 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialClaw: Rethinking Action Interface for Agentic Spatial Reasoning
Jun 11, 2026Spatial reasoning, the ability to determine where objects are, how they relate, and how they move in 3D, remains a fundamental challenge for vision-language models (VLMs). Tool-augmented agents attempt to address this by augmenting VLMs with specialist perception modules, yet their effectiveness is bounded by the action interface through which those tools are invoked. In this work, we study how the design of this interface shapes the agent's capacity for open-ended spatial reasoning. Existing spatial agents either employ single-pass code execution, which commits to a full analysis strategy before any intermediate result is observed, or rely on a structured tool-call interface that often offers less flexibility for freely composing operations or tailoring the analysis to each task. Both designs offer limited flexibility for open-ended, complex 3D/4D spatial reasoning. We therefore propose SpatialClaw, a training-free framework for spatial reasoning that adopts code as the action interface. SpatialClaw maintains a stateful Python kernel pre-loaded with input frames and a suite of perception and geometry primitives, letting a VLM-backed agent write one executable cell per step conditioned on all prior outputs, enabling the agent to flexibly compose and manipulate perception results and adapt its analysis to both intermediate text and visual observations and the demands of each problem. Evaluated across 20 spatial reasoning benchmarks spanning a broad range of static and dynamic 3D/4D spatial reasoning tasks, SpatialClaw achieves 59.9% average accuracy, outperforming the recent spatial agent by +11.2 points, with consistent gains across six VLM backbones from two model families without any benchmark- or model-specific adaptation.
4DP-QA: Scalable QA for 4D Perception in Vision Language Models
Jun 10, 2026Despite recent advances, Vision Language Models (VLMs) still struggle to grasp the dynamics of the world. We note that the ability to reason about a 4D scene, challenging in itself, is further complicated by two factors. First, VLMs observe motion indirectly via its projection onto 2D images. Second, existing datasets fail to disentangle object and camera motion. To address these challenges, we present a QA generation pipeline that focuses on motion-related scene understanding. We take particular care of the entanglement of camera and object motion by casting tracking in both the traditional way and in a novel, fixed reference system, dubbed True-Motion Tracking, which provides an intuitive description of motion. From this pipeline, we generate a large-scale training dataset of 400K samples, 4DP-QA (4D Perception QA), and a 2.2K-sample benchmark, 4DP-QA-Bench. Training existing models on our dataset yields performance improvements on an external benchmark, validating the effectiveness of our method.
L4P: Low-Level 4D Vision Perception Unified
Feb 18, 2025The spatio-temporal relationship between the pixels of a video carries critical information for low-level 4D perception. A single model that reasons about it should be able to solve several such tasks well. Yet, most state-of-the-art methods rely on architectures specialized for the task at hand. We present L4P (pronounced "LAP"), a feedforward, general-purpose architecture that solves low-level 4D perception tasks in a unified framework. L4P combines a ViT-based backbone with per-task heads that are lightweight and therefore do not require extensive training. Despite its general and feedforward formulation, our method matches or surpasses the performance of existing specialized methods on both dense tasks, such as depth or optical flow estimation, and sparse tasks, such as 2D/3D tracking. Moreover, it solves all those tasks at once in a time comparable to that of individual single-task methods.
Zero-Shot Monocular Scene Flow Estimation in the Wild
Jan 17, 2025Large models have shown generalization across datasets for many low-level vision tasks, like depth estimation, but no such general models exist for scene flow. Even though scene flow has wide potential use, it is not used in practice because current predictive models do not generalize well. We identify three key challenges and propose solutions for each.First, we create a method that jointly estimates geometry and motion for accurate prediction. Second, we alleviate scene flow data scarcity with a data recipe that affords us 1M annotated training samples across diverse synthetic scenes. Third, we evaluate different parameterizations for scene flow prediction and adopt a natural and effective parameterization. Our resulting model outperforms existing methods as well as baselines built on large-scale models in terms of 3D end-point error, and shows zero-shot generalization to the casually captured videos from DAVIS and the robotic manipulation scenes from RoboTAP. Overall, our approach makes scene flow prediction more practical in-the-wild.
