 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Virtual Human Gesture Selection
Mar 18, 2025Co-speech gestures convey a wide variety of meanings and play an important role in face-to-face human interactions. These gestures significantly influence the addressee's engagement, recall, comprehension, and attitudes toward the speaker. Similarly, they impact interactions between humans and embodied virtual agents. The process of selecting and animating meaningful gestures has thus become a key focus in the design of these agents. However, automating this gesture selection process poses a significant challenge. Prior gesture generation techniques have varied from fully automated, data-driven methods, which often struggle to produce contextually meaningful gestures, to more manual approaches that require crafting specific gesture expertise and are time-consuming and lack generalizability. In this paper, we leverage the semantic capabilities of Large Language Models to develop a gesture selection approach that suggests meaningful, appropriate co-speech gestures. We first describe how information on gestures is encoded into GPT-4. Then, we conduct a study to evaluate alternative prompting approaches for their ability to select meaningful, contextually relevant gestures and to align them appropriately with the co-speech utterance. Finally, we detail and demonstrate how this approach has been implemented within a virtual agent system, automating the selection and subsequent animation of the selected gestures for enhanced human-agent interactions.
Study of detecting behavioral signatures within DeepFake videos
Aug 06, 2022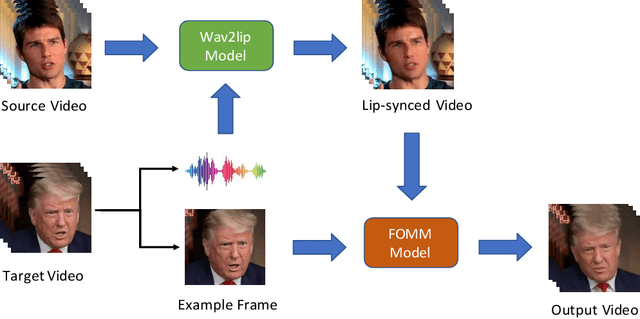
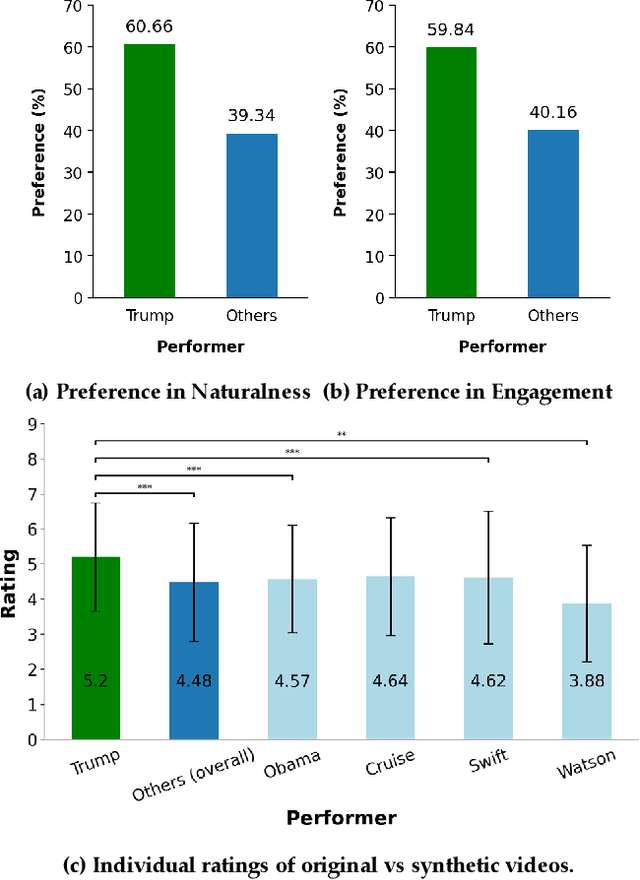
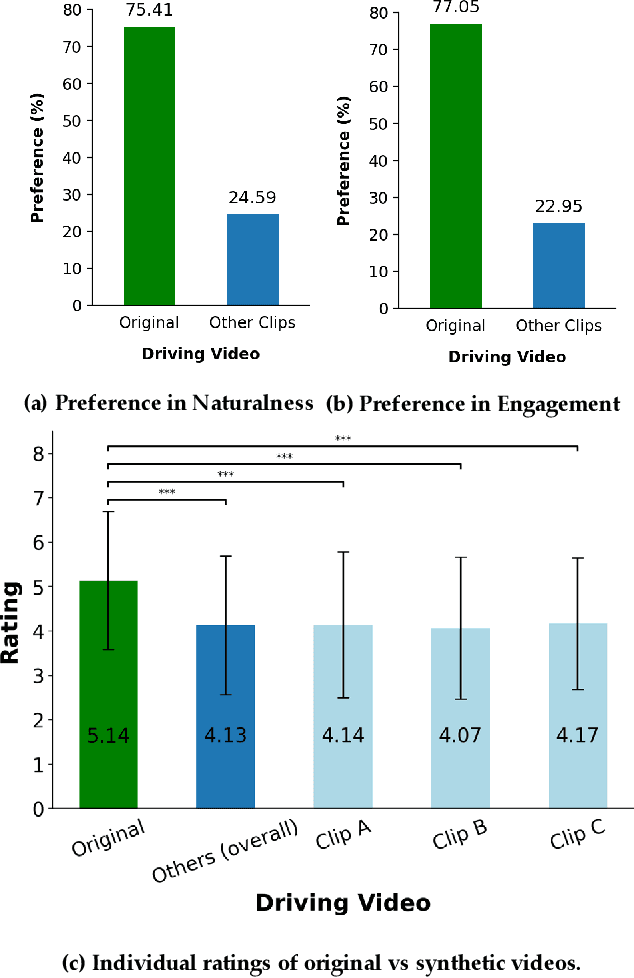

There is strong interest in the generation of synthetic video imagery of people talking for various purposes, including entertainment, communication, training, and advertisement. With the development of deep fake generation models, synthetic video imagery will soon be visually indistinguishable to the naked eye from a naturally capture video. In addition, many methods are continuing to improve to avoid more careful, forensic visual analysis. Some deep fake videos are produced through the use of facial puppetry, which directly controls the head and face of the synthetic image through the movements of the actor, allow the actor to 'puppet' the