 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoppy: Polarization-based Plug-and-Play Guidance for Enhancing Monocular Normal Estimation
Mar 29, 2026Monocular surface normal estimators trained on large-scale RGB-normal data often perform poorly in the edge cases of reflective, textureless, and dark surfaces. Polarization encodes surface orientation independently of texture and albedo, offering a physics-based complement for these cases. Existing polarization methods, however, require multi-view capture or specialized training data, limiting generalization. We introduce Poppy, a training-free framework that refines normals from any frozen RGB backbone using single-shot polarization measurements at test time. Keeping backbone weights frozen, Poppy optimizes per-pixel offsets to the input RGB and output normal along with a learned reflectance decomposition. A differentiable rendering layer converts the refined normals into polarization predictions and penalizes mismatches with the observed signal. Across seven benchmarks and three backbone architectures (diffusion, flow, and feed-forward), Poppy reduces mean angular error by 23-26% on synthetic data and 6-16% on real data. These results show that guiding learned RGB-based normal estimators with polarization cues at test time refines normals on challenging surfaces without retraining.
Generating metamers of human scene understanding
Jan 16, 2026Human vision combines low-resolution "gist" information from the visual periphery with sparse but high-resolution information from fixated locations to construct a coherent understanding of a visual scene. In this paper, we introduce MetamerGen, a tool for generating scenes that are aligned with latent human scene representations. MetamerGen is a latent diffusion model that combines peripherally obtained scene gist information with information obtained from scene-viewing fixations to generate image metamers for what humans understand after viewing a scene. Generating images from both high and low resolution (i.e. "foveated") inputs constitutes a novel image-to-image synthesis problem, which we tackle by introducing a dual-stream representation of the foveated scenes consisting of DINOv2 tokens that fuse detailed features from fixated areas with peripherally degraded features capturing scene context. To evaluate the perceptual alignment of MetamerGen generated images to latent human scene representations, we conducted a same-different behavioral experiment where participants were asked for a "same" or "different" response between the generated and the original image. With that, we identify scene generations that are indeed metamers for the latent scene representations formed by the viewers. MetamerGen is a powerful tool for understanding scene understanding. Our proof-of-concept analyses uncovered specific features at multiple levels of visual processing that contributed to human judgments. While it can generate metamers even conditioned on random fixations, we find that high-level semantic alignment most strongly predicts metamerism when the generated scenes are conditioned on viewers' own fixated regions.
GriDiT: Factorized Grid-Based Diffusion for Efficient Long Image Sequence Generation
Dec 24, 2025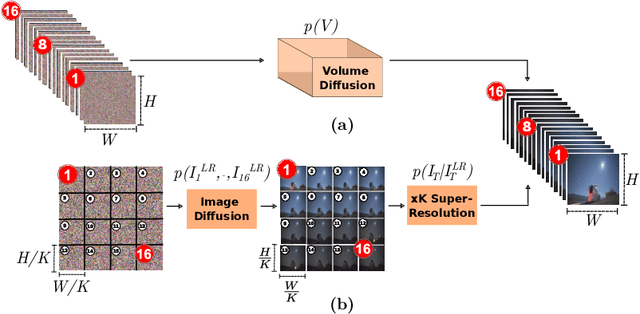
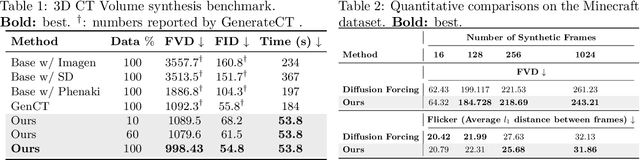
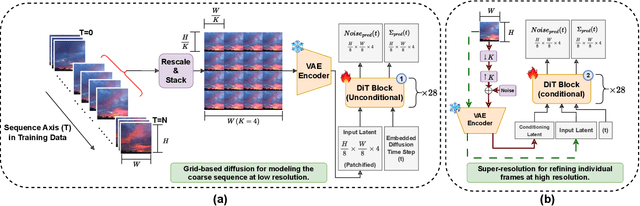
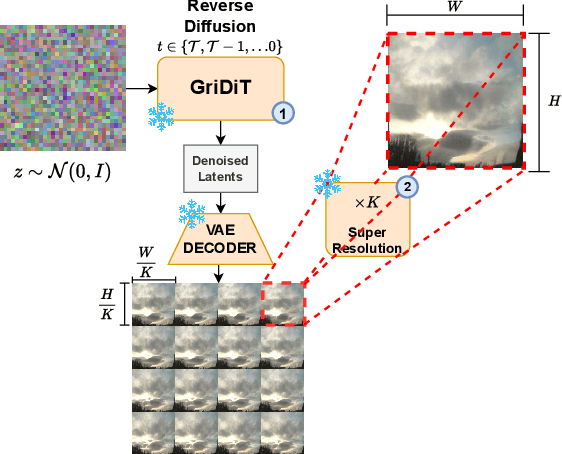
