 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoTL: Egocentric Think-Aloud Chains for Long-Horizon Tasks
Apr 10, 2026Large foundation models have made significant advances in embodied intelligence, enabling synthesis and reasoning over egocentric input for household tasks. However, VLM-based auto-labeling is often noisy because the primary data sources lack accurate human action labels, chain-of-thought (CoT), and spatial annotations; these errors are amplified during long-horizon spatial instruction following. These issues stem from insufficient coverage of minute-long, daily household planning tasks and from inaccurate spatial grounding. As a result, VLM reasoning chains and world-model synthesis can hallucinate objects, skip steps, or fail to respect real-world physical attributes. To address these gaps, we introduce EgoTL. EgoTL builds a think-aloud capture pipeline for egocentric data. It uses a say-before-act protocol to record step-by-step goals and spoken reasoning with word-level timestamps, then calibrates physical properties with metric-scale spatial estimators, a memory-bank walkthrough for scene context, and clip-level tags for navigation instructions and detailed manipulation actions. With EgoTL, we are able to benchmark VLMs and World Models on six task dimensions from three layers and long-horizon generation over minute-long sequences across over 100 daily household tasks. We find that foundation models still fall short as egocentric assistants or open-world simulators. Finally, we finetune foundation models with human CoT aligned with metric labels on the training split of EgoTL, which improves long-horizon planning and reasoning, step-wise reasoning, instruction following, and spatial grounding.
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
LASER: Layer-wise Scale Alignment for Training-Free Streaming 4D Reconstruction
Dec 15, 2025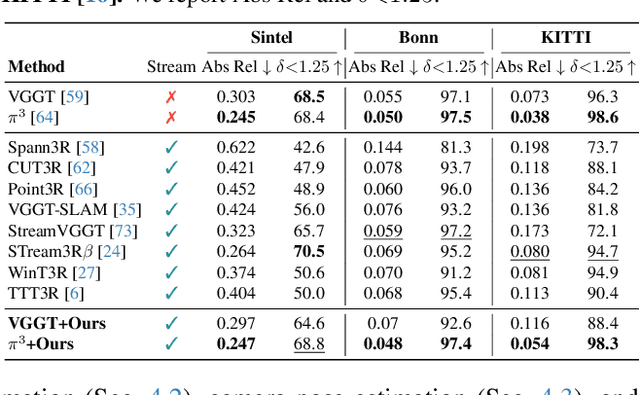
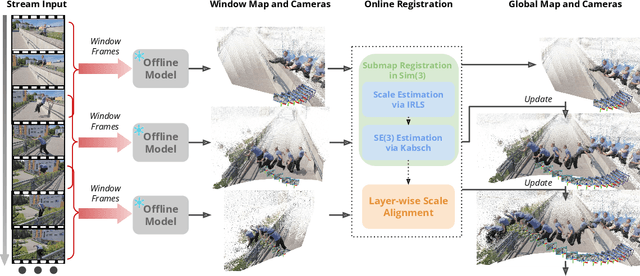
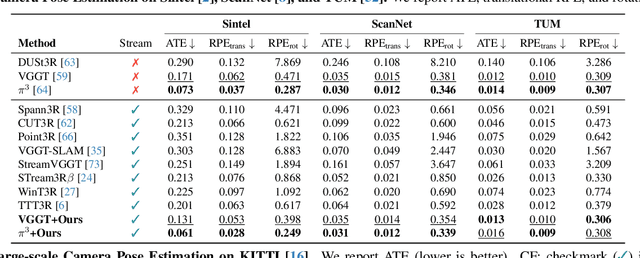
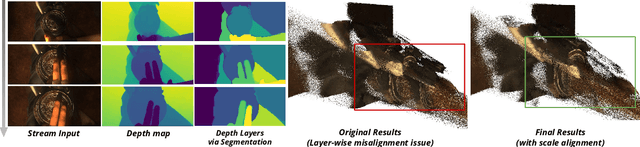
Recent feed-forward reconstruction models like VGGT and $π^3$ achieve impressive reconstruction quality but cannot process streaming videos due to quadratic memory complexity, limiting their practical deployment. While existing streaming methods address this through learned memory mechanisms or causal attention, they require extensive retraining and may not fully leverage the strong geometric priors of state-of-the-art offline models. We propose LASER, a training-free framework that converts an offline reconstruction model into a streaming system by aligning predictions across consecutive temporal windows. We observe that simple similarity transformation ($\mathrm{Sim}(3)$) alignment fails due to layer depth misalignment: monocular scale ambiguity causes relative depth scales of different scene layers to vary inconsistently between windows. To address this, we introduce layer-wise scale alignment, which segments depth predictions into discrete layers, computes per-layer scale factors, and propagates them across both adjacent windows and timestamps. Extensive experiments show that LASER achieves state-of-the-art performance on camera pose estimation and point map reconstruction %quality with offline models while operating at 14 FPS with 6 GB peak memory on a RTX A6000 GPU, enabling practical deployment for kilometer-scale streaming videos. Project website: $\href{https://neu-vi.github.io/LASER/}{\texttt{https://neu-vi.github.io/LASER/}}$
