 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearth Transformer: A Transformer Architecture Incorporating Earth's Geospheric Physical Priors for Global Mid-Range Weather Forecasting
Jan 14, 2026Accurate global medium-range weather forecasting is fundamental to Earth system science. Most existing Transformer-based forecasting models adopt vision-centric architectures that neglect the Earth's spherical geometry and zonal periodicity. In addition, conventional autoregressive training is computationally expensive and limits forecast horizons due to error accumulation. To address these challenges, we propose the Shifted Earth Transformer (Searth Transformer), a physics-informed architecture that incorporates zonal periodicity and meridional boundaries into window-based self-attention for physically consistent global information exchange. We further introduce a Relay Autoregressive (RAR) fine-tuning strategy that enables learning long-range atmospheric evolution under constrained memory and computational budgets. Based on these methods, we develop YanTian, a global medium-range weather forecasting model. YanTian achieves higher accuracy than the high-resolution forecast of the European Centre for Medium-Range Weather Forecasts and performs competitively with state-of-the-art AI models at one-degree resolution, while requiring roughly 200 times lower computational cost than standard autoregressive fine-tuning. Furthermore, YanTian attains a longer skillful forecast lead time for Z500 (10.3 days) than HRES (9 days). Beyond weather forecasting, this work establishes a robust algorithmic foundation for predictive modeling of complex global-scale geophysical circulation systems, offering new pathways for Earth system science.
GeoMan: Temporally Consistent Human Geometry Estimation using Image-to-Video Diffusion
May 29, 2025Estimating accurate and temporally consistent 3D human geometry from videos is a challenging problem in computer vision. Existing methods, primarily optimized for single images, often suffer from temporal inconsistencies and fail to capture fine-grained dynamic details. To address these limitations, we present GeoMan, a novel architecture designed to produce accurate and temporally consistent depth and normal estimations from monocular human videos. GeoMan addresses two key challenges: the scarcity of high-quality 4D training data and the need for metric depth estimation to accurately model human size. To overcome the first challenge, GeoMan employs an image-based model to estimate depth and normals for the first frame of a video, which then conditions a video diffusion model, reframing video geometry estimation task as an image-to-video generation problem. This design offloads the heavy lifting of geometric estimation to the image model and simplifies the video model's role to focus on intricate details while using priors learned from large-scale video datasets. Consequently, GeoMan improves temporal consistency and generalizability while requiring minimal 4D training data. To address the challenge of accurate human size estimation, we introduce a root-relative depth representation that retains critical human-scale details and is easier to be estimated from monocular inputs, overcoming the limitations of traditional affine-invariant and metric depth representations. GeoMan achieves state-of-the-art performance in both qualitative and quantitative evaluations, demonstrating its effectiveness in overcoming longstanding challenges in 3D human geometry estimation from videos.
BLADE: Single-view Body Mesh Learning through Accurate Depth Estimation
Dec 11, 2024



Single-image human mesh recovery is a challenging task due to the ill-posed nature of simultaneous body shape, pose, and camera estimation. Existing estimators work well on images taken from afar, but they break down as the person moves close to the camera. Moreover, current methods fail to achieve both accurate 3D pose and 2D alignment at the same time. Error is mainly introduced by inaccurate perspective projection heuristically derived from orthographic parameters. To resolve this long-standing challenge, we present our method BLADE which accurately recovers perspective parameters from a single image without heuristic assumptions. We start from the inverse relationship between perspective distortion and the person's Z-translation Tz, and we show that Tz can be reliably estimated from the image. We then discuss the important role of Tz for accurate human mesh recovery estimated from close-range images. Finally, we show that, once Tz and the 3D human mesh are estimated, one can accurately recover the focal length and full 3D translation. Extensive experiments on standard benchmarks and real-world close-range images show that our method is the first to accurately recover projection parameters from a single image, and consequently attain state-of-the-art accuracy on 3D pose estimation and 2D alignment for a wide range of images. https://research.nvidia.com/labs/amri/projects/blade/
QUEEN: QUantized Efficient ENcoding of Dynamic Gaussians for Streaming Free-viewpoint Videos
Dec 05, 2024
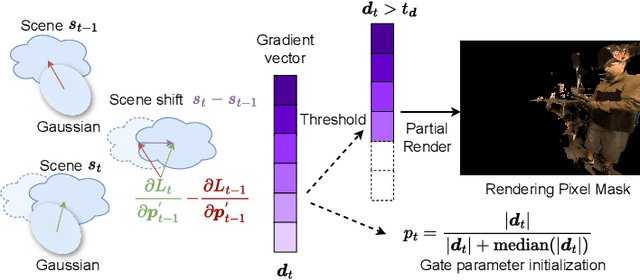


