 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL4P: Low-Level 4D Vision Perception Unified
Feb 18, 2025The spatio-temporal relationship between the pixels of a video carries critical information for low-level 4D perception. A single model that reasons about it should be able to solve several such tasks well. Yet, most state-of-the-art methods rely on architectures specialized for the task at hand. We present L4P (pronounced "LAP"), a feedforward, general-purpose architecture that solves low-level 4D perception tasks in a unified framework. L4P combines a ViT-based backbone with per-task heads that are lightweight and therefore do not require extensive training. Despite its general and feedforward formulation, our method matches or surpasses the performance of existing specialized methods on both dense tasks, such as depth or optical flow estimation, and sparse tasks, such as 2D/3D tracking. Moreover, it solves all those tasks at once in a time comparable to that of individual single-task methods.
Zero-Shot Monocular Scene Flow Estimation in the Wild
Jan 17, 2025Large models have shown generalization across datasets for many low-level vision tasks, like depth estimation, but no such general models exist for scene flow. Even though scene flow has wide potential use, it is not used in practice because current predictive models do not generalize well. We identify three key challenges and propose solutions for each.First, we create a method that jointly estimates geometry and motion for accurate prediction. Second, we alleviate scene flow data scarcity with a data recipe that affords us 1M annotated training samples across diverse synthetic scenes. Third, we evaluate different parameterizations for scene flow prediction and adopt a natural and effective parameterization. Our resulting model outperforms existing methods as well as baselines built on large-scale models in terms of 3D end-point error, and shows zero-shot generalization to the casually captured videos from DAVIS and the robotic manipulation scenes from RoboTAP. Overall, our approach makes scene flow prediction more practical in-the-wild.
nvTorchCam: An Open-source Library for Camera-Agnostic Differentiable Geometric Vision
Oct 15, 2024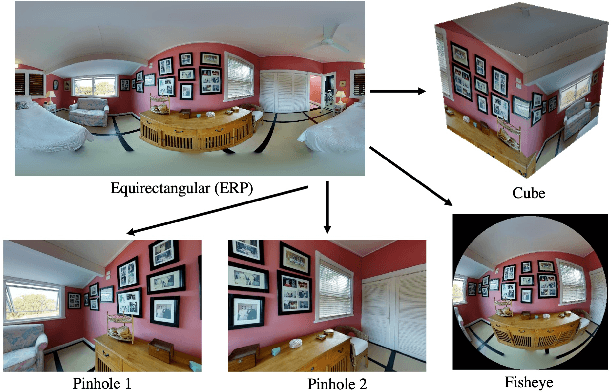



We introduce nvTorchCam, an open-source library under the Apache 2.0 license, designed to make deep learning algorithms camera model-independent. nvTorchCam abstracts critical camera operations such as projection and unprojection, allowing developers to implement algorithms once and apply them across diverse camera models--including pinhole, fisheye, and 360 equirectangular panoramas, which are commonly used in automotive and real estate capture applications. Built on PyTorch, nvTorchCam is fully differentiable and supports GPU acceleration and batching for efficient computation. Furthermore, deep learning models trained for one camera type can be directly transferred to other camera types without requiring additional modification. In this paper, we provide an overview of nvTorchCam, its functionality, and present various code examples and diagrams to demonstrate its usage. Source code and installation instructions can be found on the nvTorchCam GitHub page at https://github.com/NVlabs/nvTorchCam.
