 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQUEEN: QUantized Efficient ENcoding of Dynamic Gaussians for Streaming Free-viewpoint Videos
Dec 05, 2024
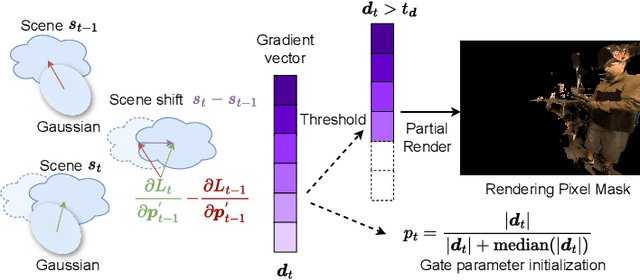


Online free-viewpoint video (FVV) streaming is a challenging problem, which is relatively under-explored. It requires incremental on-the-fly updates to a volumetric representation, fast training and rendering to satisfy real-time constraints and a small memory footprint for efficient transmission. If achieved, it can enhance user experience by enabling novel applications, e.g., 3D video conferencing and live volumetric video broadcast, among others. In this work, we propose a novel framework for QUantized and Efficient ENcoding (QUEEN) for streaming FVV using 3D Gaussian Splatting (3D-GS). QUEEN directly learns Gaussian attribute residuals between consecutive frames at each time-step without imposing any structural constraints on them, allowing for high quality reconstruction and generalizability. To efficiently store the residuals, we further propose a quantization-sparsity framework, which contains a learned latent-decoder for effectively quantizing attribute residuals other than Gaussian positions and a learned gating module to sparsify position residuals. We propose to use the Gaussian viewspace gradient difference vector as a signal to separate the static and dynamic content of the scene. It acts as a guide for effective sparsity learning and speeds up training. On diverse FVV benchmarks, QUEEN outperforms the state-of-the-art online FVV methods on all metrics. Notably, for several highly dynamic scenes, it reduces the model size to just 0.7 MB per frame while training in under 5 sec and rendering at 350 FPS. Project website is at https://research.nvidia.com/labs/amri/projects/queen
Avatar Fingerprinting for Authorized Use of Synthetic Talking-Head Videos
May 05, 2023



Modern generators render talking-head videos with impressive levels of photorealism, ushering in new user experiences such as videoconferencing under constrained bandwidth budgets. Their safe adoption, however, requires a mechanism to verify if the rendered video is trustworthy. For instance, for videoconferencing we must identify cases in which a synthetic video portrait uses the appearance of an individual without their consent. We term this task avatar fingerprinting. We propose to tackle it by leveraging facial motion signatures unique to each person. Specifically, we learn an embedding in which the motion signatures of one identity are grouped together, and pushed away from those of other identities, regardless of the appearance in the synthetic video. Avatar fingerprinting algorithms will be critical as talking head generators become more ubiquitous, and yet no large scale datasets exist for this new task. Therefore, we contribute a large dataset of people delivering scripted and improvised short monologues, accompanied by synthetic videos in which we render videos of one person using the facial appearance of another. Project page: https://research.nvidia.com/labs/nxp/avatar-fingerprinting/.
Gaze-Sensing LEDs for Head Mounted Displays
Mar 18, 2020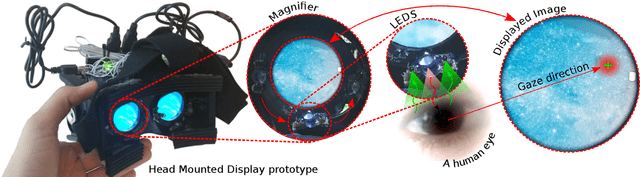