Online free-viewpoint video (FVV) streaming is a challenging problem, which is relatively under-explored. It requires incremental on-the-fly updates to a volumetric representation, fast training and rendering to satisfy real-time constraints and a small memory footprint for efficient transmission. If achieved, it can enhance user experience by enabling novel applications, e.g., 3D video conferencing and live volumetric video broadcast, among others. In this work, we propose a novel framework for QUantized and Efficient ENcoding (QUEEN) for streaming FVV using 3D Gaussian Splatting (3D-GS). QUEEN directly learns Gaussian attribute residuals between consecutive frames at each time-step without imposing any structural constraints on them, allowing for high quality reconstruction and generalizability. To efficiently store the residuals, we further propose a quantization-sparsity framework, which contains a learned latent-decoder for effectively quantizing attribute residuals other than Gaussian positions and a learned gating module to sparsify position residuals. We propose to use the Gaussian viewspace gradient difference vector as a signal to separate the static and dynamic content of the scene. It acts as a guide for effective sparsity learning and speeds up training. On diverse FVV benchmarks, QUEEN outperforms the state-of-the-art online FVV methods on all metrics. Notably, for several highly dynamic scenes, it reduces the model size to just 0.7 MB per frame while training in under 5 sec and rendering at 350 FPS. Project website is at https://research.nvidia.com/labs/amri/projects/queen
YanTian: An Application Platform for AI Global Weather Forecasting Models
Oct 06, 2024



To promote the practical application of AI Global Weather Forecasting Models (AIGWFM), we have developed an adaptable application platform named 'YanTian'. This platform enhances existing open-source AIGWFM with a suite of capability-enhancing modules and is constructed by a "loosely coupled" plug-in architecture. The goal of 'YanTian' is to address the limitations of current open-source AIGWFM in operational application, including improving local forecast accuracy, providing spatial high-resolution forecasts, increasing density of forecast intervals, and generating diverse products with the provision of AIGC capabilities. 'YianTian' also provides a simple, visualized user interface, allowing meteorologists easily access both basic and extended capabilities of the platform by simply configuring the platform UI. Users do not need to possess the complex artificial intelligence knowledge and the coding techniques. Additionally, 'YianTian' can be deployed on a PC with GPUs. We hope 'YianTian' can facilitate the operational widespread adoption of AIGWFMs.
Instant Multi-View Head Capture through Learnable Registration
Jun 12, 2023


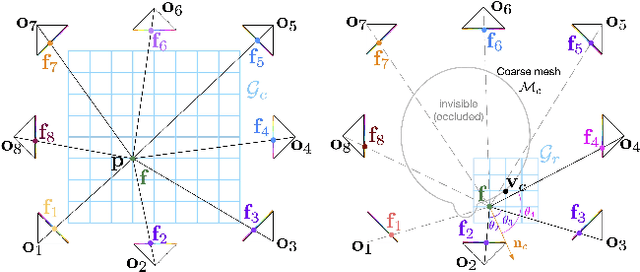
Existing methods for capturing datasets of 3D heads in dense semantic correspondence are slow, and commonly address the problem in two separate steps; multi-view stereo (MVS) reconstruction followed by non-rigid registration. To simplify this process, we introduce TEMPEH (Towards Estimation of 3D Meshes from Performances of Expressive Heads) to directly infer 3D heads in dense correspondence from calibrated multi-view images. Registering datasets of 3D scans typically requires manual parameter tuning to find the right balance between accurately fitting the scans surfaces and being robust to scanning noise and outliers. Instead, we propose to jointly register a 3D head dataset while training TEMPEH. Specifically, during training we minimize a geometric loss commonly used for surface registration, effectively leveraging TEMPEH as a regularizer. Our multi-view head inference builds on a volumetric feature representation that samples and fuses features from each view using camera calibration information. To account for partial occlusions and a large capture volume that enables head movements, we use view- and surface-aware feature fusion, and a spatial transformer-based head localization module, respectively. We use raw MVS scans as supervision during training, but, once trained, TEMPEH directly predicts 3D heads in dense correspondence without requiring scans. Predicting one head takes about 0.3 seconds with a median reconstruction error of 0.26 mm, 64% lower than the current state-of-the-art. This enables the efficient capture of large datasets containing multiple people and diverse facial motions. Code, model, and data are publicly available at https://tempeh.is.tue.mpg.de.
Topologically Consistent Multi-View Face Inference Using Volumetric Sampling
Oct 06, 2021High-fidelity face digitization solutions often combine multi-view stereo (MVS) techniques for 3D reconstruction and a non-rigid registration step to establish dense correspondence across identities and expressions. A common problem is the need for manual clean-up after the MVS step, as 3D scans are typically affected by noise and outliers and contain hairy surface regions that need to be cleaned up by artists. Furthermore, mesh registration tends to fail for extreme facial expressions. Most learning-based methods use an underlying 3D morphable model (3DMM) to ensure robustness, but this limits the output accuracy for extreme facial expressions. In addition, the global bottleneck of regression architectures cannot produce meshes that tightly fit the ground truth surfaces. We propose ToFu, Topologically consistent Face from multi-view, a geometry inference framework that can produce topologically consistent meshes across facial identities and expressions using a volumetric representation instead of an explicit underlying 3DMM. Our novel progressive mesh generation network embeds the topological structure of the face in a feature volume, sampled from geometry-aware local features. A coarse-to-fine architecture facilitates dense and accurate facial mesh predictions in a consistent mesh topology. ToFu further captures displacement maps for pore-level geometric details and facilitates high-quality rendering in the form of albedo and specular reflectance maps. These high-quality assets are readily usable by production studios for avatar creation, animation and physically-based skin rendering. We demonstrate state-of-the-art geometric and correspondence accuracy, while only taking 0.385 seconds to compute a mesh with 10K vertices, which is three orders of magnitude faster than traditional techniques. The code and the model are available for research purposes at https://tianyeli.github.io/tofu.
Neural 3D Video Synthesis
Mar 03, 2021