nvTorchCam: An Open-source Library for Camera-Agnostic Differentiable Geometric Vision
Oct 15, 2024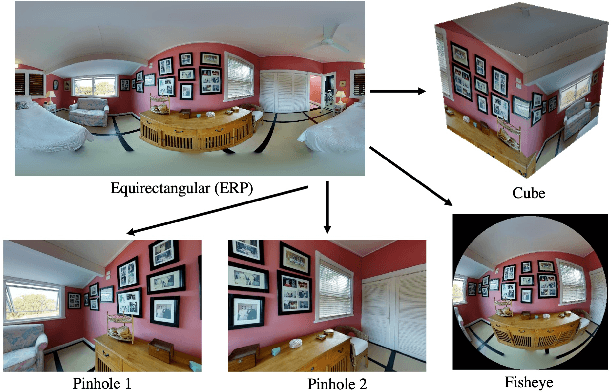



We introduce nvTorchCam, an open-source library under the Apache 2.0 license, designed to make deep learning algorithms camera model-independent. nvTorchCam abstracts critical camera operations such as projection and unprojection, allowing developers to implement algorithms once and apply them across diverse camera models--including pinhole, fisheye, and 360 equirectangular panoramas, which are commonly used in automotive and real estate capture applications. Built on PyTorch, nvTorchCam is fully differentiable and supports GPU acceleration and batching for efficient computation. Furthermore, deep learning models trained for one camera type can be directly transferred to other camera types without requiring additional modification. In this paper, we provide an overview of nvTorchCam, its functionality, and present various code examples and diagrams to demonstrate its usage. Source code and installation instructions can be found on the nvTorchCam GitHub page at https://github.com/NVlabs/nvTorchCam.
FoVA-Depth: Field-of-View Agnostic Depth Estimation for Cross-Dataset Generalization
Jan 24, 2024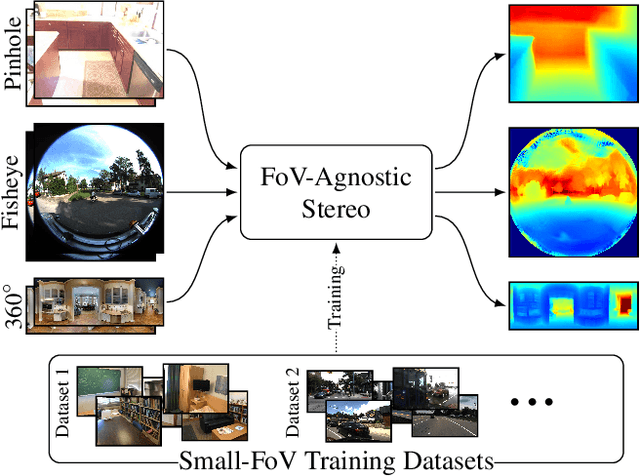

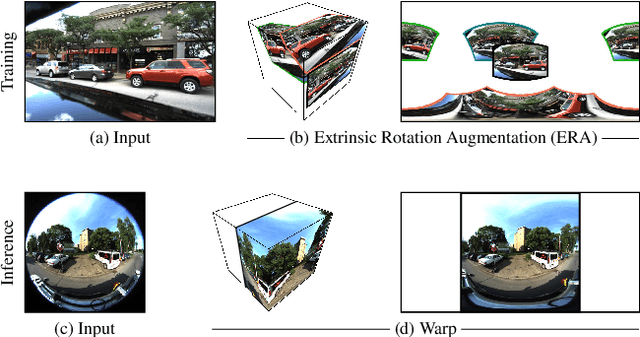
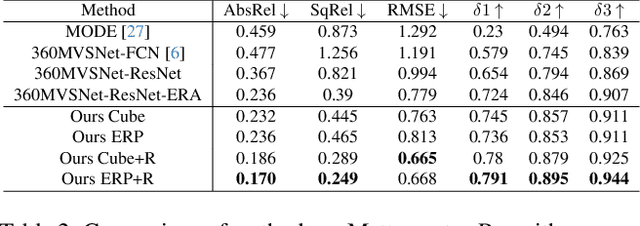
Wide field-of-view (FoV) cameras efficiently capture large portions of the scene, which makes them attractive in multiple domains, such as automotive and robotics. For such applications, estimating depth from multiple images is a critical task, and therefore, a large amount of ground truth (GT) data is available. Unfortunately, most of the GT data is for pinhole cameras, making it impossible to properly train depth estimation models for large-FoV cameras. We propose the first method to train a stereo depth estimation model on the widely available pinhole data, and to generalize it to data captured with larger FoVs. Our intuition is simple: We warp the training data to a canonical, large-FoV representation and augment it to allow a single network to reason about diverse types of distortions that otherwise would prevent generalization. We show strong generalization ability of our approach on both indoor and outdoor datasets, which was not possible with previous methods.