MoDoMoDo: Multi-Domain Data Mixtures for Multimodal LLM Reinforcement Learning
May 30, 2025



Reinforcement Learning with Verifiable Rewards (RLVR) has recently emerged as a powerful paradigm for post-training large language models (LLMs), achieving state-of-the-art performance on tasks with structured, verifiable answers. Applying RLVR to Multimodal LLMs (MLLMs) presents significant opportunities but is complicated by the broader, heterogeneous nature of vision-language tasks that demand nuanced visual, logical, and spatial capabilities. As such, training MLLMs using RLVR on multiple datasets could be beneficial but creates challenges with conflicting objectives from interaction among diverse datasets, highlighting the need for optimal dataset mixture strategies to improve generalization and reasoning. We introduce a systematic post-training framework for Multimodal LLM RLVR, featuring a rigorous data mixture problem formulation and benchmark implementation. Specifically, (1) We developed a multimodal RLVR framework for multi-dataset post-training by curating a dataset that contains different verifiable vision-language problems and enabling multi-domain online RL learning with different verifiable rewards; (2) We proposed a data mixture strategy that learns to predict the RL fine-tuning outcome from the data mixture distribution, and consequently optimizes the best mixture. Comprehensive experiments showcase that multi-domain RLVR training, when combined with mixture prediction strategies, can significantly boost MLLM general reasoning capacities. Our best mixture improves the post-trained model's accuracy on out-of-distribution benchmarks by an average of 5.24% compared to the same model post-trained with uniform data mixture, and by a total of 20.74% compared to the pre-finetuning baseline.
Zero-Shot Monocular Scene Flow Estimation in the Wild
Jan 17, 2025Large models have shown generalization across datasets for many low-level vision tasks, like depth estimation, but no such general models exist for scene flow. Even though scene flow has wide potential use, it is not used in practice because current predictive models do not generalize well. We identify three key challenges and propose solutions for each.First, we create a method that jointly estimates geometry and motion for accurate prediction. Second, we alleviate scene flow data scarcity with a data recipe that affords us 1M annotated training samples across diverse synthetic scenes. Third, we evaluate different parameterizations for scene flow prediction and adopt a natural and effective parameterization. Our resulting model outperforms existing methods as well as baselines built on large-scale models in terms of 3D end-point error, and shows zero-shot generalization to the casually captured videos from DAVIS and the robotic manipulation scenes from RoboTAP. Overall, our approach makes scene flow prediction more practical in-the-wild.