FoVA-Depth: Field-of-View Agnostic Depth Estimation for Cross-Dataset Generalization
Jan 24, 2024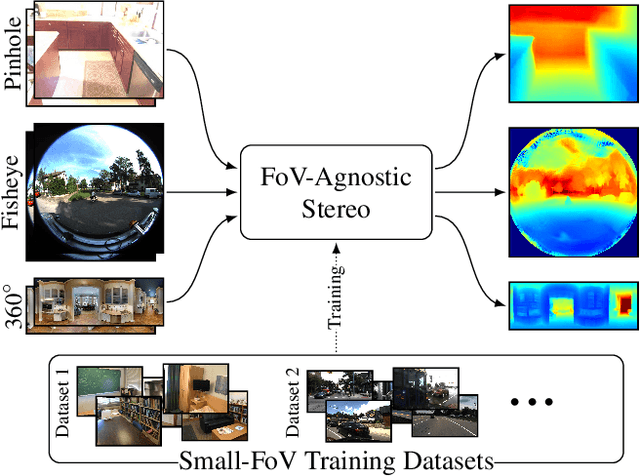

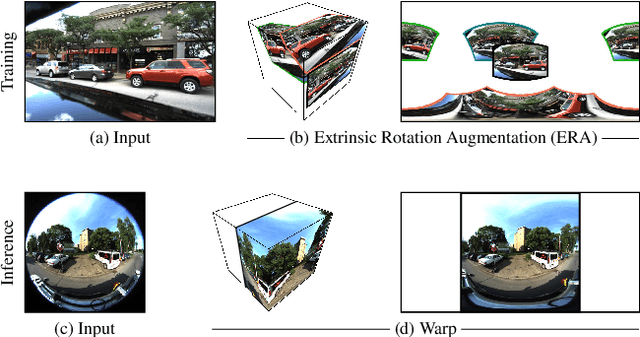
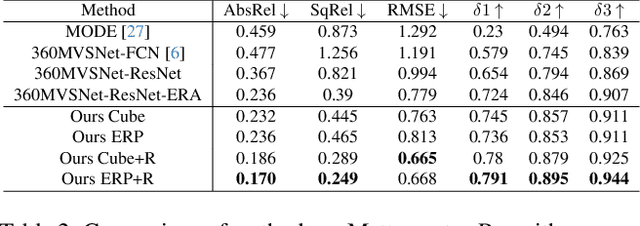
Wide field-of-view (FoV) cameras efficiently capture large portions of the scene, which makes them attractive in multiple domains, such as automotive and robotics. For such applications, estimating depth from multiple images is a critical task, and therefore, a large amount of ground truth (GT) data is available. Unfortunately, most of the GT data is for pinhole cameras, making it impossible to properly train depth estimation models for large-FoV cameras. We propose the first method to train a stereo depth estimation model on the widely available pinhole data, and to generalize it to data captured with larger FoVs. Our intuition is simple: We warp the training data to a canonical, large-FoV representation and augment it to allow a single network to reason about diverse types of distortions that otherwise would prevent generalization. We show strong generalization ability of our approach on both indoor and outdoor datasets, which was not possible with previous methods.
Zero-shot Pose Transfer for Unrigged Stylized 3D Characters
May 31, 2023



Transferring the pose of a reference avatar to stylized 3D characters of various shapes is a fundamental task in computer graphics. Existing methods either require the stylized characters to be rigged, or they use the stylized character in the desired pose as ground truth at training. We present a zero-shot approach that requires only the widely available deformed non-stylized avatars in training, and deforms stylized characters of significantly different shapes at inference. Classical methods achieve strong generalization by deforming the mesh at the triangle level, but this requires labelled correspondences. We leverage the power of local deformation, but without requiring explicit correspondence labels. We introduce a semi-supervised shape-understanding module to bypass the need for explicit correspondences at test time, and an implicit pose deformation module that deforms individual surface points to match the target pose. Furthermore, to encourage realistic and accurate deformation of stylized characters, we introduce an efficient volume-based test-time training procedure. Because it does not need rigging, nor the deformed stylized character at training time, our model generalizes to categories with scarce annotation, such as stylized quadrupeds. Extensive experiments demonstrate the effectiveness of the proposed method compared to the state-of-the-art approaches trained with comparable or more supervision. Our project page is available at https://jiashunwang.github.io/ZPT
Avatar Fingerprinting for Authorized Use of Synthetic Talking-Head Videos
May 05, 2023



Modern generators render talking-head videos with impressive levels of photorealism, ushering in new user experiences such as videoconferencing under constrained bandwidth budgets. Their safe adoption, however, requires a mechanism to verify if the rendered video is trustworthy. For instance, for videoconferencing we must identify cases in which a synthetic video portrait uses the appearance of an individual without their consent. We term this task avatar fingerprinting. We propose to tackle it by leveraging facial motion signatures unique to each person. Specifically, we learn an embedding in which the motion signatures of one identity are grouped together, and pushed away from those of other identities, regardless of the appearance in the synthetic video. Avatar fingerprinting algorithms will be critical as talking head generators become more ubiquitous, and yet no large scale datasets exist for this new task. Therefore, we contribute a large dataset of people delivering scripted and improvised short monologues, accompanied by synthetic videos in which we render videos of one person using the facial appearance of another. Project page: https://research.nvidia.com/labs/nxp/avatar-fingerprinting/.
