 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClimate Implications of Diffusion-based Generative Visual AI Systems and their Mass Adoption
May 24, 2025Climate implications of rapidly developing digital technologies, such as blockchains and the associated crypto mining and NFT minting, have been well documented and their massive GPU energy use has been identified as a cause for concern. However, we postulate that due to their more mainstream consumer appeal, the GPU use of text-prompt based diffusion AI art systems also requires thoughtful considerations. Given the recent explosion in the number of highly sophisticated generative art systems and their rapid adoption by consumers and creative professionals, the impact of these systems on the climate needs to be carefully considered. In this work, we report on the growth of diffusion-based visual AI systems, their patterns of use, growth and the implications on the climate. Our estimates show that the mass adoption of these tools potentially contributes considerably to global energy consumption. We end this paper with our thoughts on solutions and future areas of inquiry as well as associated difficulties, including the lack of publicly available data.
Digital Overconsumption and Waste: A Closer Look at the Impacts of Generative AI
May 24, 2025Generative Artificial Intelligence (AI) systems currently contribute negatively to the production of digital waste, via the associated energy consumption and the related CO2 emissions. At this moment, a discussion is urgently needed on the replication of harmful consumer behavior, such as overconsumption, in the digital space. We outline our previous work on the climate implications of commercially available generative AI systems and the sentiment of generative AI users when confronted with AI-related climate research. We expand on this work via a discussion of digital overconsumption and waste, other related societal impacts, and a possible solution pathway
Exploring Augmentation and Cognitive Strategies for AI based Synthetic Personae
Apr 16, 2024
Large language models (LLMs) hold potential for innovative HCI research, including the creation of synthetic personae. However, their black-box nature and propensity for hallucinations pose challenges. To address these limitations, this position paper advocates for using LLMs as data augmentation systems rather than zero-shot generators. We further propose the development of robust cognitive and memory frameworks to guide LLM responses. Initial explorations suggest that data enrichment, episodic memory, and self-reflection techniques can improve the reliability of synthetic personae and open up new avenues for HCI research.
Study of detecting behavioral signatures within DeepFake videos
Aug 06, 2022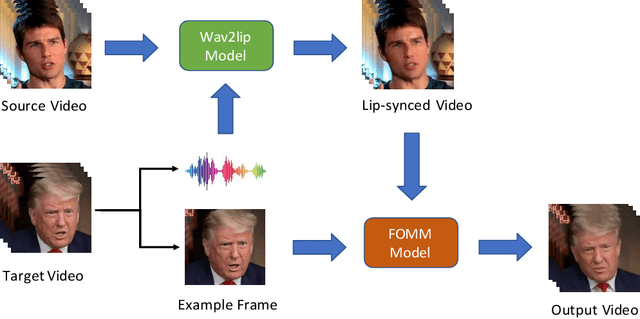
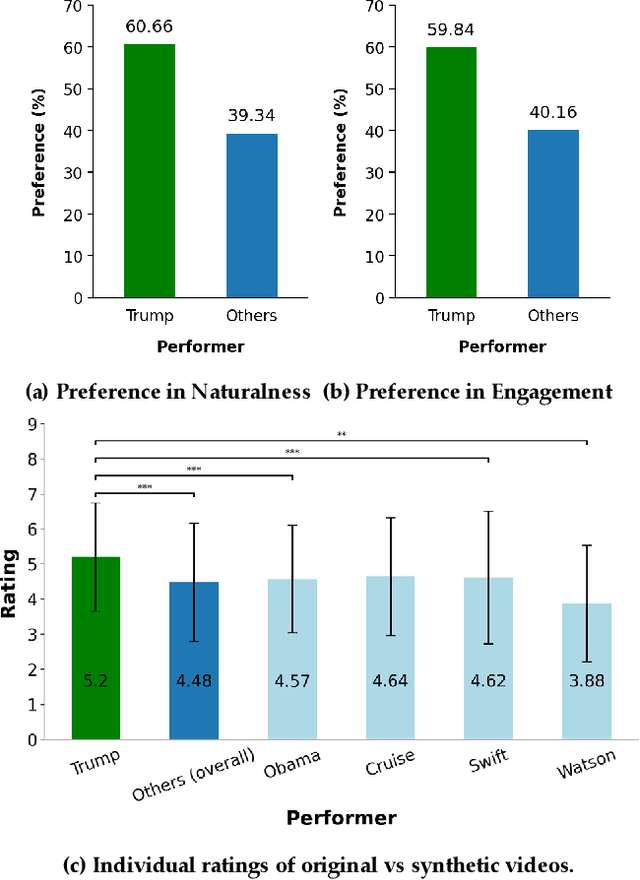
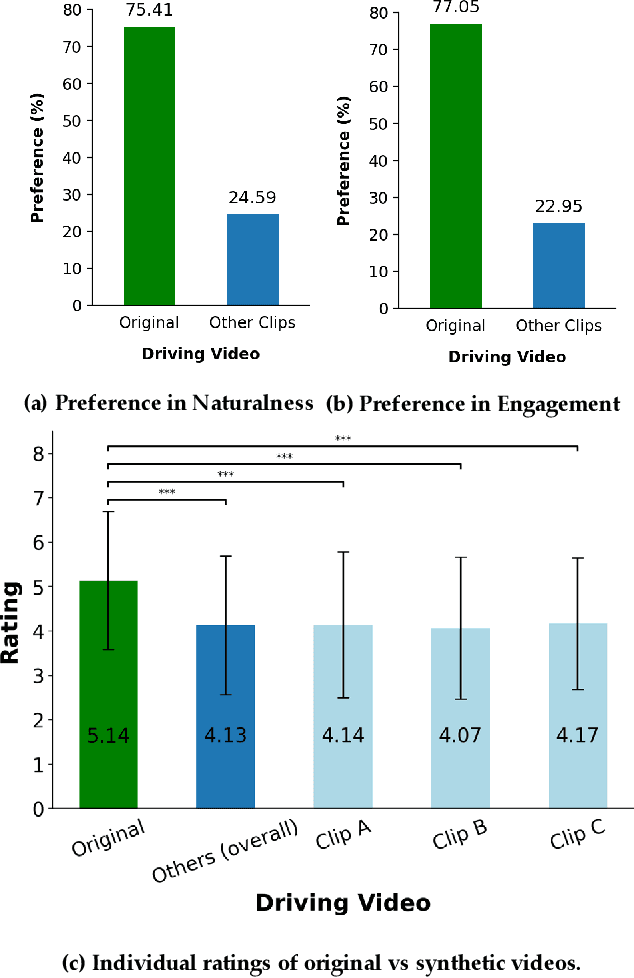