Monocular Dynamic Gaussian Splatting is Fast and Brittle but Smooth Motion Helps
Dec 05, 2024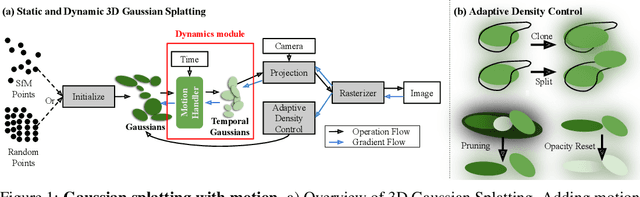
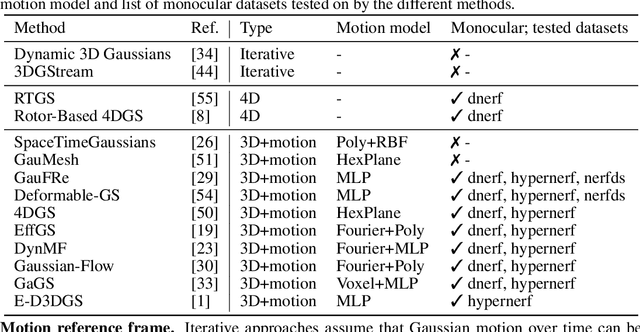

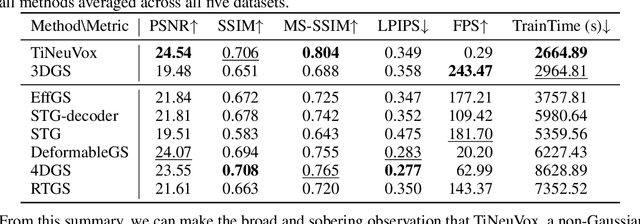
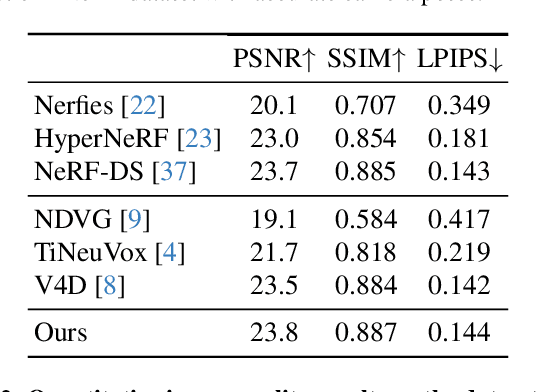
Gaussian splatting methods are emerging as a popular approach for converting multi-view image data into scene representations that allow view synthesis. In particular, there is interest in enabling view synthesis for dynamic scenes using only monocular input data -- an ill-posed and challenging problem. The fast pace of work in this area has produced multiple simultaneous papers that claim to work best, which cannot all be true. In this work, we organize, benchmark, and analyze many Gaussian-splatting-based methods, providing apples-to-apples comparisons that prior works have lacked. We use multiple existing datasets and a new instructive synthetic dataset designed to isolate factors that affect reconstruction quality. We systematically categorize Gaussian splatting methods into specific motion representation types and quantify how their differences impact performance. Empirically, we find that their rank order is well-defined in synthetic data, but the complexity of real-world data currently overwhelms the differences. Furthermore, the fast rendering speed of all Gaussian-based methods comes at the cost of brittleness in optimization. We summarize our experiments into a list of findings that can help to further progress in this lively problem setting. Project Webpage: https://lynl7130.github.io/MonoDyGauBench.github.io/
GauFRe: Gaussian Deformation Fields for Real-time Dynamic Novel View Synthesis
Dec 18, 2023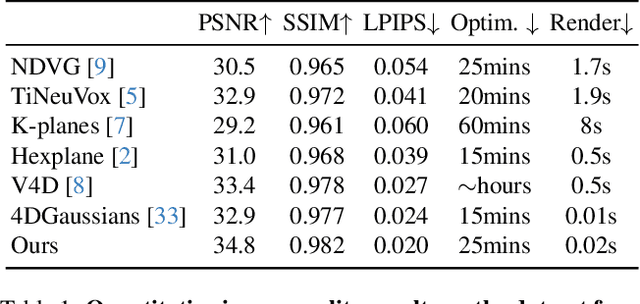
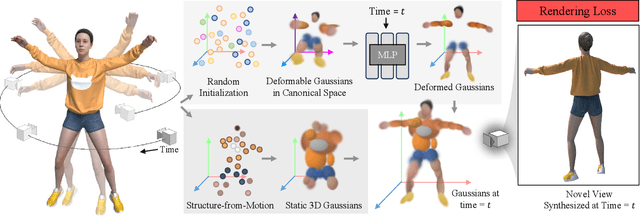
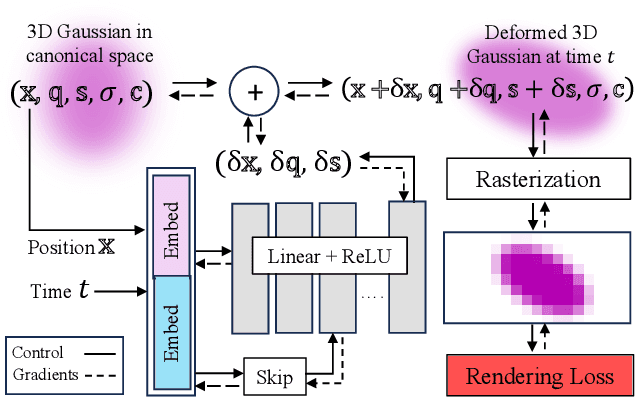