We propose a novel approach for 3D video synthesis that is able to represent multi-view video recordings of a dynamic real-world scene in a compact, yet expressive representation that enables high-quality view synthesis and motion interpolation. Our approach takes the high quality and compactness of static neural radiance fields in a new direction: to a model-free, dynamic setting. At the core of our approach is a novel time-conditioned neural radiance fields that represents scene dynamics using a set of compact latent codes. To exploit the fact that changes between adjacent frames of a video are typically small and locally consistent, we propose two novel strategies for efficient training of our neural network: 1) An efficient hierarchical training scheme, and 2) an importance sampling strategy that selects the next rays for training based on the temporal variation of the input videos. In combination, these two strategies significantly boost the training speed, lead to fast convergence of the training process, and enable high quality results. Our learned representation is highly compact and able to represent a 10 second 30 FPS multi-view video recording by 18 cameras with a model size of just 28MB. We demonstrate that our method can render high-fidelity wide-angle novel views at over 1K resolution, even for highly complex and dynamic scenes. We perform an extensive qualitative and quantitative evaluation that shows that our approach outperforms the current state of the art. We include additional video and information at: https://neural-3d-video.github.io/
Learning Perspective Undistortion of Portraits
May 18, 2019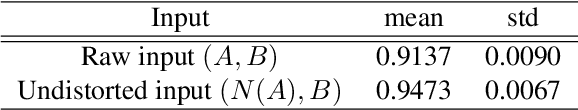



Near-range portrait photographs often contain perspective distortion artifacts that bias human perception and challenge both facial recognition and reconstruction techniques. We present the first deep learning based approach to remove such artifacts from unconstrained portraits. In contrast to the previous state-of-the-art approach, our method handles even portraits with extreme perspective distortion, as we avoid the inaccurate and error-prone step of first fitting a 3D face model. Instead, we predict a distortion correction flow map that encodes a per-pixel displacement that removes distortion artifacts when applied to the input image. Our method also automatically infers missing facial features, i.e. occluded ears caused by strong perspective distortion, with coherent details. We demonstrate that our approach significantly outperforms the previous state-of-the-art both qualitatively and quantitatively, particularly for portraits with extreme perspective distortion or facial expressions. We further show that our technique benefits a number of fundamental tasks, significantly improving the accuracy of both face recognition and 3D reconstruction and enables a novel camera calibration technique from a single portrait. Moreover, we also build the first perspective portrait database with a large diversity in identities, expression and poses, which will benefit the related research in this area.
Soft Rasterizer: A Differentiable Renderer for Image-based 3D Reasoning
Apr 03, 2019



Rendering bridges the gap between 2D vision and 3D scenes by simulating the physical process of image formation. By inverting such renderer, one can think of a learning approach to infer 3D information from 2D images. However, standard graphics renderers involve a fundamental discretization step called rasterization, which prevents the rendering process to be differentiable, hence able to be learned. Unlike the state-of-the-art differentiable renderers, which only approximate the rendering gradient in the back propagation, we propose a truly differentiable rendering framework that is able to (1) directly render colorized mesh using differentiable functions and (2) back-propagate efficient supervision signals to mesh vertices and their attributes from various forms of image representations, including silhouette, shading and color images. The key to our framework is a novel formulation that views rendering as an aggregation function that fuses the probabilistic contributions of all mesh triangles with respect to the rendered pixels. Such formulation enables our framework to flow gradients to the occluded and far-range vertices, which cannot be achieved by the previous state-of-the-arts. We show that by using the proposed renderer, one can achieve significant improvement in 3D unsupervised single-view reconstruction both qualitatively and quantitatively. Experiments also demonstrate that our approach is able to handle the challenging tasks in image-based shape fitting, which remain nontrivial to existing differentiable renderers.