Watch It Move: Unsupervised Discovery of 3D Joints for Re-Posing of Articulated Objects
Dec 21, 2021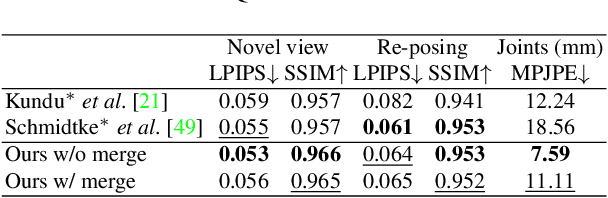
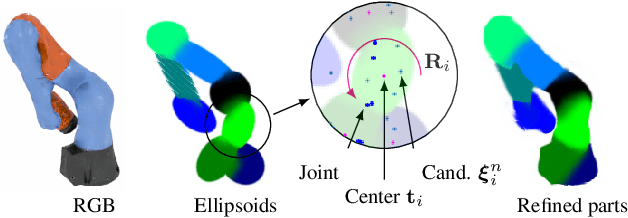
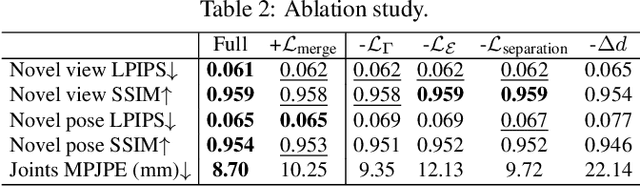
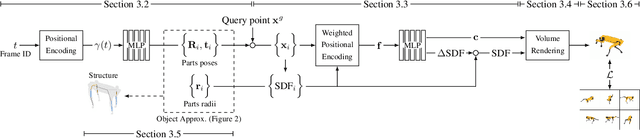
Rendering articulated objects while controlling their poses is critical to applications such as virtual reality or animation for movies. Manipulating the pose of an object, however, requires the understanding of its underlying structure, that is, its joints and how they interact with each other. Unfortunately, assuming the structure to be known, as existing methods do, precludes the ability to work on new object categories. We propose to learn both the appearance and the structure of previously unseen articulated objects by observing them move from multiple views, with no additional supervision, such as joints annotations, or information about the structure. Our insight is that adjacent parts that move relative to each other must be connected by a joint. To leverage this observation, we model the object parts in 3D as ellipsoids, which allows us to identify joints. We combine this explicit representation with an implicit one that compensates for the approximation introduced. We show that our method works for different structures, from quadrupeds, to single-arm robots, to humans.
