 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Refined VQA Annotations for Semi-Supervised Gaze Following
Jun 04, 2024Training gaze following models requires a large number of images with gaze target coordinates annotated by human annotators, which is a laborious and inherently ambiguous process. We propose the first semi-supervised method for gaze following by introducing two novel priors to the task. We obtain the first prior using a large pretrained Visual Question Answering (VQA) model, where we compute Grad-CAM heatmaps by `prompting' the VQA model with a gaze following question. These heatmaps can be noisy and not suited for use in training. The need to refine these noisy annotations leads us to incorporate a second prior. We utilize a diffusion model trained on limited human annotations and modify the reverse sampling process to refine the Grad-CAM heatmaps. By tuning the diffusion process we achieve a trade-off between the human annotation prior and the VQA heatmap prior, which retains the useful VQA prior information while exhibiting similar properties to the training data distribution. Our method outperforms simple pseudo-annotation generation baselines on the GazeFollow image dataset. More importantly, our pseudo-annotation strategy, applied to a widely used supervised gaze following model (VAT), reduces the annotation need by 50%. Our method also performs the best on the VideoAttentionTarget dataset.
Patch-level Gaze Distribution Prediction for Gaze Following
Nov 20, 2022



Gaze following aims to predict where a person is looking in a scene, by predicting the target location, or indicating that the target is located outside the image. Recent works detect the gaze target by training a heatmap regression task with a pixel-wise mean-square error (MSE) loss, while formulating the in/out prediction task as a binary classification task. This training formulation puts a strict, pixel-level constraint in higher resolution on the single annotation available in training, and does not consider annotation variance and the correlation between the two subtasks. To address these issues, we introduce the patch distribution prediction (PDP) method. We replace the in/out prediction