Modern deep learning methods typically treat image sequences as large tensors of sequentially stacked frames. However, is this straightforward representation ideal given the current state-of-the-art (SoTA)? In this work, we address this question in the context of generative models and aim to devise a more effective way of modeling image sequence data. Observing the inefficiencies and bottlenecks of current SoTA image sequence generation methods, we showcase that rather than working with large tensors, we can improve the generation process by factorizing it into first generating the coarse sequence at low resolution and then refining the individual frames at high resolution. We train a generative model solely on grid images comprising subsampled frames. Yet, we learn to generate image sequences, using the strong self-attention mechanism of the Diffusion Transformer (DiT) to capture correlations between frames. In effect, our formulation extends a 2D image generator to operate as a low-resolution 3D image-sequence generator without introducing any architectural modifications. Subsequently, we super-resolve each frame individually to add the sequence-independent high-resolution details. This approach offers several advantages and can overcome key limitations of the SoTA in this domain. Compared to existing image sequence generation models, our method achieves superior synthesis quality and improved coherence across sequences. It also delivers high-fidelity generation of arbitrary-length sequences and increased efficiency in inference time and training data usage. Furthermore, our straightforward formulation enables our method to generalize effectively across diverse data domains, which typically require additional priors and supervision to model in a generative context. Our method consistently outperforms SoTA in quality and inference speed (at least twice-as-fast) across datasets.
PixCell: A generative foundation model for digital histopathology images
Jun 05, 2025The digitization of histology slides has revolutionized pathology, providing massive datasets for cancer diagnosis and research. Contrastive self-supervised and vision-language models have been shown to effectively mine large pathology datasets to learn discriminative representations. On the other hand, generative models, capable of synthesizing realistic and diverse images, present a compelling solution to address unique problems in pathology that involve synthesizing images; overcoming annotated data scarcity, enabling privacy-preserving data sharing, and performing inherently generative tasks, such as virtual staining. We introduce PixCell, the first diffusion-based generative foundation model for histopathology. We train PixCell on PanCan-30M, a vast, diverse dataset derived from 69,184 H\&E-stained whole slide images covering various cancer types. We employ a progressive training strategy and a self-supervision-based conditioning that allows us to scale up training without any annotated data. PixCell generates diverse and high-quality images across multiple cancer types, which we find can be used in place of real data to train a self-supervised discriminative model. Synthetic images shared between institutions are subject to fewer regulatory barriers than would be the case with real clinical images. Furthermore, we showcase the ability to precisely control image generation using a small set of annotated images, which can be used for both data augmentation and educational purposes. Testing on a cell segmentation task, a mask-guided PixCell enables targeted data augmentation, improving downstream performance. Finally, we demonstrate PixCell's ability to use H\&E structural staining to infer results from molecular marker studies; we use this capability to infer IHC staining from H\&E images. Our trained models are publicly released to accelerate research in computational pathology.