Efficient Geometry-aware 3D Generative Adversarial Networks
Dec 15, 2021
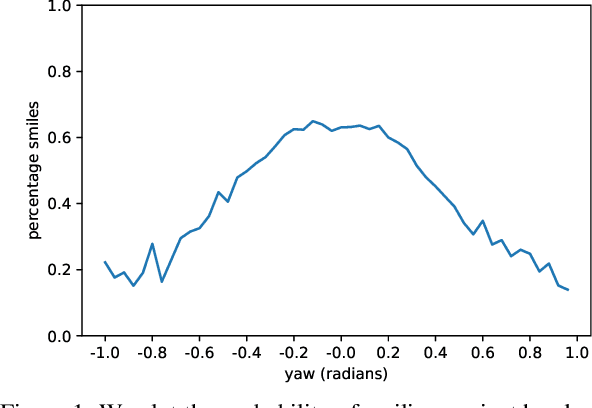
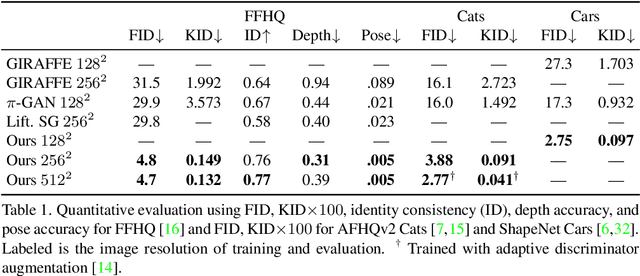
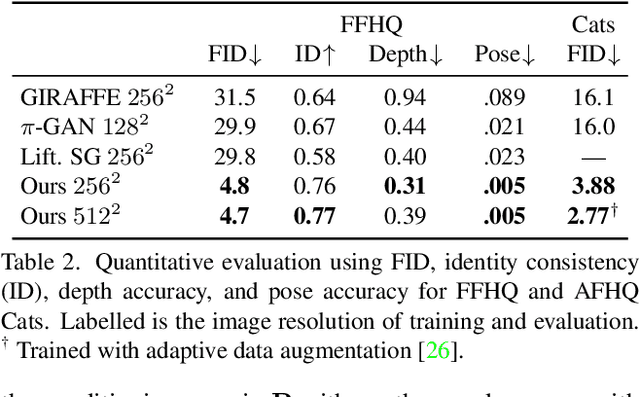
Unsupervised generation of high-quality multi-view-consistent images and 3D shapes using only collections of single-view 2D photographs has been a long-standing challenge. Existing 3D GANs are either compute-intensive or make approximations that are not 3D-consistent; the former limits quality and resolution of the generated images and the latter adversely affects multi-view consistency and shape quality. In this work, we improve the computational efficiency and image quality of 3D GANs without overly relying on these approximations. For this purpose, we introduce an expressive hybrid explicit-implicit network architecture that, together with other design choices, synthesizes not only high-resolution multi-view-consistent images in real time but also produces high-quality 3D geometry. By decoupling feature generation and neural rendering, our framework is able to leverage state-of-the-art 2D CNN generators, such as StyleGAN2, and inherit their efficiency and expressiveness. We demonstrate state-of-the-art 3D-aware synthesis with FFHQ and AFHQ Cats, among other experiments.
