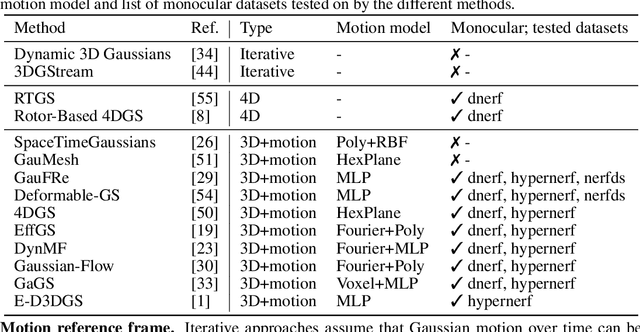

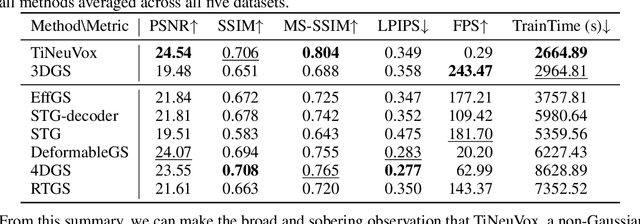
Gaussian splatting methods are emerging as a popular approach for converting multi-view image data into scene representations that allow view synthesis. In particular, there is interest in enabling view synthesis for dynamic scenes using only monocular input data -- an ill-posed and challenging problem. The fast pace of work in this area has produced multiple simultaneous papers that claim to work best, which cannot all be true. In this work, we organize, benchmark, and analyze many Gaussian-splatting-based methods, providing apples-to-apples comparisons that prior works have lacked. We use multiple existing datasets and a new instructive synthetic dataset designed to isolate factors that affect reconstruction quality. We systematically categorize Gaussian splatting methods into specific motion representation types and quantify how their differences impact performance. Empirically, we find that their rank order is well-defined in synthetic data, but the complexity of real-world data currently overwhelms the differences. Furthermore, the fast rendering speed of all Gaussian-based methods comes at the cost of brittleness in optimization. We summarize our experiments into a list of findings that can help to further progress in this lively problem setting. Project Webpage: https://lynl7130.github.io/MonoDyGauBench.github.io/
Spatiotemporally Consistent HDR Indoor Lighting Estimation
May 07, 2023
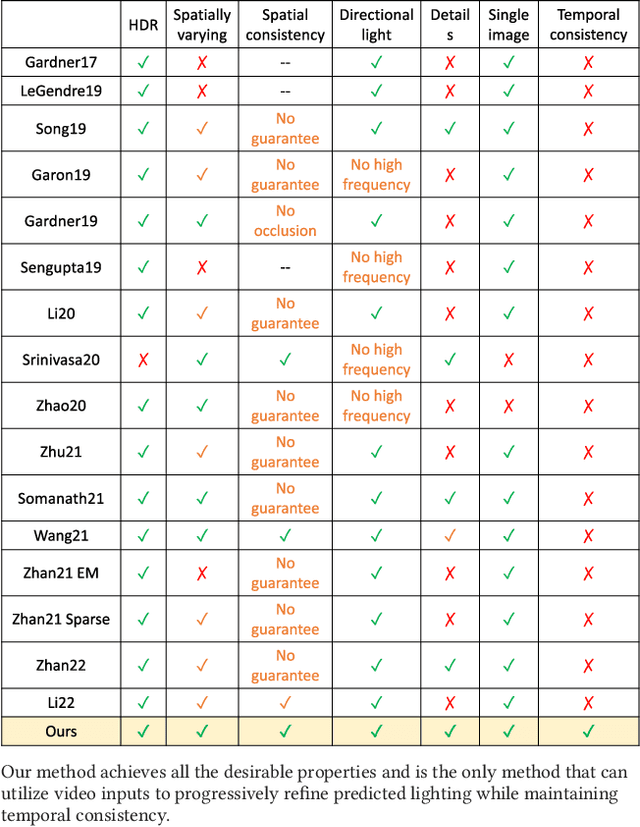
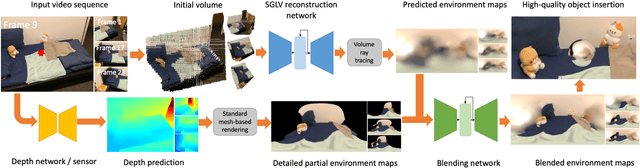
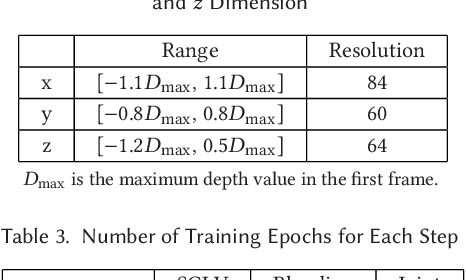
We propose a physically-motivated deep learning framework to solve a general version of the challenging indoor lighting estimation problem. Given a single LDR image with a depth map, our method predicts spatially consistent lighting at any given image position. Particularly, when the input is an LDR video sequence, our framework not only progressively refines the lighting prediction as it sees more regions, but also preserves temporal consistency by keeping the refinement smooth. Our framework reconstructs a spherical Gaussian lighting volume (SGLV) through a tailored 3D encoder-decoder, which enables spatially consistent lighting prediction through volume ray tracing, a hybrid blending network for detailed environment maps, an in-network Monte-Carlo rendering layer to enhance photorealism for virtual object insertion, and recurrent neural networks (RNN) to achieve temporally consistent lighting prediction with a video sequence as the input. For training, we significantly enhance the OpenRooms public dataset of photorealistic synthetic indoor scenes with around 360K HDR environment maps of much higher resolution and 38K video sequences, rendered with GPU-based path tracing. Experiments show that our framework achieves lighting prediction with higher quality compared to state-of-the-art single-image or video-based methods, leading to photorealistic AR applications such as object insertion.