 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating and Characterizing Scenarios for Safety Testing of Autonomous Vehicles
Mar 12, 2021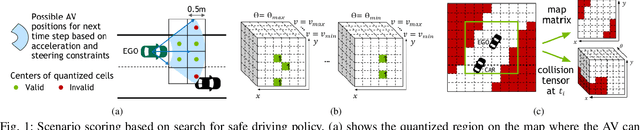
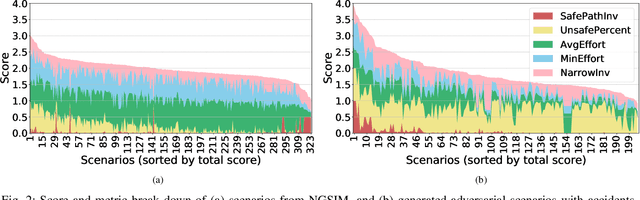
Extracting interesting scenarios from real-world data as well as generating failure cases is important for the development and testing of autonomous systems. We propose efficient mechanisms to both characterize and generate testing scenarios using a state-of-the-art driving simulator. For any scenario, our method generates a set of possible driving paths and identifies all the possible safe driving trajectories that can be taken starting at different times, to compute metrics that quantify the complexity of the scenario. We use our method to characterize real driving data from the Next Generation Simulation (NGSIM) project, as well as adversarial scenarios generated in simulation. We rank the scenarios by defining metrics based on the complexity of avoiding accidents and provide insights into how the AV could have minimized the probability of incurring an accident. We demonstrate a strong correlation between the proposed metrics and human intuition.
Bi3D: Stereo Depth Estimation via Binary Classifications
Jun 01, 2020Stereo-based depth estimation is a cornerstone of computer vision, with state-of-the-art methods delivering accurate results in real time. For several applications such as autonomous navigation, however, it may be useful to trade accuracy for lower latency. We present Bi3D, a method that estimates depth via a series of binary classifications. Rather than testing if objects are at a particular depth $D$, as existing stereo methods do, it classifies them as being closer or farther than $D$. This property offers a powerful mechanism to balance accuracy and latency. Given a strict time budget, Bi3D can detect objects closer than a given distance in as little as a few milliseconds, or estimate depth with arbitrarily coarse quantization, with complexity linear with the number of quantization levels. Bi3D can also use the allotted quantization levels to get continuous depth, but in a specific depth range. For standard stereo (i.e., continuous depth on the whole range), our method is close to or on par with state-of-the-art, finely tuned stereo methods.
Extreme View Synthesis
Dec 12, 2018
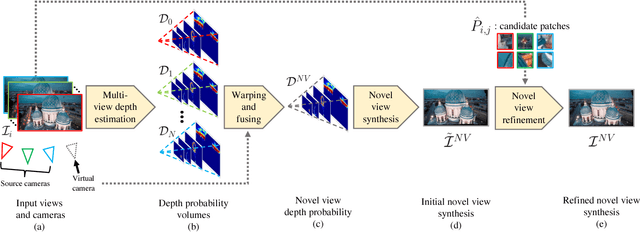

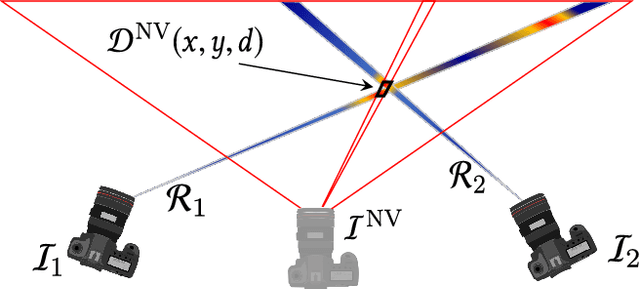
We present Extreme View Synthesis, a solution for novel view extrapolation when the number of input images is small. Occlusions and depth uncertainty, in this context, are two of the most pressing issues, and worsen as the degree of extrapolation increases. State-of-the-art methods approach this problem by leveraging explicit geometric constraints, or learned priors. Our key insight is that only by modeling both depth uncertainty and image priors can the extreme cases be solved. We first generate a depth probability volume for the novel view and synthesize an estimate of the sought image. Then, we use learned priors combined with depth uncertainty, to refine it. Our method is the first to show visually pleasing results for baseline magnifications of up to 30X.