PathSegDiff: Pathology Segmentation using Diffusion model representations
Apr 09, 2025Image segmentation is crucial in many computational pathology pipelines, including accurate disease diagnosis, subtyping, outcome, and survivability prediction. The common approach for training a segmentation model relies on a pre-trained feature extractor and a dataset of paired image and mask annotations. These are used to train a lightweight prediction model that translates features into per-pixel classes. The choice of the feature extractor is central to the performance of the final segmentation model, and recent literature has focused on finding tasks to pre-train the feature extractor. In this paper, we propose PathSegDiff, a novel approach for histopathology image segmentation that leverages Latent Diffusion Models (LDMs) as pre-trained featured extractors. Our method utilizes a pathology-specific LDM, guided by a self-supervised encoder, to extract rich semantic information from H\&E stained histopathology images. We employ a simple, fully convolutional network to process the features extracted from the LDM and generate segmentation masks. Our experiments demonstrate significant improvements over traditional methods on the BCSS and GlaS datasets, highlighting the effectiveness of domain-specific diffusion pre-training in capturing intricate tissue structures and enhancing segmentation accuracy in histopathology images.
Pathology Image Compression with Pre-trained Autoencoders
Mar 14, 2025The growing volume of high-resolution Whole Slide Images in digital histopathology poses significant storage, transmission, and computational efficiency challenges. Standard compression methods, such as JPEG, reduce file sizes but often fail to preserve fine-grained phenotypic details critical for downstream tasks. In this work, we repurpose autoencoders (AEs) designed for Latent Diffusion Models as an efficient learned compression framework for pathology images. We systematically benchmark three AE models with varying compression levels and evaluate their reconstruction ability using pathology foundation models. We introduce a fine-tuning strategy to further enhance reconstruction fidelity that optimizes a pathology-specific learned perceptual metric. We validate our approach on downstream tasks, including segmentation, patch classification, and multiple instance learning, showing that replacing images with AE-compressed reconstructions leads to minimal performance degradation. Additionally, we propose a K-means clustering-based quantization method for AE latents, improving storage efficiency while maintaining reconstruction quality. We provide the weights of the fine-tuned autoencoders at https://huggingface.co/collections/StonyBrook-CVLab/pathology-fine-tuned-aes-67d45f223a659ff2e3402dd0.
Gen-SIS: Generative Self-augmentation Improves Self-supervised Learning
Dec 02, 2024



Self-supervised learning (SSL) methods have emerged as strong visual representation learners by training an image encoder to maximize similarity between features of different views of the same image. To perform this view-invariance task, current SSL algorithms rely on hand-crafted augmentations such as random cropping and color jittering to create multiple views of an image. Recently, generative diffusion models have been shown to improve SSL by providing a wider range of data augmentations. However, these diffusion models require pre-training on large-scale image-text datasets, which might not be available for many specialized domains like histopathology. In this work, we introduce Gen-SIS, a diffusion-based augmentation technique trained exclusively on unlabeled image data, eliminating any reliance on external sources of supervision such as text captions. We first train an initial SSL encoder on a dataset using only hand-crafted augmentations. We then train a diffusion model conditioned on embeddings from that SSL encoder. Following training, given an embedding of the source image, this diffusion model can synthesize its diverse views. We show that these `self-augmentations', i.e. generative augmentations based on the vanilla SSL encoder embeddings, facilitate the training of a stronger SSL encoder. Furthermore, based on the ability to interpolate between images in the encoder latent space, we introduce the novel pretext task of disentangling the two source images of an interpolated synthetic image. We validate Gen-SIS's effectiveness by demonstrating performance improvements across various downstream tasks in both natural images, which are generally object-centric, as well as digital histopathology images, which are typically context-based.