We propose a method for dynamic scene reconstruction using deformable 3D Gaussians that is tailored for monocular video. Building upon the efficiency of Gaussian splatting, our approach extends the representation to accommodate dynamic elements via a deformable set of Gaussians residing in a canonical space, and a time-dependent deformation field defined by a multi-layer perceptron (MLP). Moreover, under the assumption that most natural scenes have large regions that remain static, we allow the MLP to focus its representational power by additionally including a static Gaussian point cloud. The concatenated dynamic and static point clouds form the input for the Gaussian Splatting rasterizer, enabling real-time rendering. The differentiable pipeline is optimized end-to-end with a self-supervised rendering loss. Our method achieves results that are comparable to state-of-the-art dynamic neural radiance field methods while allowing much faster optimization and rendering. Project website: https://lynl7130.github.io/gaufre/index.html
Semantic Attention Flow Fields for Dynamic Scene Decomposition
Mar 02, 2023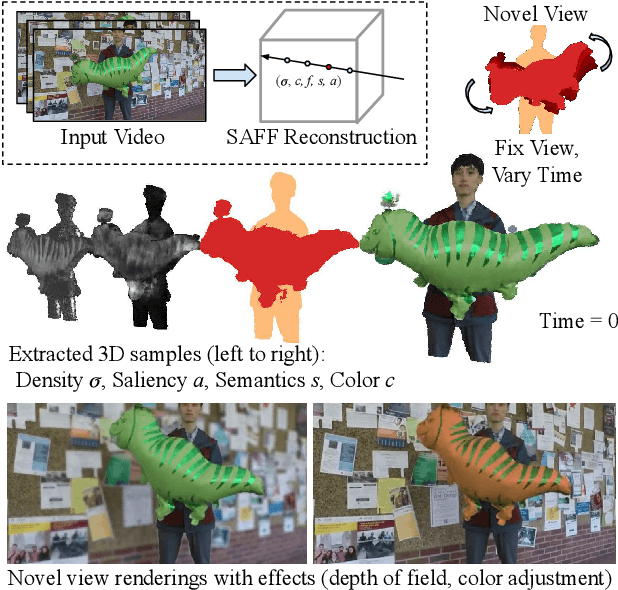
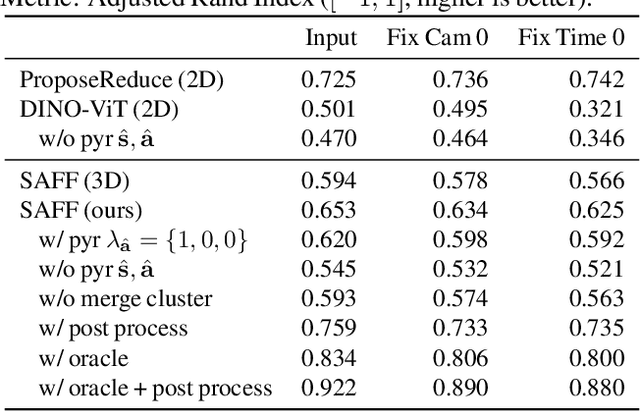
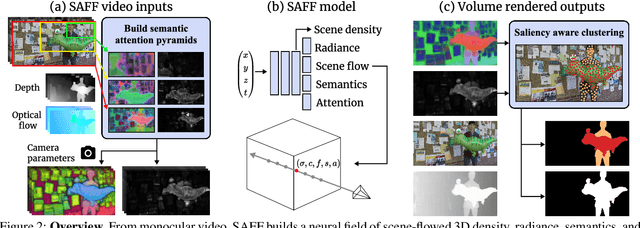
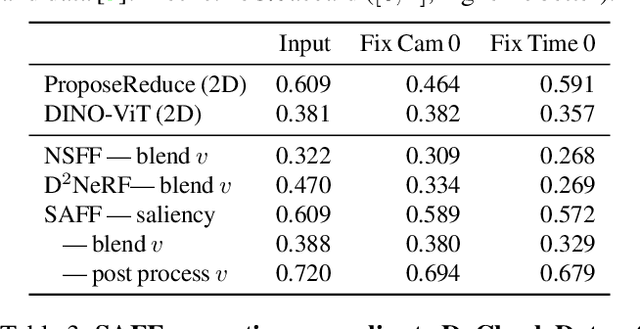
We present SAFF: a dynamic neural volume reconstruction of a casual monocular video that consists of time-varying color, density, scene flow, semantics, and attention information. The semantics and attention let us identify salient foreground objects separately from the background in arbitrary spacetime views. We add two network heads to represent the semantic and attention information. For optimization, we design semantic attention pyramids from DINO-ViT outputs that trade detail with whole-image context. After optimization, we perform a saliency-aware clustering to decompose the scene. For evaluation on real-world dynamic scene decomposition across