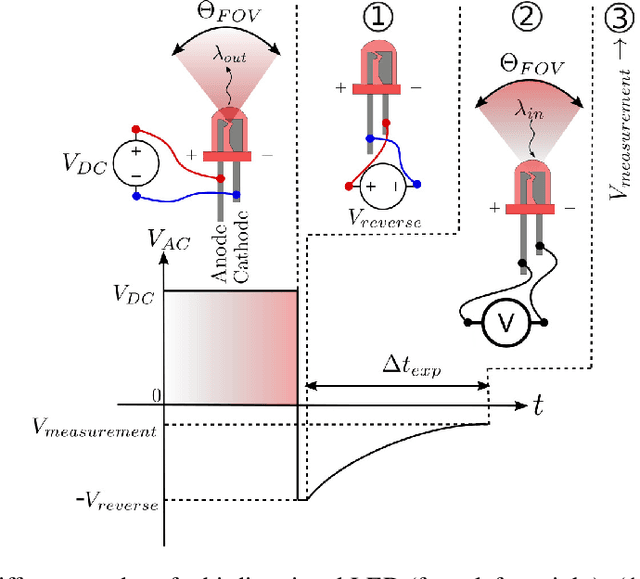
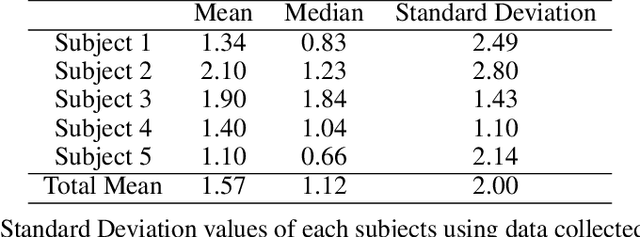
We introduce a new gaze tracker for Head Mounted Displays (HMDs). We modify two off-the-shelf HMDs to be gaze-aware using Light Emitting Diodes (LEDs). Our key contribution is to exploit the sensing capability of LEDs to create low-power gaze tracker for virtual reality (VR) applications. This yields a simple approach using minimal hardware to achieve good accuracy and low latency using light-weight supervised Gaussian Process Regression (GPR) running on a mobile device. With our hardware, we show that Minkowski distance measure based GPR implementation outperforms the commonly used radial basis function-based support vector regression (SVR) without the need to precisely determine free parameters. We show that our gaze estimation method does not require complex dimension reduction techniques, feature extraction, or distortion corrections due to off-axis optical paths. We demonstrate two complete HMD prototypes with a sample eye-tracked application, and report on a series of subjective tests using our prototypes.
Toward Standardized Classification of Foveated Displays
May 03, 2019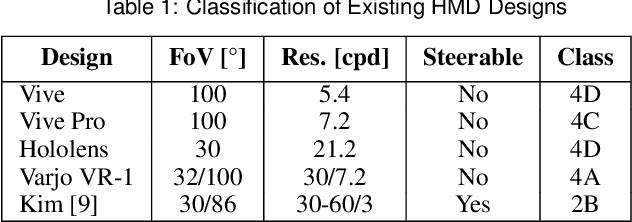
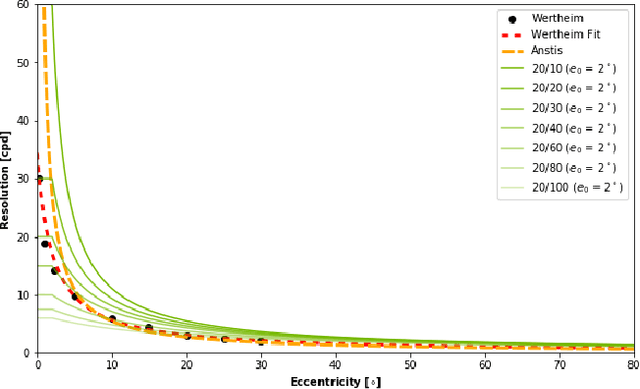
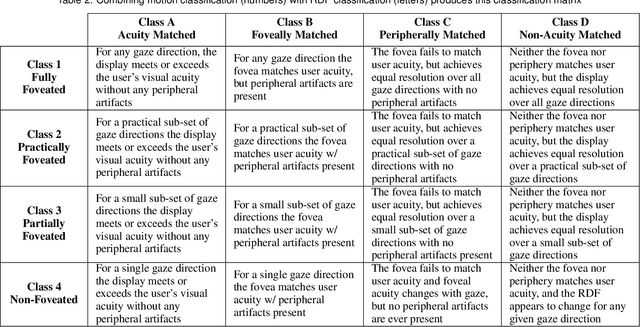

Emergent in the field of head mounted display design is a desire to leverage the limitations of the human visual system to reduce the computation, communication, and display workload in power and form-factor constrained systems. Fundamental to this reduced workload is the ability to match display resolution to the acuity of the human visual system, along with a resulting need to follow the gaze of the eye as it moves, a process referred to as foveation. A display that moves its content along with the eye may be called a Foveated Display, though this term is also commonly used to describe displays with non-uniform resolution that attempt to mimic human visual acuity. We therefore recommend a definition for the term Foveated Display that accepts both of these interpretations. Furthermore, we include a simplified model for human visual Acuity Distribution Functions (ADFs) at various levels of visual acuity, across wide fields of view and propose comparison of this ADF with the Resolution Distribution Function of a foveated display for evaluation of its resolution at a particular gaze direction. We also provide a taxonomy to allow the field to meaningfully compare and contrast various aspects of foveated displays in a display and optical technology-agnostic manner.