branch in previous models with the PDP branch, by predicting a patch-level gaze distribution that also considers the outside cases. Experiments show that our model regularizes the MSE loss by predicting better heatmap distributions on images with larger annotation variances, meanwhile bridging the gap between the target prediction and in/out prediction subtasks, showing a significant improvement in performance on both subtasks on public gaze following datasets.
Study of detecting behavioral signatures within DeepFake videos
Aug 06, 2022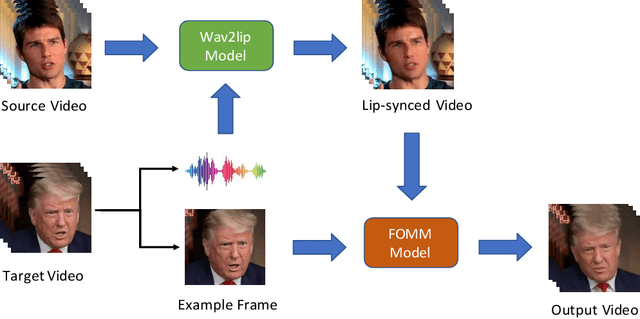
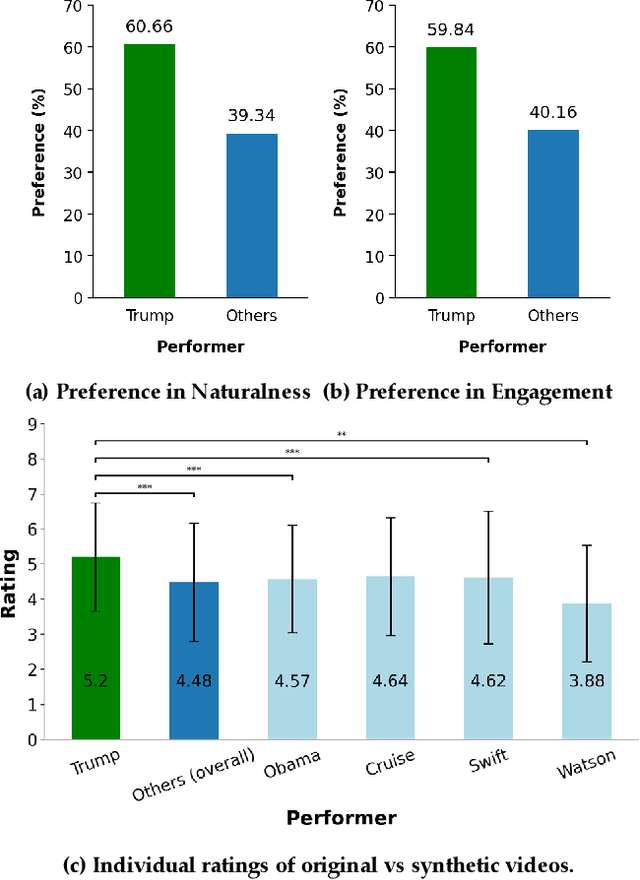
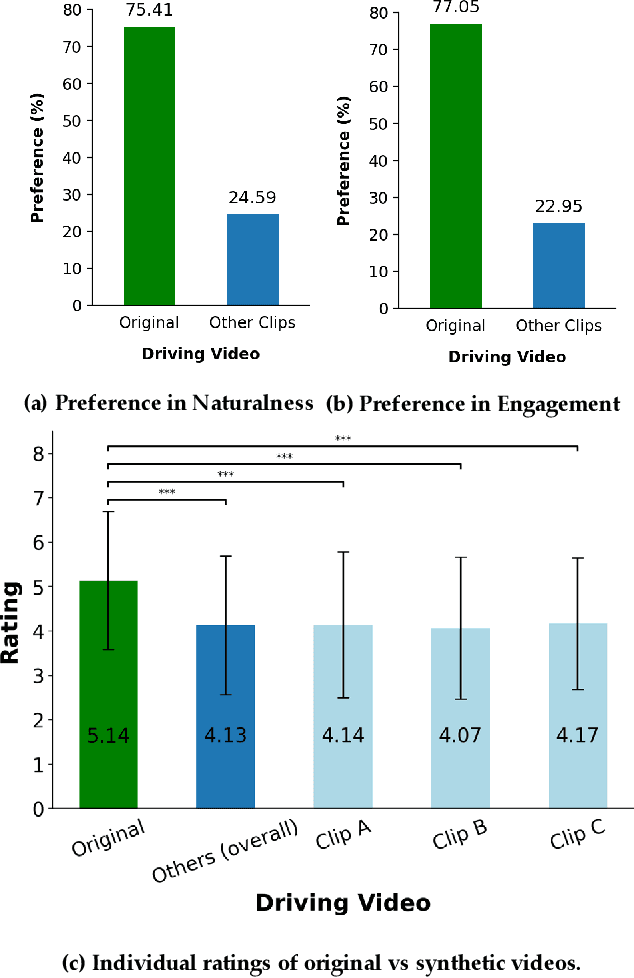

There is strong interest in the generation of synthetic video imagery of people talking for various purposes, including entertainment, communication, training, and advertisement. With the development of deep fake generation models, synthetic video imagery will soon be visually indistinguishable to the naked eye from a naturally capture video. In addition, many methods are continuing to improve to avoid more careful, forensic visual analysis. Some deep fake videos are produced through the use of facial puppetry, which directly controls the head and face of the synthetic image through the movements of the actor, allow the actor to 'puppet' the image of another. In this paper, we address the question of whether one person's movements can be distinguished from the original speaker by controlling the visual appearance of the speaker but transferring the behavior signals from another source. We conduct a study by comparing synthetic imagery that: 1) originates from a different person speaking a different utterance, 2) originates from the same person speaking a different utterance, and 3) originates from a different person speaking the same utterance. Our study shows that synthetic videos in all three cases are seen as less real and less engaging than the original source video. Our results indicate that there could be a behavioral signature that is detectable from a person's movements that is separate from their visual appearance, and that this behavioral signature could be used to distinguish a deep fake from a properly captured video.