spacetime, we annotate object masks in the NVIDIA Dynamic Scene Dataset. We demonstrate that SAFF can decompose dynamic scenes without affecting RGB or depth reconstruction quality, that volume-integrated SAFF outperforms 2D baselines, and that SAFF improves foreground/background segmentation over recent static/dynamic split methods. Project Webpage: https://visual.cs.brown.edu/saff
SGEITL: Scene Graph Enhanced Image-Text Learning for Visual Commonsense Reasoning
Dec 16, 2021

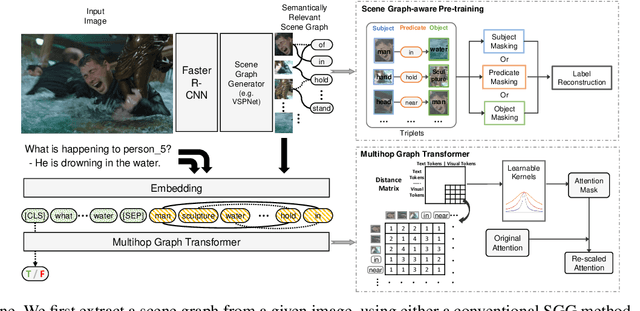

Answering complex questions about images is an ambitious goal for machine intelligence, which requires a joint understanding of images, text, and commonsense knowledge, as well as a strong reasoning ability. Recently, multimodal Transformers have made great progress in the task of Visual Commonsense Reasoning (VCR), by jointly understanding visual objects and text tokens through layers of cross-modality attention. However, these approaches do not utilize the rich structure of the scene and the interactions between objects which are essential in answering complex commonsense questions. We propose a Scene Graph Enhanced Image-Text Learning (SGEITL) framework to incorporate visual scene graphs in commonsense reasoning. To exploit the scene graph structure, at the model structure level, we propose a multihop graph transformer for regularizing attention interaction among hops. As for pre-training, a scene-graph-aware pre-training method is proposed to leverage structure knowledge extracted in the visual scene graph. Moreover, we introduce a method to train and generate domain-relevant visual scene graphs using textual annotations in a weakly-supervised manner. Extensive experiments on VCR and other tasks show a significant performance boost compared with the state-of-the-art methods and prove the efficacy of each proposed component.