Binary TTC: A Temporal Geofence for Autonomous Navigation
Jan 12, 2021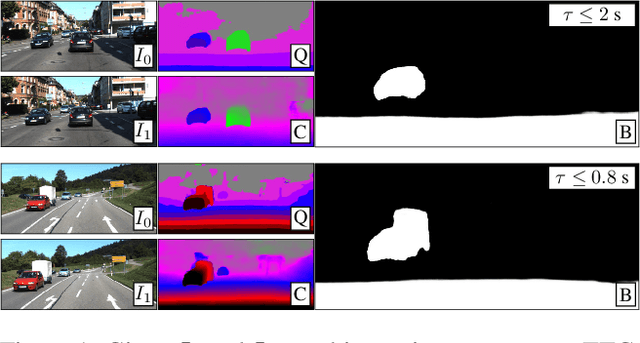
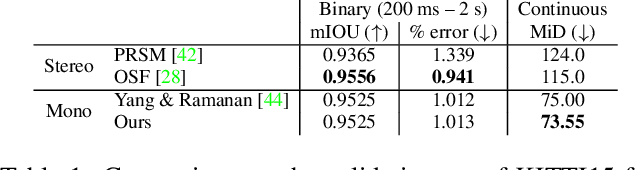

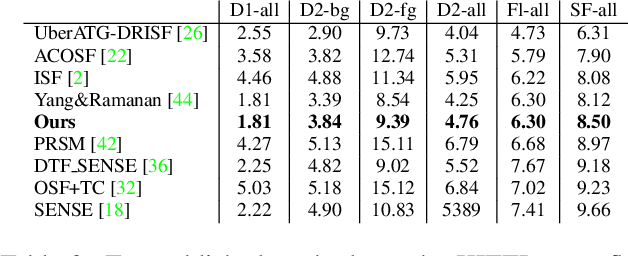
Time-to-contact (TTC), the time for an object to collide with the observer's plane, is a powerful tool for path planning: it is potentially more informative than the depth, velocity, and acceleration of objects in the scene -- even for humans. TTC presents several advantages, including requiring only a monocular, uncalibrated camera. However, regressing TTC for each pixel is not straightforward, and most existing methods make over-simplifying assumptions about the scene. We address this challenge by estimating TTC via a series of simpler, binary classifications. We predict with low latency whether the observer will collide with an obstacle within a certain time, which is often more critical than knowing exact, per-pixel TTC. For such scenarios, our method offers a temporal geofence in 6.4 ms -- over 25x faster than existing methods. Our approach can also estimate per-pixel TTC with arbitrarily fine quantization (including continuous values), when the computational budget allows for it. To the best of our knowledge, our method is the first to offer TTC information (binary or coarsely quantized) at sufficiently high frame-rates for practical use.
Bi3D: Stereo Depth Estimation via Binary Classifications
Jun 01, 2020Stereo-based depth estimation is a cornerstone of computer vision, with state-of-the-art methods delivering accurate results in real time. For several applications such as autonomous navigation, however, it may be useful to trade accuracy for lower latency. We present Bi3D, a method that estimates depth via a series of binary classifications. Rather than testing if objects are at a particular depth $D$, as existing stereo methods do, it classifies them as being closer or farther than $D$. This property offers a powerful mechanism to balance accuracy and latency. Given a strict time budget, Bi3D can detect objects closer than a given distance in as little as a few milliseconds, or estimate depth with arbitrarily coarse quantization, with complexity linear with the number of quantization levels. Bi3D can also use the allotted quantization levels to get continuous depth, but in a specific depth range. For standard stereo (i.e., continuous depth on the whole range), our method is close to or on par with state-of-the-art, finely tuned stereo methods.