Neural Trajectory Fields for Dynamic Novel View Synthesis
May 12, 2021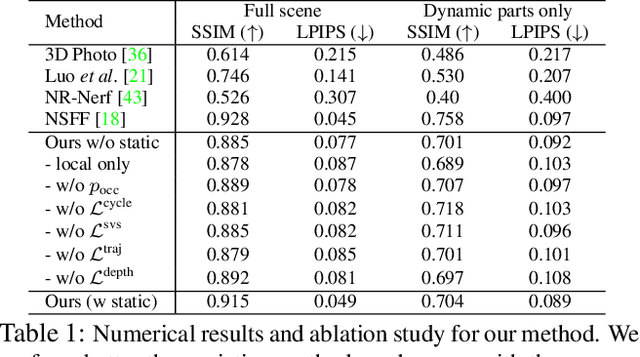
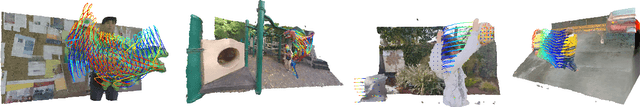
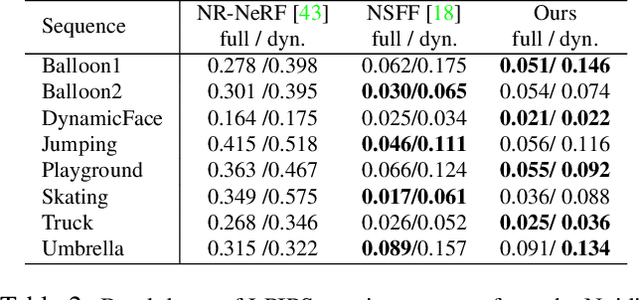
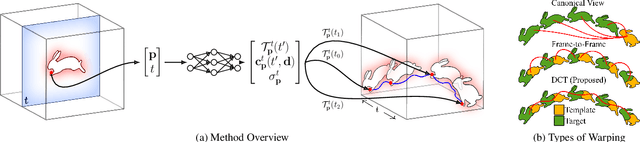
Recent approaches to render photorealistic views from a limited set of photographs have pushed the boundaries of our interactions with pictures of static scenes. The ability to recreate moments, that is, time-varying sequences, is perhaps an even more interesting scenario, but it remains largely unsolved. We introduce DCT-NeRF, a coordinatebased neural representation for dynamic scenes. DCTNeRF learns smooth and stable trajectories over the input sequence for each point in space. This allows us to enforce consistency between any two frames in the sequence, which results in high quality reconstruction, particularly in dynamic regions.
Noise-Aware Saliency Prediction for Videos with Incomplete Gaze Data
Apr 16, 2021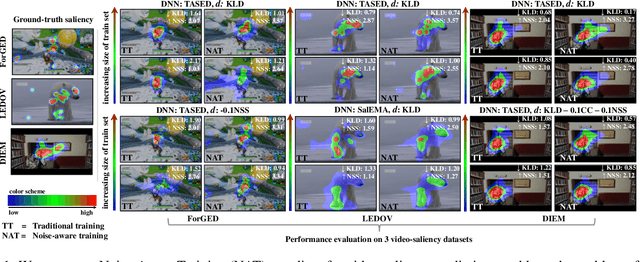
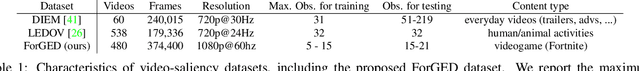
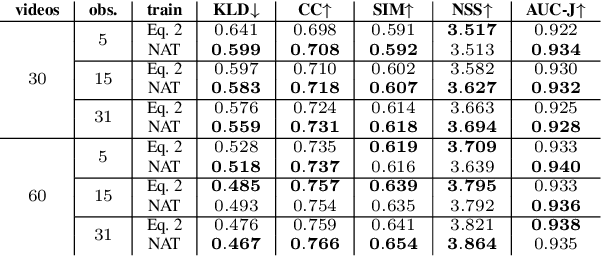

Deep-learning-based algorithms have led to impressive results in visual-saliency prediction, but the impact of noise in training gaze data has been largely overlooked. This issue is especially relevant for videos, where the gaze data tends to be incomplete, and thus noisier, compared to images. Therefore, we propose a noise-aware training (NAT) paradigm for visual-saliency prediction that quantifies the uncertainty arising from gaze data incompleteness and inaccuracy, and accounts for it in training. We demonstrate the advantage of NAT independently of the adopted model architecture, loss function, or training dataset. Given its robustness to the noise in incomplete training datasets, NAT ushers in the possibility of designing gaze datasets with fewer human subjects. We also introduce the first dataset that offers a video-game context for video-saliency research, with rich temporal semantics, and multiple gaze attractors per frame.