image of another. In this paper, we address the question of whether one person's movements can be distinguished from the original speaker by controlling the visual appearance of the speaker but transferring the behavior signals from another source. We conduct a study by comparing synthetic imagery that: 1) originates from a different person speaking a different utterance, 2) originates from the same person speaking a different utterance, and 3) originates from a different person speaking the same utterance. Our study shows that synthetic videos in all three cases are seen as less real and less engaging than the original source video. Our results indicate that there could be a behavioral signature that is detectable from a person's movements that is separate from their visual appearance, and that this behavioral signature could be used to distinguish a deep fake from a properly captured video.
Learning Perspective Undistortion of Portraits
May 18, 2019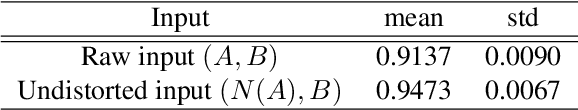



Near-range portrait photographs often contain perspective distortion artifacts that bias human perception and challenge both facial recognition and reconstruction techniques. We present the first deep learning based approach to remove such artifacts from unconstrained portraits. In contrast to the previous state-of-the-art approach, our method handles even portraits with extreme perspective distortion, as we avoid the inaccurate and error-prone step of first fitting a 3D face model. Instead, we predict a distortion correction flow map that encodes a per-pixel displacement that removes distortion artifacts when applied to the input image. Our method also automatically infers missing facial features, i.e. occluded ears caused by strong perspective distortion, with coherent details. We demonstrate that our approach significantly outperforms the previous state-of-the-art both qualitatively and quantitatively, particularly for portraits with extreme perspective distortion or facial expressions. We further show that our technique benefits a number of fundamental tasks, significantly improving the accuracy of both face recognition and 3D reconstruction and enables a novel camera calibration technique from a single portrait. Moreover, we also build the first perspective portrait database with a large diversity in identities, expression and poses, which will benefit the related research in this area.