There is strong interest in the generation of synthetic video imagery of people talking for various purposes, including entertainment, communication, training, and advertisement. With the development of deep fake generation models, synthetic video imagery will soon be visually indistinguishable to the naked eye from a naturally capture video. In addition, many methods are continuing to improve to avoid more careful, forensic visual analysis. Some deep fake videos are produced through the use of facial puppetry, which directly controls the head and face of the synthetic image through the movements of the actor, allow the actor to 'puppet' the image of another. In this paper, we address the question of whether one person's movements can be distinguished from the original speaker by controlling the visual appearance of the speaker but transferring the behavior signals from another source. We conduct a study by comparing synthetic imagery that: 1) originates from a different person speaking a different utterance, 2) originates from the same person speaking a different utterance, and 3) originates from a different person speaking the same utterance. Our study shows that synthetic videos in all three cases are seen as less real and less engaging than the original source video. Our results indicate that there could be a behavioral signature that is detectable from a person's movements that is separate from their visual appearance, and that this behavioral signature could be used to distinguish a deep fake from a properly captured video.
Empathic AI Painter: A Computational Creativity System with Embodied Conversational Interaction
May 28, 2020



There is a growing recognition that artists use valuable ways to understand and work with cognitive and perceptual mechanisms to convey desired experiences and narrative in their created artworks (DiPaola et al., 2010; Zeki, 2001). This paper documents our attempt to computationally model the creative process of a portrait painter, who relies on understanding human traits (i.e., personality and emotions) to inform their art. Our system includes an empathic conversational interaction component to capture the dominant personality category of the user and a generative AI Portraiture system that uses this categorization to create a personalized stylization of the user's portrait. This paper includes the description of our systems and the real-time interaction results obtained during the demonstration session of the NeurIPS 2019 Conference.
Using an AI creativity system to explore how aesthetic experiences are processed along the brains perceptual neural pathways
Sep 15, 2019
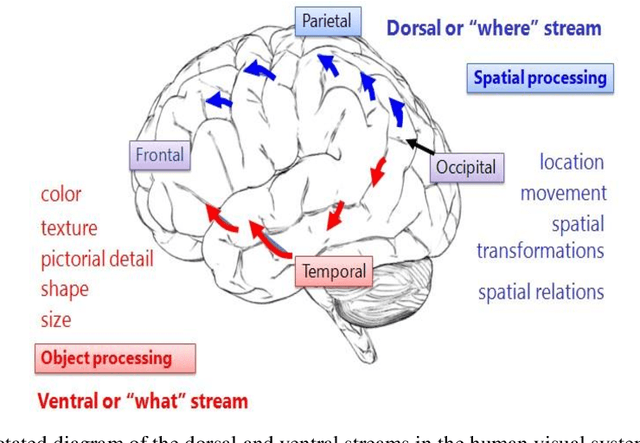

With the increased sophistication of AI techniques, the application of these systems has been expanding to ever newer fields. Increasingly, these systems are being used in modeling of human aesthetics and creativity, e.g. how humans create artworks and design products. Our lab has developed one such AI creativity deep learning system that can be used to create artworks in the form of images and videos. In this paper, we describe this system and its use in studying the human visual system and the formation of aesthetic experiences. Specifically, we show how time-based AI created media can be used to explore the nature of the dual-pathway neuro-architecture of the human visual system and how this relates to higher cognitive judgments such as aesthetic experiences that rely on these divergent information streams. We propose a theoretical framework for how the movement within percepts such as video clips, causes the engagement of reflexive attention and a subsequent focus on visual information that are primarily processed via the dorsal stream, thereby modulating aesthetic experiences that rely on information relayed via the ventral stream. We outline our recent study in support of our proposed framework, which serves as the first study that investigates the relationship between the two visual streams and aesthetic experiences.
Informing Artificial Intelligence Generative Techniques using Cognitive Theories of Human Creativity
Dec 11, 2018

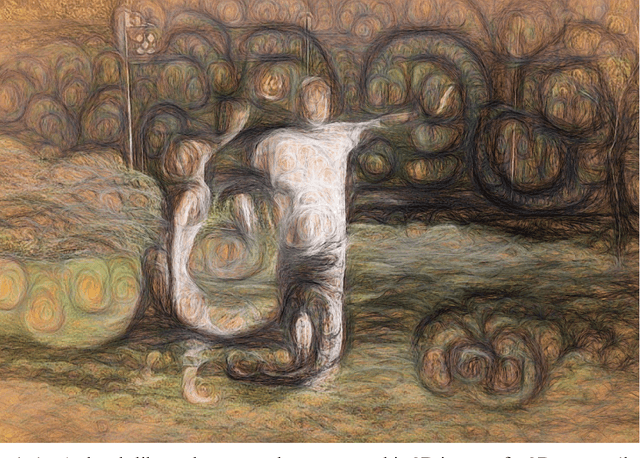

The common view that our creativity is what makes us uniquely human suggests that incorporating research on human creativity into generative deep learning techniques might be a fruitful avenue for making their outputs more compelling and human-like. Using an original synthesis of Deep Dream-based convolutional neural networks and cognitive based computational art rendering systems, we show how honing theory, intrinsic motivation, and the notion of a 'seed incident' can be implemented computationally, and demonstrate their impact on the resulting generative art. Conversely, we discuss how explorations in deep learn-ing convolutional neural net generative systems can inform our understanding of human creativity. We conclude with ideas for further cross-fertilization between AI based computational creativity and psychology of creativity.
* 18 pages; 6 figures. arXiv admin note: substantial text overlap with arXiv:1610.02478
Deep Convolutional Networks as Models of Generalization and Blending Within Visual Creativity
Oct 08, 2016
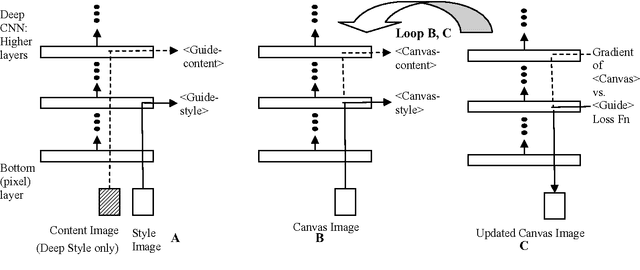