ZoomLDM: Latent Diffusion Model for multi-scale image generation
Nov 25, 2024Diffusion models have revolutionized image generation, yet several challenges restrict their application to large-image domains, such as digital pathology and satellite imagery. Given that it is infeasible to directly train a model on 'whole' images from domains with potential gigapixel sizes, diffusion-based generative methods have focused on synthesizing small, fixed-size patches extracted from these images. However, generating small patches has limited applicability since patch-based models fail to capture the global structures and wider context of large images, which can be crucial for synthesizing (semantically) accurate samples. In this paper, to overcome this limitation, we present ZoomLDM, a diffusion model tailored for generating images across multiple scales. Central to our approach is a novel magnification-aware conditioning mechanism that utilizes self-supervised learning (SSL) embeddings and allows the diffusion model to synthesize images at different 'zoom' levels, i.e., fixed-size patches extracted from large images at varying scales. ZoomLDM achieves state-of-the-art image generation quality across all scales, excelling particularly in the data-scarce setting of generating thumbnails of entire large images. The multi-scale nature of ZoomLDM unlocks additional capabilities in large image generation, enabling computationally tractable and globally coherent image synthesis up to $4096 \times 4096$ pixels and $4\times$ super-resolution. Additionally, multi-scale features extracted from ZoomLDM are highly effective in multiple instance learning experiments. We provide high-resolution examples of the generated images on our website https://histodiffusion.github.io/docs/publications/zoomldm/.
Fast constrained sampling in pre-trained diffusion models
Oct 24, 2024



Diffusion models have dominated the field of large, generative image models, with the prime examples of Stable Diffusion and DALL-E 3 being widely adopted. These models have been trained to perform text-conditioned generation on vast numbers of image-caption pairs and as a byproduct, have acquired general knowledge about natural image statistics. However, when confronted with the task of constrained sampling, e.g. generating the right half of an image conditioned on the known left half, applying these models is a delicate and slow process, with previously proposed algorithms relying on expensive iterative operations that are usually orders of magnitude slower than text-based inference. This is counter-intuitive, as image-conditioned generation should rely less on the difficult-to-learn semantic knowledge that links captions and imagery, and should instead be achievable by lower-level correlations among image pixels. In practice, inverse models are trained or tuned separately for each inverse problem, e.g. by providing parts of images during training as an additional condition, to allow their application in realistic settings. However, we argue that this is not necessary and propose an algorithm for fast-constrained sampling in large pre-trained diffusion models (Stable Diffusion) that requires no expensive backpropagation operations through the model and produces results comparable even to the state-of-the-art \emph{tuned} models. Our method is based on a novel optimization perspective to sampling under constraints and employs a numerical approximation to the expensive gradients, previously computed using backpropagation, incurring significant speed-ups.
$\infty$-Brush: Controllable Large Image Synthesis with Diffusion Models in Infinite Dimensions
Jul 20, 2024



Synthesizing high-resolution images from intricate, domain-specific information remains a significant challenge in generative modeling, particularly for applications in large-image domains such as digital histopathology and remote sensing. Existing methods face critical limitations: conditional diffusion models in pixel or latent space cannot exceed the resolution on which they were trained without losing fidelity, and computational demands increase significantly for larger image sizes. Patch-based methods offer computational efficiency but fail to capture long-range spatial relationships due to their overreliance on local information. In this paper, we introduce a novel conditional diffusion model in infinite dimensions, $\infty$-Brush for controllable large image synthesis. We propose a cross-attention neural operator to enable conditioning in function space. Our model overcomes the constraints of traditional finite-dimensional diffusion models and patch-based methods, offering scalability and superior capability in preserving global image structures while maintaining fine details. To our best knowledge, $\infty$-Brush is the first conditional diffusion model in function space, that can controllably synthesize images at arbitrary resolutions of up to $4096\times4096$ pixels. The code is available at https://github.com/cvlab-stonybrook/infinity-brush.