* AAAI 2022
SSCNav: Confidence-Aware Semantic Scene Completion for Visual Semantic Navigation
Dec 08, 2020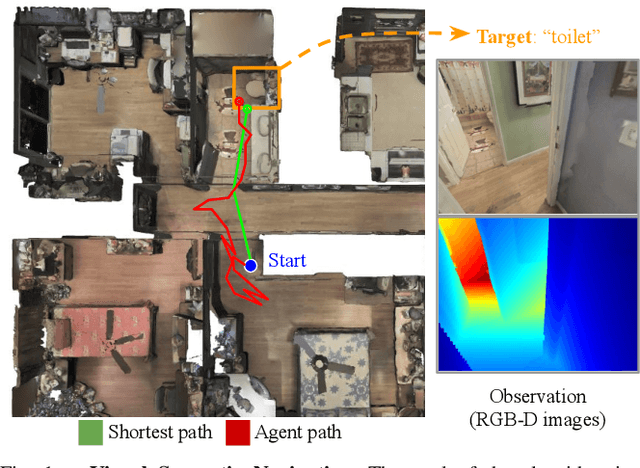
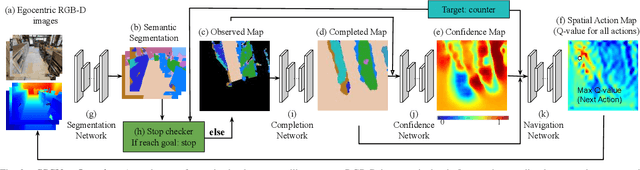
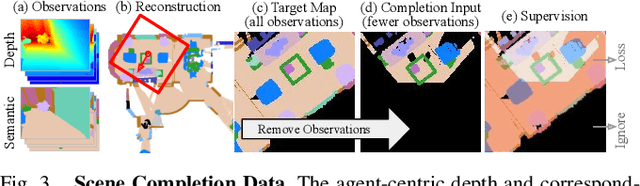
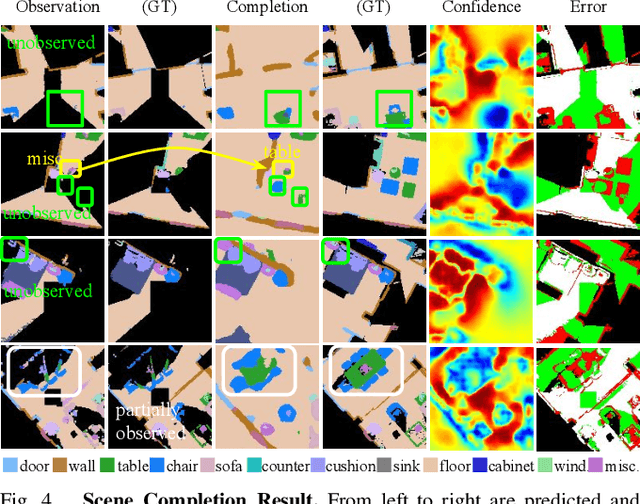
This paper focuses on visual semantic navigation, the task of producing actions for an active agent to navigate to a specified target object category in an unknown environment. To complete this task, the algorithm should simultaneously locate and navigate to an instance of the category. In comparison to the traditional point goal navigation, this task requires the agent to have a stronger contextual prior of indoor environments. We introduce SSCNav, an algorithm that explicitly models scene priors using a confidence-aware semantic scene completion module to complete the scene and guide the agent's navigation planning. Given a partial observation of the environment, SSCNav first infers a complete scene representation with semantic labels for the unobserved scene together with a confidence map associated with its own prediction. Then, a policy network infers the action from the scene completion result and confidence map. Our experiments demonstrate that the proposed scene completion module improves the efficiency of the downstream navigation policies. https://youtu.be/tfBbdGS72zg