We examine two recent artificial intelligence (AI) based deep learning algorithms for visual blending in convolutional neural networks (Mordvintsev et al. 2015, Gatys et al. 2015). To investigate the potential value of these algorithms as tools for computational creativity research, we explain and schematize the essential aspects of the algorithms' operation and give visual examples of their output. We discuss the relationship of the two algorithms to human cognitive science theories of creativity such as conceptual blending theory and honing theory, and characterize the algorithms with respect to generation of novelty and aesthetic quality.
How Did Humans Become So Creative? A Computational Approach
Aug 23, 2013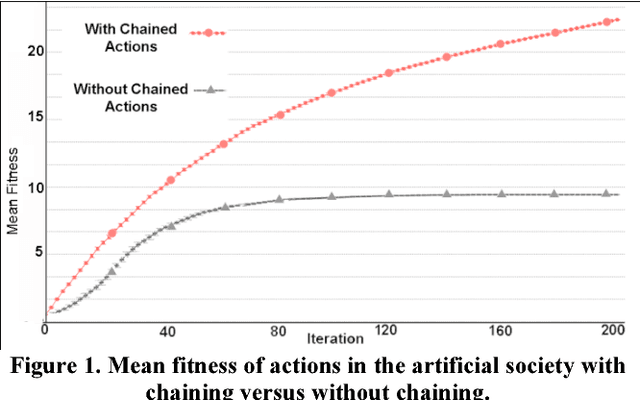
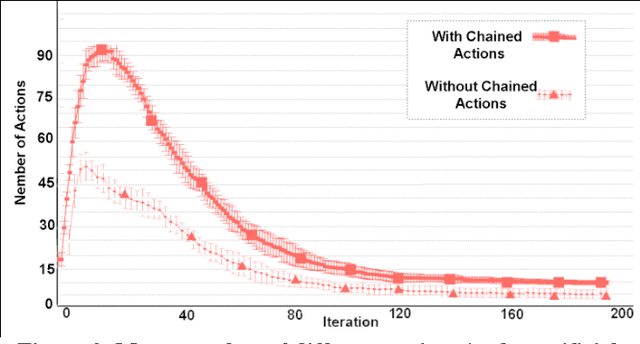


This paper summarizes efforts to computationally model two transitions in the evolution of human creativity: its origins about two million years ago, and the 'big bang' of creativity about 50,000 years ago. Using a computational model of cultural evolution in which neural network based agents evolve ideas for actions through invention and imitation, we tested the hypothesis that human creativity began with onset of the capacity for recursive recall. We compared runs in which agents were limited to single-step actions to runs in which they used recursive recall to chain simple actions into complex ones. Chaining resulted in higher diversity, open-ended novelty, no ceiling on the mean fitness of actions, and greater ability to make use of learning. Using a computational model of portrait painting, we tested the hypothesis that the explosion of creativity in the Middle/Upper Paleolithic was due to onset of con-textual focus: the capacity to shift between associative and analytic thought. This resulted in faster convergence on portraits that resembled the sitter, employed painterly techniques, and were rated as preferable. We conclude that recursive recall and contextual focus provide a computationally plausible explanation of how humans evolved the means to transform this planet.
* 8 pages
Incorporating characteristics of human creativity into an evolutionary art algorithm
Jan 09, 2010



A perceived limitation of evolutionary art and design algorithms is that they rely on human intervention; the artist selects the most aesthetically pleasing variants of one generation to produce the next. This paper discusses how computer generated art and design can become more creatively human-like with respect to both process and outcome. As an example of a step in this direction, we present an algorithm that overcomes the above limitation by employing an automatic fitness function. The goal is to evolve abstract portraits of Darwin, using our 2nd generation fitness function which rewards genomes that not just produce a likeness of Darwin but exhibit certain strategies characteristic of human artists. We note that in human creativity, change is less choosing amongst randomly generated variants and more capitalizing on the associative structure of a conceptual network to hone in on a vision. We discuss how to achieve this fluidity algorithmically.