Learning Rigidity in Dynamic Scenes with a Moving Camera for 3D Motion Field Estimation
Jul 30, 2018
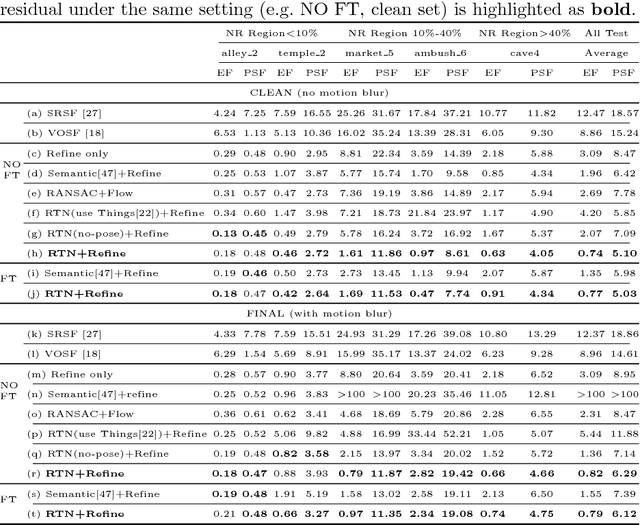
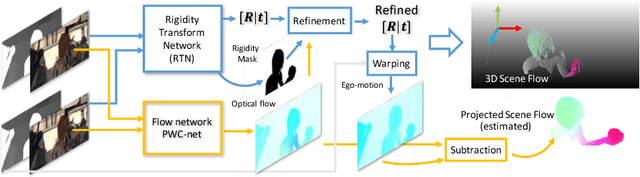
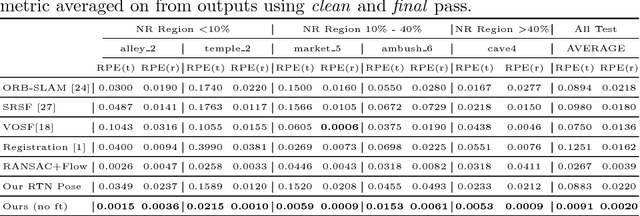
Estimation of 3D motion in a dynamic scene from a temporal pair of images is a core task in many scene understanding problems. In real world applications, a dynamic scene is commonly captured by a moving camera (i.e., panning, tilting or hand-held), increasing the task complexity because the scene is observed from different view points. The main challenge is the disambiguation of the camera motion from scene motion, which becomes more difficult as the amount of rigidity observed decreases, even with successful estimation of 2D image correspondences. Compared to other state-of-the-art 3D scene flow estimation methods, in this paper we propose to \emph{learn} the rigidity of a scene in a supervised manner from a large collection of dynamic scene data, and directly infer a rigidity mask from two sequential images with depths. With the learned network, we show how we can effectively estimate camera motion and projected scene flow using computed 2D optical flow and the inferred rigidity mask. For training and testing the rigidity network, we also provide a new semi-synthetic dynamic scene dataset (synthetic foreground objects with a real background) and an evaluation split that accounts for the percentage of observed non-rigid pixels. Through our evaluation we show the proposed framework outperforms current state-of-the-art scene flow estimation methods in challenging dynamic scenes.
Locally Non-rigid Registration for Mobile HDR Photography
May 05, 2015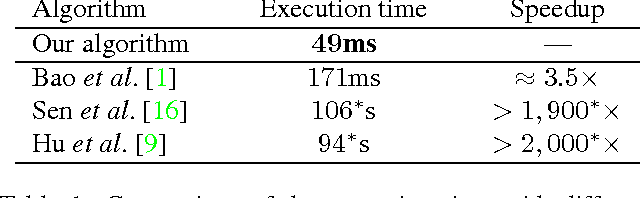



Image registration for stack-based HDR photography is challenging. If not properly accounted for, camera motion and scene changes result in artifacts in the composite image. Unfortunately, existing methods to address this problem are either accurate, but too slow for mobile devices, or fast, but prone to failing. We propose a method that fills this void: our approach is extremely fast---under 700ms on a commercial tablet for a pair of 5MP images---and prevents the artifacts that arise from insufficient registration quality.