Meshlet Priors for 3D Mesh Reconstruction
Jan 06, 2020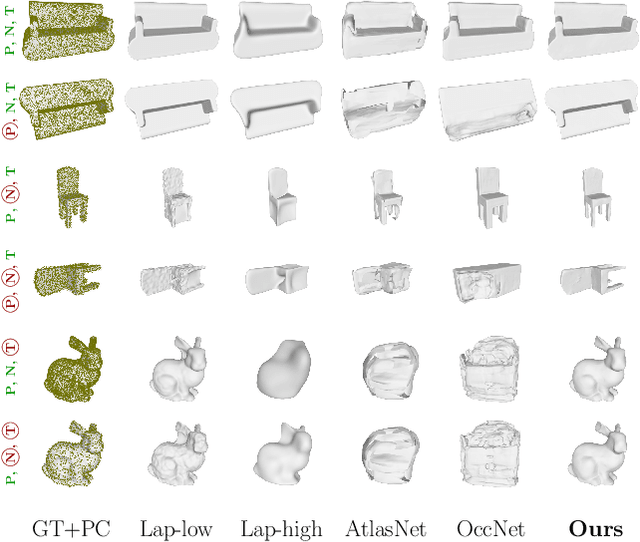
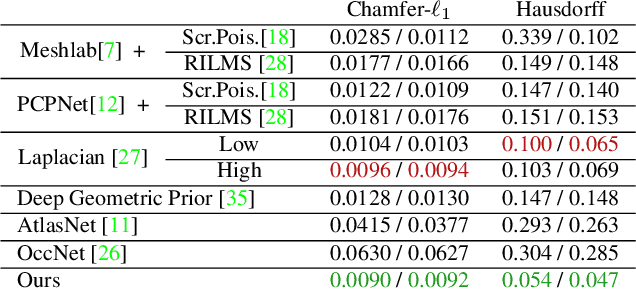
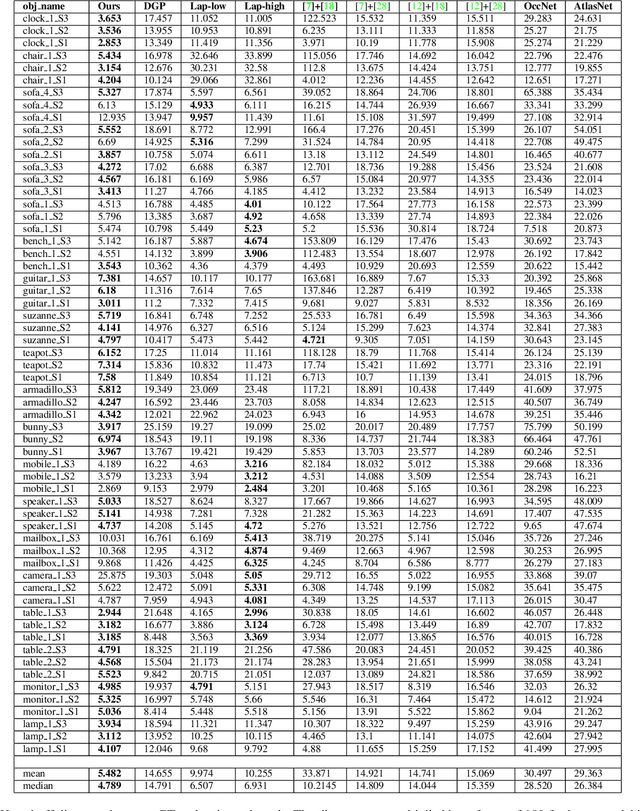

Estimating a mesh from an unordered set of sparse, noisy 3D points is a challenging problem that requires carefully selected priors. Existing hand-crafted priors, such as smoothness regularizers, impose an undesirable trade-off between attenuating noise and preserving local detail. Recent deep-learning approaches produce impressive results by learning priors directly from the data. However, the priors are learned at the object level, which makes these algorithms class-specific, and even sensitive to the pose of the object. We introduce meshlets, small patches of mesh that we use to learn local shape priors. Meshlets act as a dictionary of local features and thus allow to use learned priors to reconstruct object meshes in any pose and from unseen classes, even when the noise is large and the samples sparse.